
 Machine learning has the promise to improve our world, and in many ways it already has. However, research and lived experiences continue to show this technology…
Machine learning has the promise to improve our world, and in many ways it already has. However, research and lived experiences continue to show this technology…
Machine learning has the promise to improve our world, and in many ways it already has. However, research and lived experiences continue to show this technology has risks. Capabilities that used to be restricted to science fiction and academia are increasingly available to the public. The responsible use and development of AI requires categorizing, assessing, and mitigating enumerated risks where practical. This is true from a pure AI standpoint but also from a standard information security perspective.
Until standards are in place and mature testing has taken hold, organizations are using red teams to explore and enumerate the immediate risks presented by AI. This post introduces the NVIDIA AI red team philosophy and the general framing of ML systems.
Assessment foundations
Our AI red team is a cross-functional team made up of offensive security professionals and data scientists. We use our combined skills to assess our ML systems to identify and help mitigate any risks from the perspective of information security.
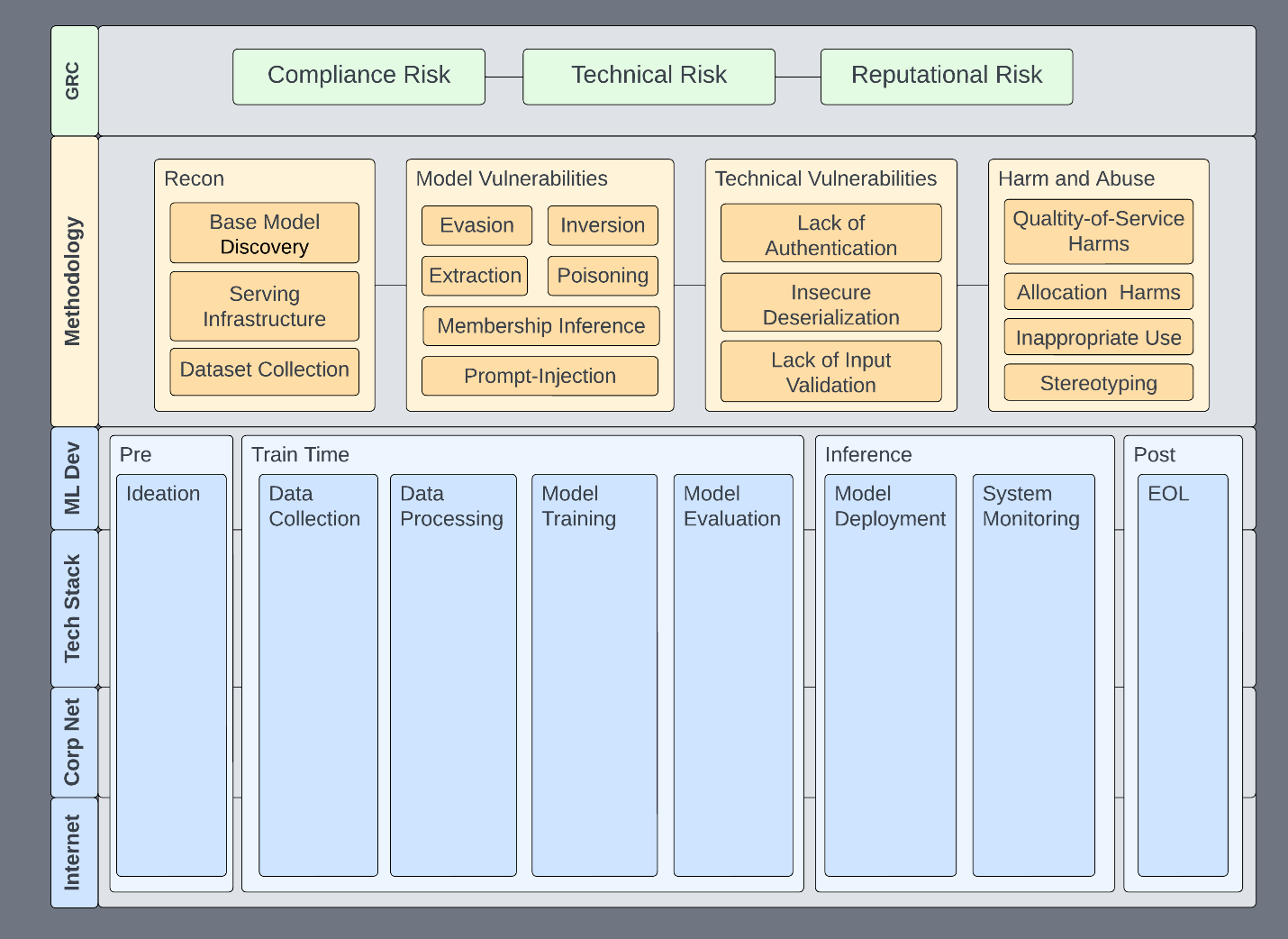
Information security has a lot of useful paradigms, tools, and network access that enable us to accelerate responsible use in all areas. This framework is our foundation and directs assessment efforts toward a standard within the organization. We use it to guide assessments (Figure 1) toward the following goals:
- The risks that our organization cares about and wants to eliminate are addressed.
- Required assessment activities and the various tactics, techniques, and procedures (TTPs) are clearly defined. TTPs can be added without changing existing structures.
- The systems and technologies in scope for our assessments are clearly defined. This helps us remain focused on ML systems and not stray into other areas.
- All efforts live within a single framework that stakeholders can reference and immediately get a broad overview of what ML security looks like.
This helps us set expectations for what an assessment looks like, what systems we could potentially be affecting, and the risks that we address. This framework is not specific to red teaming, but some of these properties are the basis for a functional ML security program, of which red teaming is a small part.
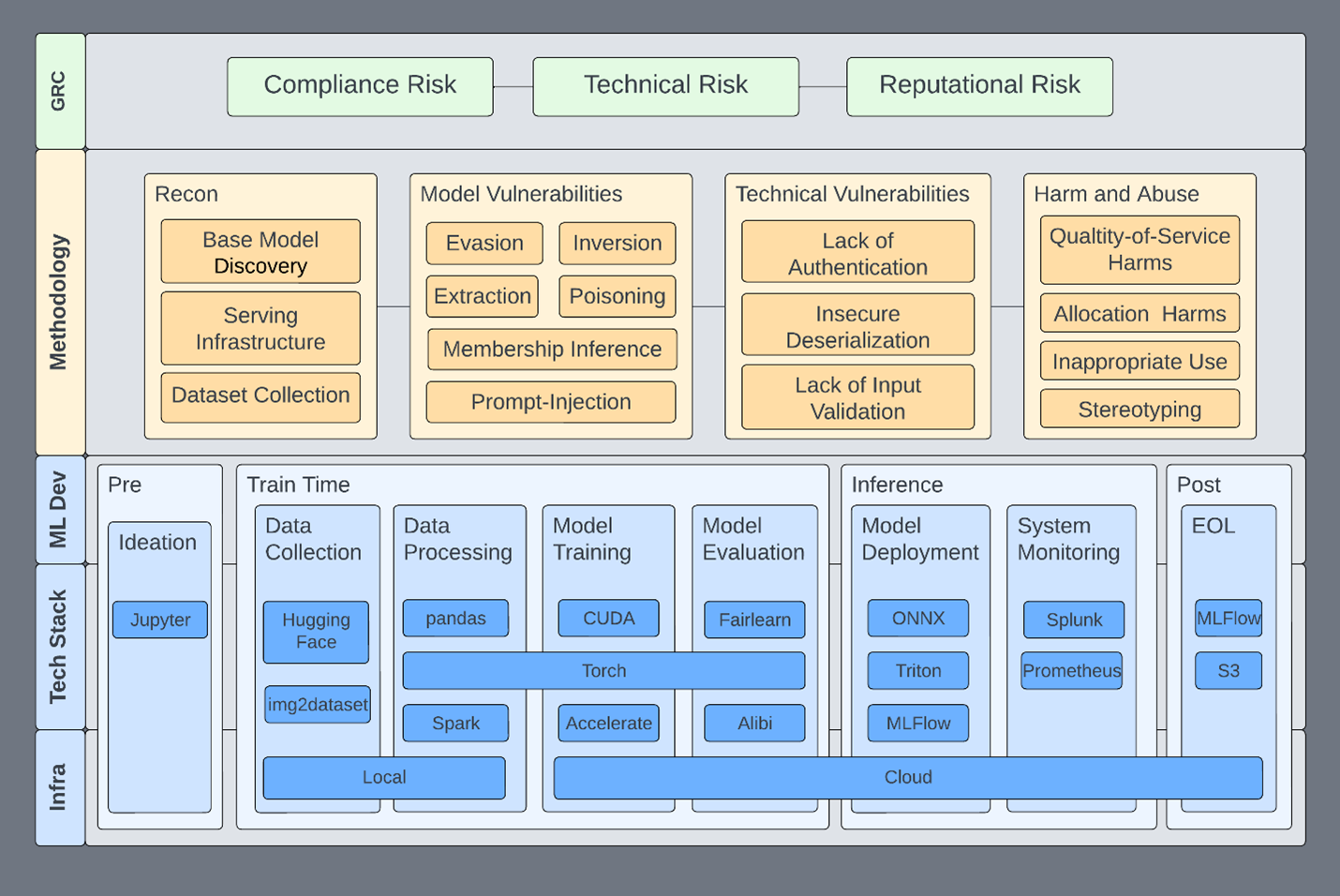
The specific technologies—and which features go where—is not necessarily important. The important part is that there is a place for everything to go, whether you’re red teaming, vulnerability scanning, or doing any sort of assessment of an ML system.
This framework enables us to address specific issues in specific parts of the ML pipeline, infrastructure, or technologies. It becomes a place to communicate risk about issues to affected systems: up and down the stack and informing policy and technology.
Any given subsection can be isolated, expanded, and described within the context of the whole system. Here are some examples:
- Evasion is expanded to include specific algorithms or TTPs that would be relevant for an assessment of a particular model type. Red teams can point to exactly the infrastructure components that are affected.
- Technical vulnerabilities can affect any level of infrastructure or just a specific application. They can be dealt with in the context of their function and risk-rated accordingly.
- Harm-and-abuse scenarios that are foreign to many information security practitioners are not only included but are integrated. In this way, we motivate technical teams to consider harm-and-abuse scenarios as they’re assessing ML systems. Or, they can provide ethics teams access to tools and expertise.
- Requirements handed down can be integrated more quickly, both old and new.
There are many benefits to a framework like this. Consider how a disclosure process can benefit from this composed view. The core building blocks are governance, risk, and compliance (GRC) and ML development.
Governance, risk, and compliance
As in many organizations, GRC is the top level of information security efforts, ensuring that business security requirements are enumerated, communicated, and implemented. As an AI red team under the banner of information security, here are the high-level risks we’re interested in surfacing:
- Technical risk: ML systems or processes are compromised as the result of a technical vulnerability or shortcoming.
- Reputational risk: Model performance or behavior reflects poorly on the organization. In this new paradigm, this could include releasing a model that has a broad societal impact.
- Compliance risk: The ML system is out of compliance, leading to fines or reduced market competitiveness, much like PCI or GDPR.
These high-level risk categories are present in all information systems, including ML systems. Think of these categories like individually colored lenses on a light. Using each colored lens provides a different perspective of risks with respect to the underlying system, and sometimes the risks can be additive. For example, a technical vulnerability that leads to a breach can cause reputational damage. Depending on where the breach occurred, compliance could also require breach notification, fines, and so on.
Even if ML didn’t come with its own vulnerabilities, it is still developed, stored, and deployed on an infrastructure that is subject to standards set by GRC efforts. All assets within an organization are subject to being compliant with GRC standards. And if they aren’t, it’s ideally only because management filed and approved an exception.
ML development
The bottom of the stack is the ML development lifecycle, as it is the activity that GRC wants insight into. We generally consider an ML system as any system that involves ML, inclusive of the processes and systems by which models are built. Components of an ML system might include a web server that hosts a model for inference, a data lake holding training data, or a system that uses the model output to make a decision.
Development pipelines span multiple and sometimes incongruent systems. Each phase of the lifecycle is both unique in function and dependent on the prior phase. Because of this, ML systems tend to be tightly integrated, and the compromise of any one part of the pipeline likely affects other upstream or downstream development phases.
There are more detailed MLOps pipelines, but the canonical example is sufficient to successfully group the supporting tools and services with their lifecycle phase (Table 1).
| Phase | Description | Model state |
| Ideation | Discussions, meetings, and intention toward requirements. | Pre-development |
| Data collection | Models require data to be trained. Data is usually collected from both public and private sources with a specific model in mind. This is an ongoing process and data continues to be collected from these sources. | Train |
| Data processing | The collected data is processed in any number of ways before being introduced to an algorithm for both training and inference. | Train |
| Model training | The processed data is then ingested by an algorithm and a model is trained. | Train |
| Model evaluation | After a model is trained, it is validated to ensure accuracy, robustness, interpretability, or any number of other metrics. | Train |
| Model deployment | The trained model is embedded in a system for use in production. Machine learning is deployed in a wide variety of ways: inside autonomous vehicles, on a web API, or in client-side applications. | Inference |
| System monitoring | After the model has been deployed, the system is monitored. This includes aspects of the system that may not relate to the ML model directly. | Inference |
| End-of-life | Data shifts, business requirement changes, and innovations require that systems are discontinued properly. | Post-development |
This high-level structure enables risks to be put into the context of the whole ML system and provides some natural security boundaries to work with. For example, implementing privilege tiering between phases potentially prevents an incident from spanning an entire pipeline or multiple pipelines. Compromised or not, the purpose of the pipeline is to deploy models for use.
Methodology and use cases
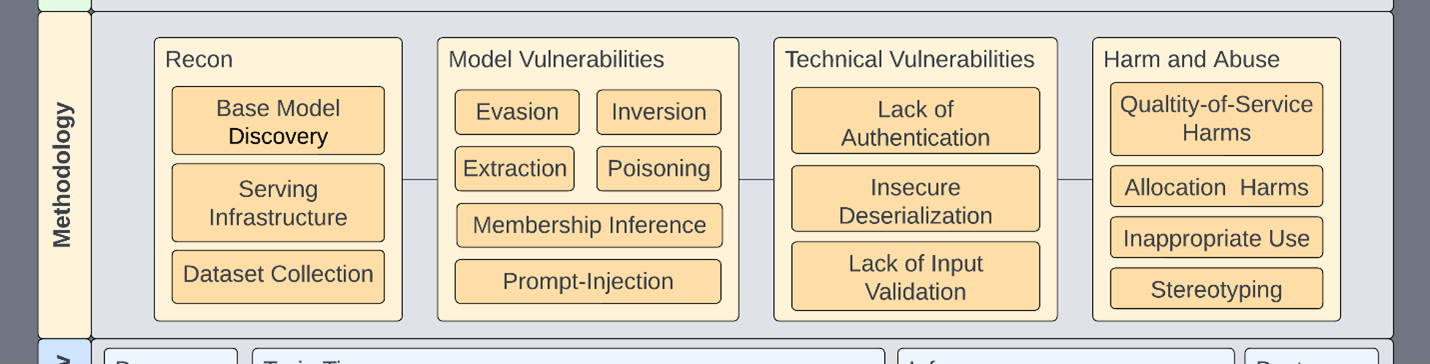
This methodology attempts to cover all primary concerns related to ML systems. In our framework, any given phase can be handed to an appropriately skilled team:
- Existing offensive security teams are likely equipped to perform reconnaissance and explore technical vulnerabilities.
- Responsible AI teams are equipped to address harm-and-abuse scenarios.
- ML researchers are equipped to handle model vulnerabilities.
Our AI red team prefers to aggregate those skill sets on the same or adjacent teams. The increased learning and effectiveness are undeniable: Traditional red team members are part of academic papers and data scientists are given CVEs.
| Assessment phase | Description |
| Reconnaissance | This phase describes classic reconnaissance techniques found in MITRE ATT&CK or MITRE ATLAS |
| Technical vulnerabilities | All the traditional vulnerabilities you know and love. |
| Model vulnerabilities | These vulnerabilities typically come out of research spaces and cover the following: extraction, evasion, inversion, membership inference, and poisoning. |
| Harm and abuse | Models are often trained and distributed such that they can be abused for malicious or other harmful tasks. Models can also be biased intentionally or unintentionally. Or, they don’t accurately reflect the environments in which they’re deployed. |
Regardless of which team performs which assessment activity, it all remains within the same framework and feeds into the larger assessment effort. Here are some specific use cases:
- Address new prompt-injection techniques
- Examine and define security boundaries
- Use privilege tiering
- Conduct tabletop exercises
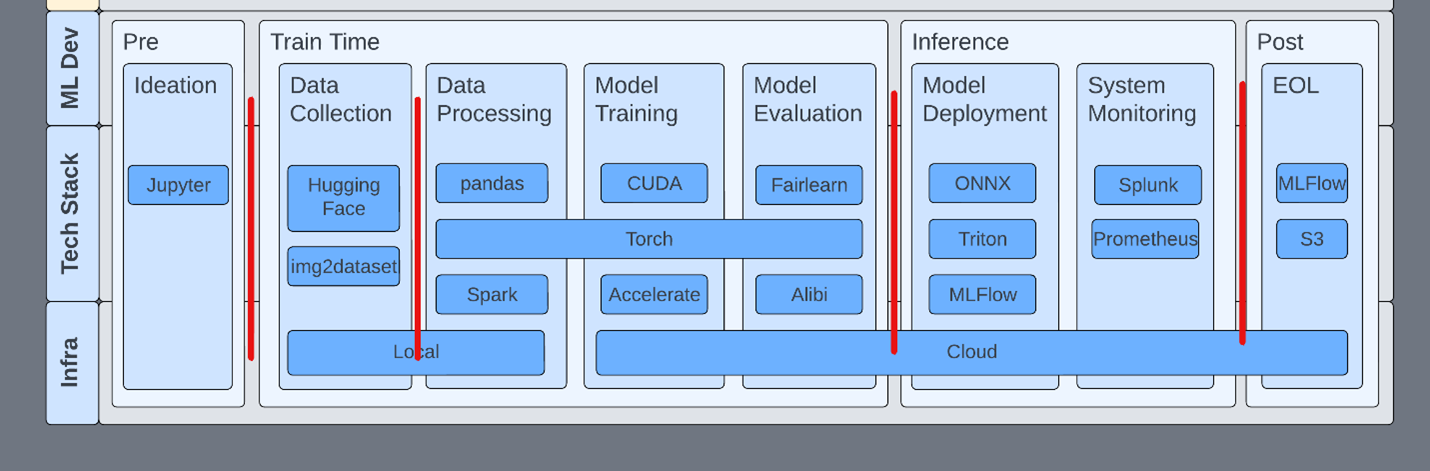
Address new prompt-injection techniques
In this scenario, outputs from large language models (LLMs) are clumsily put into Python exec or eval statements. Already, you can see how a composed view helps address multiple aspects, as input validation is a layer of defense against prompt injection.
Examine and define security boundaries
Compartmentalizing each phase with security controls reduces attack surfaces and increases visibility into ML systems. An example control might be that pickles (yes, that torch file has pickles) are blocked outside of development environments, and production models must be converted to something less prone to code execution, like ONNX. This enables R&D to continue using pickles during development but prevents them from being used in sensitive environments.
While not using pickles at all would be ideal, security is often about compromises. Organizations should seek to add mitigating controls where the complete avoidance of issues is not practical.
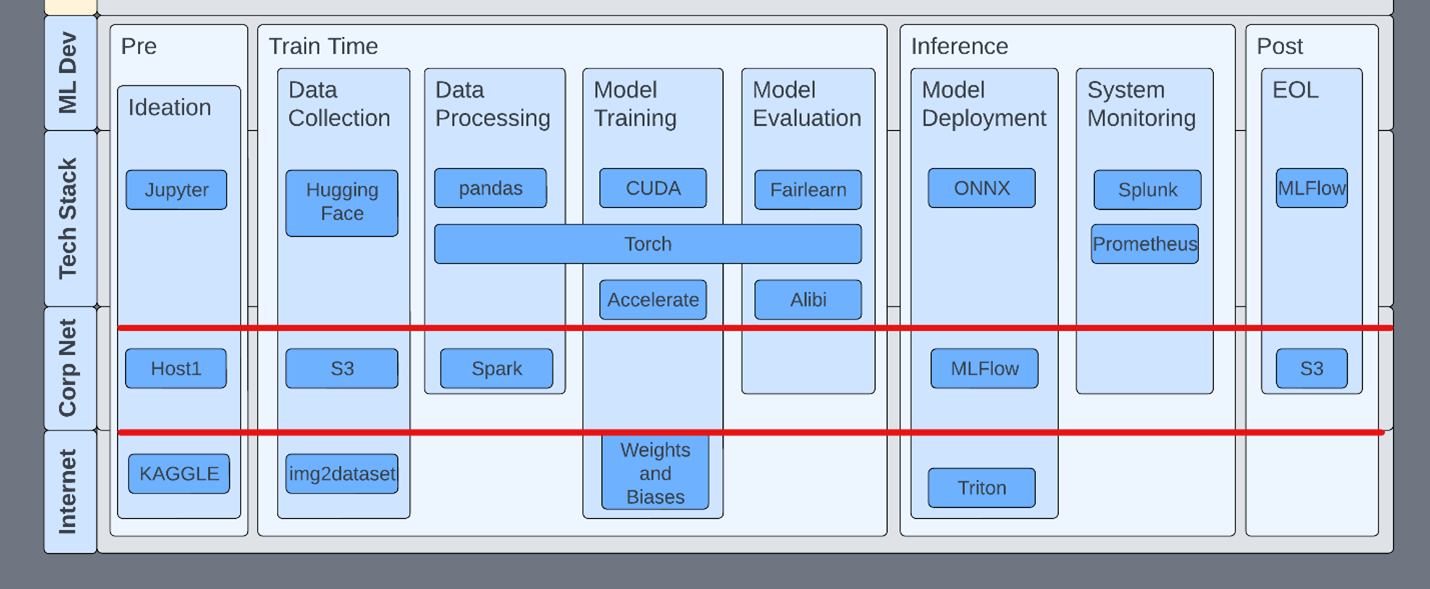
Use privilege tiering
Inside a development flow, it’s important to understand the tools and their properties at each stage of the lifecycle. For example, MLFlow has no authentication by default. Starting an MLFlow server knowingly or unknowingly opens that host for exploitation through deserialization.
In another example, Jupyter servers are often started with arguments that remove authentication and TensorBoard has no authentication. This isn’t to say that TensorBoard should have authentication. Teams should just be aware of this fact and ensure that the appropriate network security rules are in place.
Consider the scope of all technologies within the development pipeline. This includes easy things like two-factor authentication on ML services like HuggingFace.
Conduct tabletop exercises
Consider how you might empty the ML development process and only consider your technologies, where they live, and the TTPs that would apply. Work your way up and down the stack. Here are some quick scenarios to think through:
- A Flask server was deployed with debug privileges enabled and exposed to the Internet. It was hosting a model that provided inference for HIPAA-protected data.
- PII was downloaded as part of a dataset and several models have been trained on it. Now, a customer is asking about it.
- A public bucket with several ML artifacts, including production models, was left open to the public. It has been improperly accessed and files have been changed.
- Someone can consistently bypass content filters despite the models being accurate and up-to-date.
- A model isn’t performing as well as it should in certain geographic regions.
- Someone is scanning the internal network from an inference server used to host an LLM.
- System monitoring services have detected someone sending a well-known dataset against the inference service.
These are maybe a little contrived but spend some time putting various technologies in the right buckets and then working your way up through the methodology.
- Does it sound like a technical vulnerability caused the issue?
- Does this affect any ML processes?
- Who is responsible for the models? Would they know if changes have been made?
These are all questions that must be answered. Some of these scenarios immediately seem like they fit into one section of the methodology. However, on closer inspection, you’ll find most of them span multiple areas.
Conclusion
This framework already provides you with several familiar paradigms that your organizations can start to strategize around. With a principled methodology, you can create foundations from which to build continuous security improvement, reaching toward standards and maturity from product design to production deployment. We invite you to adopt our methodology and adapt it to your own purposes.
Our methodology does not prescribe behaviors or processes. Instead, it aims to organize them. Your organization may already have mature processes to discover, manage, and mitigate risks associated with traditional applications. We hope that this framework and methodology similarly prepare you to identify and mitigate new risks from the ML components deployed in your organization.
If you have any questions, please comment below or contact [email protected].