
 Wireless technology has evolved rapidly and the 5G deployments have made good progress around the world. Up until recently, wireless RAN was deployed using…
Wireless technology has evolved rapidly and the 5G deployments have made good progress around the world. Up until recently, wireless RAN was deployed using…
Wireless technology has evolved rapidly and the 5G deployments have made good progress around the world. Up until recently, wireless RAN was deployed using closed-box appliance solutions by traditional RAN vendors. This closed-box approach is not scalable, underuses the infrastructure, and does not deliver optimal RAN TCO. It has many shortcomings.
We have come to realize that such closed-box solutions are not scalable and effective for the 5G era.
As a result, the telecoms industry has come together to promote and build virtualized and cloud-native RAN solutions on commercial-off-the-shelf (COTS) hardware platforms with open and standard interfaces. This enables a larger ecosystem and flexible solutions on general-purpose server platforms, leveraging the virtues of virtualization and cloud-native technologies.
There are many positives of such an approach: lower cost, larger ecosystem and vendor choices, faster innovation cycles, automation, and scalability. However, one area of concern is that the open RAN architecture may result in a larger attack surface and may cause new security risks.
As a technology leader in accelerated computing platforms, NVIDIA has been working closely with the standards community (3GPP and O-RAN Alliance), partners, and customers to define and deliver a robust set of security capabilities for vRAN platforms.
Our vision is to drive faster innovation at the confluence of cloud, AI, and 5G to enable the applications of tomorrow. We will ensure that the platforms at the foundation of such innovations are built inherently with the utmost security principles in mind.
Tackling the security challenges of open RAN architecture
The introduction of new standard interfaces in open RAN architecture, along with the decoupling of hardware and software, expands the threat surface of RAN systems. Some examples:
- New open interfaces for disaggregated RAN, such as Open Fronthaul (OFH), A1, or E2.
- Near-real-time RIC and vendor provided xApps that could exploit the RAN system.
- Decoupling of hardware from software increases threats to the trust chain.
- Management interfaces such as OFH M-plane, O1, or O2 may induce new vulnerabilities.
The strict latency requirements on the RAN must be considered when you implement security features, such as accelerated cryptographic operations, on the OFH interface. The increased reliance on open-source software also increases the open RAN dependence on secure development practices within open-source communities. Finally, the dramatic growth in the number of IoT devices requires all RAN deployments to protect themselves against the increasing likelihood of attacks by compromised devices.
CSRIC Council
To promote the security, reliability, and resiliency of the United States’ communications systems, the Federal Communications Commission (FCC) established the Communications Security, Reliability, and Interoperability (CSRIC) Council VIII.
The council published a detailed report on the challenges to the development of secure open RAN technology, and a series of recommendations for the industry on how to overcome them. The report also recommends that the open RAN industry adopts security requirements standardized by O-RAN Alliance Working Group 11. The next sections discuss these recommendations and requirements.
CSRIC Council architectural recommendations
The key set of security-centric architectural recommendations for the open RAN industry stemming from FCC CSRIC VIII’s report are as follows:
- Digital signing of production software should apply to open RAN workloads, including network functions and applications.
- Ethernet-based fronthaul networks should be segmented to isolate fronthaul traffic from other traffic flows.
- Port-based authentication should be used to enable the authorization of network elements attached to the FH network.
- Secure protocols providing mutual authentication should be used when deploying radio units (RUs) with Ethernet-based fronthaul in US production networks.
- IEEE 802.1X port-based network access control should be implemented for all network elements that connect to the FH network deployed in hybrid mode.
- Open RAN implementations should be based on the principles of zero trust architecture (ZTA).
- Open RAN software should be deployed on secure server hardware. The credentials and keys used by the open RAN software should be encrypted and stored securely.
- Open RAN architectures implement defenses to prevent adversarial machine learning (AML) attacks. Industry should work within the O-RAN Alliance to drive security specifications that mitigate AML attacks.
- MNO should use secure boot based on hardware root of trust (RoT), with credentials securely stored (for example, in a hardware security module (HSM)), and software signing to establish an end-to-end chain of trust.
O-RAN WG11 defines robust security requirements
The O-RAN Alliance Security Working Group (WG11) is responsible for security guidelines that span across the entire O-RAN architecture. The security analysis and specifications are being developed in close coordination with other O-RAN Working Groups, as well as regulators, and standards development organizations. It complements the security recommendations published by FCC CSRIC VIII discussed earlier.
The fundamental security principles (SP) of open RAN systems, as per the O-RAN WG11 specification, are based on 16 pillars (Table 1).
| Security principles | Requirements | NVIDIA features for O-RAN WG11 support |
| 1. SP-AUTH: Mutual authentication | Detect fake base stations and unauthorized users or applications. | Supports access lists and access control list (ACL) based filtering as well as per-port authentication. |
| 2. SP-ACC: Access control | Forbid unauthorized access, anytime and anywhere. | Supports access list and ACL-based filtering. |
| 3. SP-CRYPTO: Secure cryptographic, key management, and PKI (public key infrastructure) | · Advanced cryptographic schemes and protocols · Secure key management and PKI. |
Supports IPSEC/TLS and cryptographic protocols for secure handshaking. |
| 4. SP-TCOMM: Trusted communication | Integrity, confidentiality, availability, authenticity, and replay protection in transit. | Supports timestamps and encapsulation to protect data in flight. |
| 5. SP-SS: Secure storage | Integrity, confidentiality, availability protection at rest. | Supports data-at-rest encryption and isolation from the host. |
| 6. SP-SB: Secure boot and self-configuration | · Secure boot process · Signature verification · Self-configuration |
Support secure boot and root of trust for verification. |
| 7. SP-UPDT: Secure update | Secure update management process for software update or new software integration. | Supports root of trust (RoT) and local secured BMC. |
| 8. SP-RECO: Recoverability & backup | Recover and reset under malicious attack (for example, denial of service or DoS). | Supports secure boot from a trusted source and isolation to contain DDoS. |
| 9. SP-OPNS: Security management of risks in open-source components | · Software bill of materials (SBOM) · Security analysis (audit, vulnerability scans, and so on) |
Supported by the partner ecosystem. |
| 10. SP-ASSU: Security assurance | · Risk assessment · Secure code review · Penetration testing |
Supported by the partner ecosystem. |
| 11. SP-PRV: Privacy | Data privacy, identity privacy, and personal information privacy of end users | Supports Isolation and tagging as well as encryption and encapsulation. |
| 12. SP-SLC: Continuous security development, testing, logging, monitoring, and vulnerability handling | · Continuous integration and continuous development (CI/CD) · Software security auditing · Security event logging and analysis in real time |
Supported by the partner ecosystem. |
| 13. SP-ISO: Robust isolation | Intra-domain host isolation. | Supports complete isolation from host. |
| 14. SP-PHY: Physical security | Physically secure environment for the following: -Sensitive data storage -Sensitive functions execution -Execution of boot and update processes. |
Has hardened and ruggedized versions. |
| 15. SP-CLD: Secure cloud computing and virtualization | Trust in the end-to-end stack from hardware and firmware to virtualized software. | Supported by the partner ecosystem. |
| 16. SP-ROB: Robustness | Robustness of software and hardware resources | Supports as part of our software development, validation, QA, and release practices. |
Security is built into NVIDIA platforms
A key NVIDIA goal is to provide robust security capabilities that span all aspects of security:
- Zero-trust platform security for data in execution on the platform.
- Network security to protect all data traversing across the air interface, fronthaul, and backhaul.
- Storage security for all data stored on the platform and protection in all management interfaces.
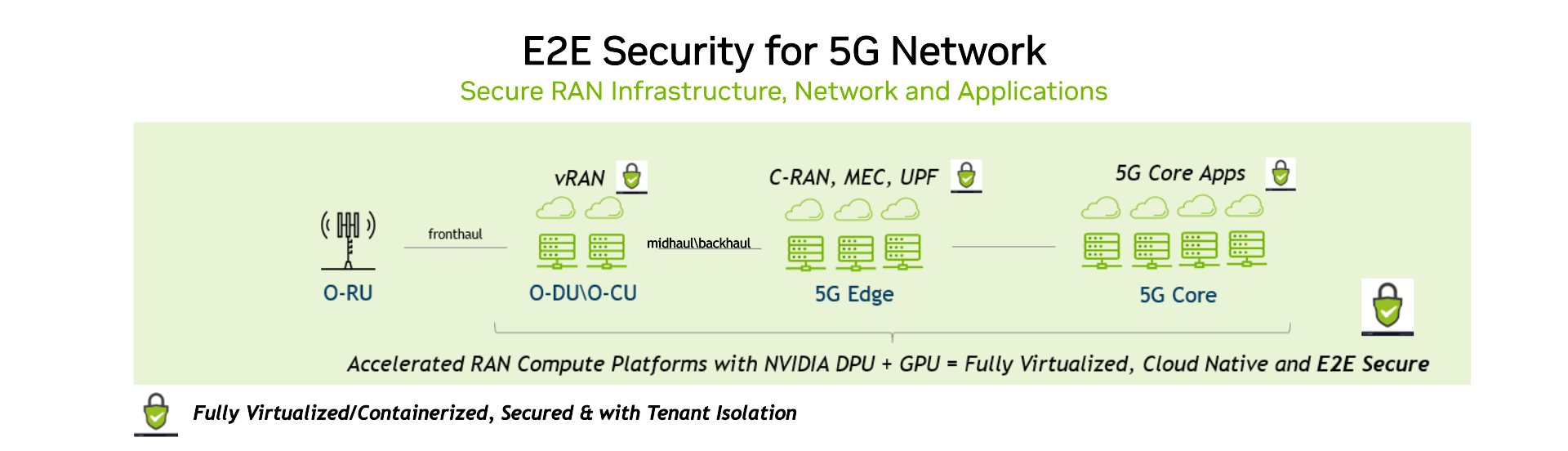
| Fronthaul | gNB (DU/CU), CRAN | Transport (midhaul/backhaul) | 5G Edge/Core |
|
|
|
|
| O&M | |||
|
Kubernetes security |
|||
| Multi-tenancy/AI | |||
|
MIG (Multi-Instance GPU): Workload isolation, guaranteed latency, and performance |
|||
To achieve this, we rely on the industry’s best security practices. NVIDIA ConnectX SmartNICs and NVIDIA BlueField data processing units (DPUs) were developed with far-edge, near-edge, and cloud security in mind. They implement all the requirements necessary for the edge and cloud providers and security vendors to shape their solutions based on NVIDIA platform features.
The ConnectX SmartNIC includes engines that offload and support MACSEC, IPSEC (as well as other encryption-based solutions), TLS, rule-based filtering, and precision time-stamping all at line-rate speeds.
The DPU adds more to the list with a complete isolated platform (server in a server), which includes:
- Secure BMC
- Secure boot
- Root of trust
- Deep packet inspection (DPI)
- Additional engines for custom crypto operations and data plane pipeline processing
These features enable you to deploy a network that is encrypted, secured, and completely isolated from the hosts. The DPU works to create a secure cloudRAN architecture while also providing direct connection to the GPU and providing the post-screened packets while not involving the host.
We have implemented O-RAN WG11 requirements in our hardware and software platforms, with NVIDIA Aerial 5G vRAN running on converged accelerators consisting of the Bluefield DPU and NVIDIA A100 GPU. The NVIDIA Aerial software implements a full inline offload of RAN Layer 1 with key security capabilities as outlined.
Summary
At NVIDIA, security is top of mind as we transform and virtualize the RAN with open and standards-based architecture. NVIDIA also supports key security capabilities for 5G transport network, 5G Core, orchestration and management layers, and edge AI applications.
When planning your 5G security for open RAN or vRAN, speak to our experts and consider using NVIDIA architectures.
 Rapid digital transformation has led to an explosion of sensitive data being generated across the enterprise. That data has to be stored and processed in data…
Rapid digital transformation has led to an explosion of sensitive data being generated across the enterprise. That data has to be stored and processed in data…
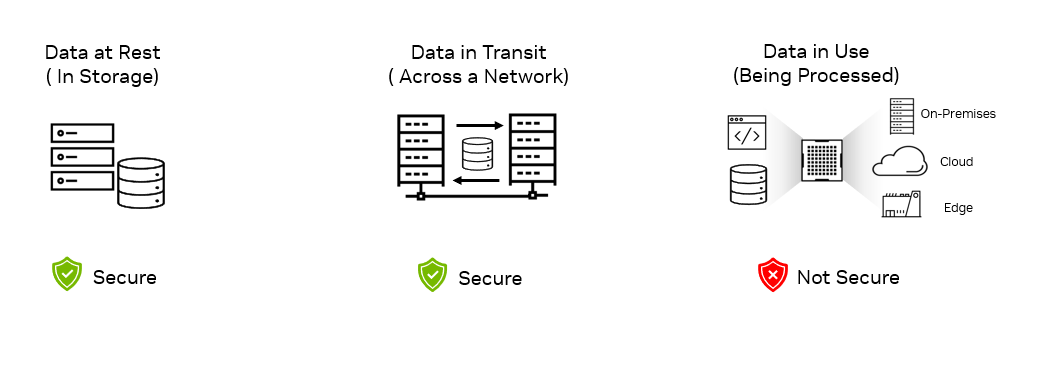
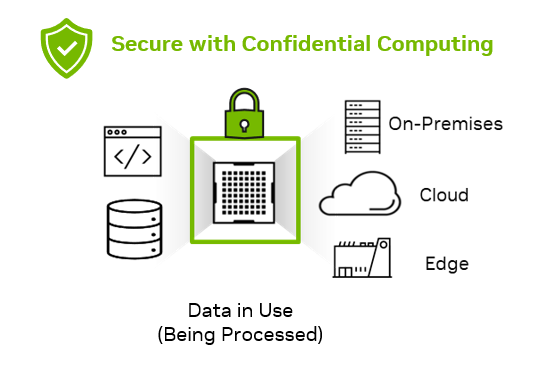
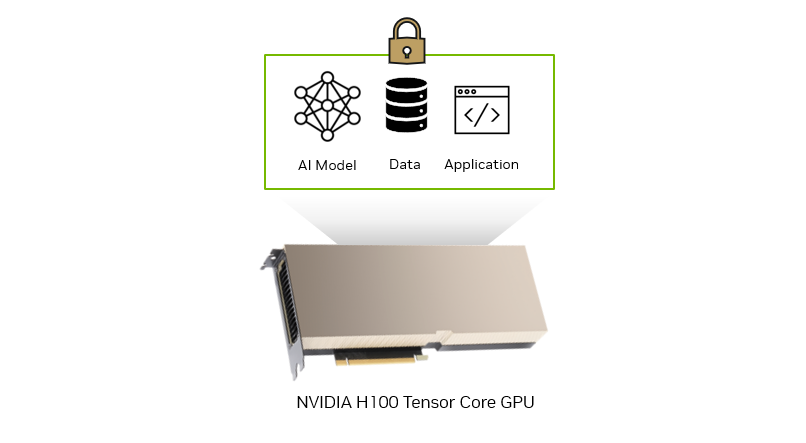
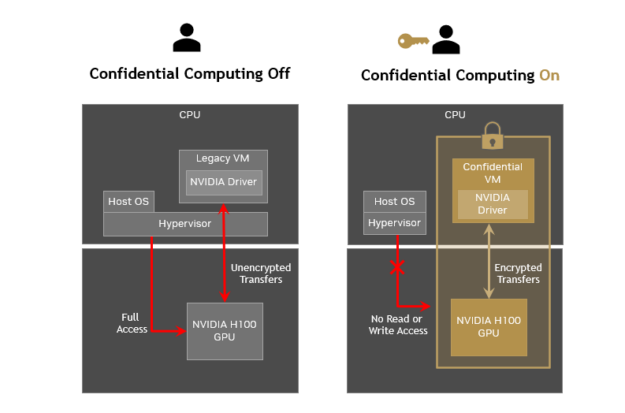
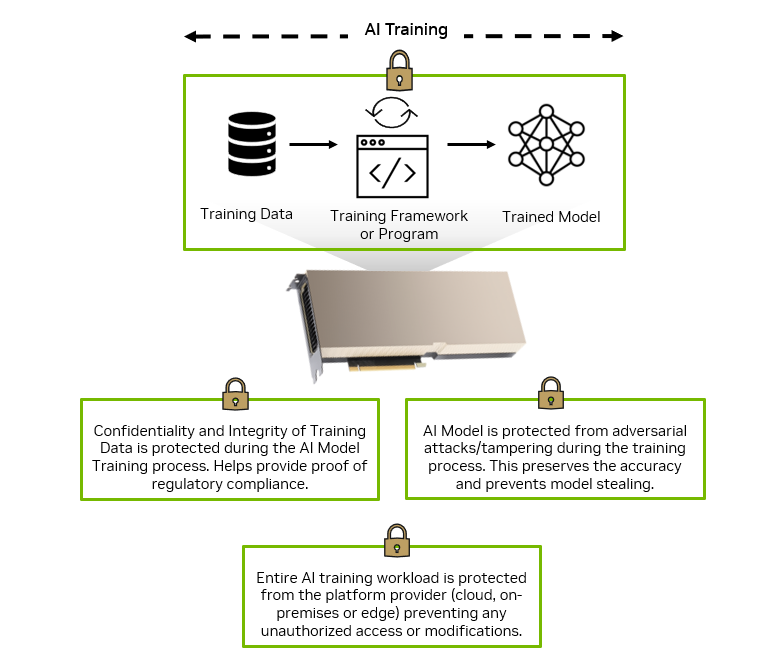
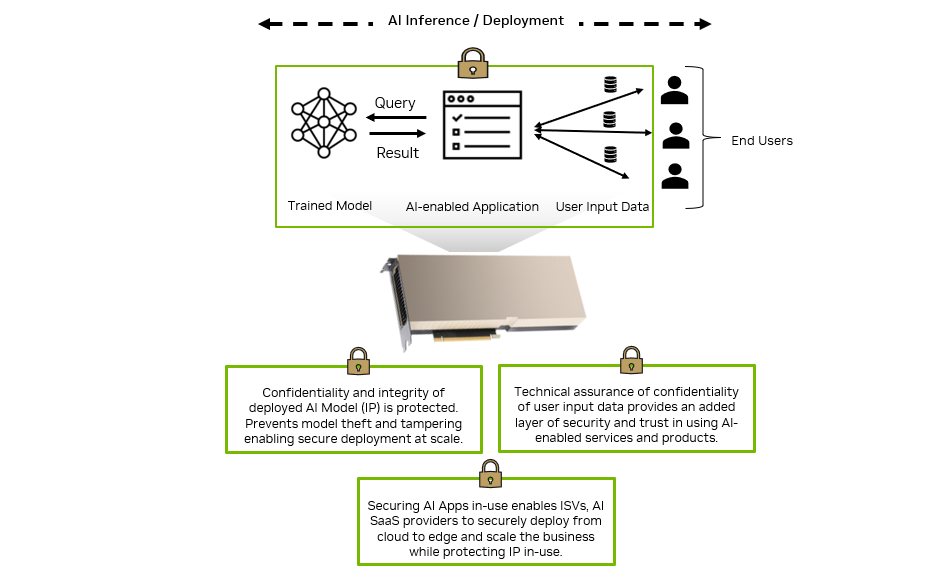
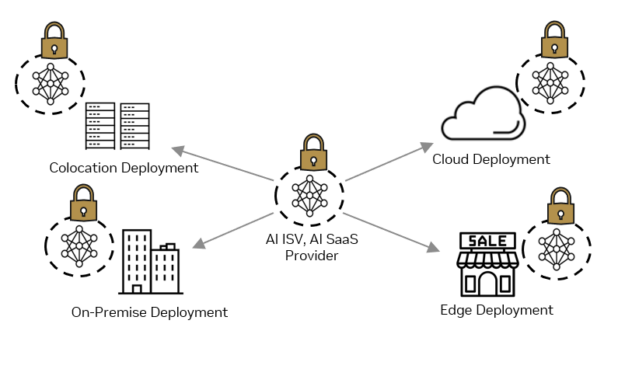
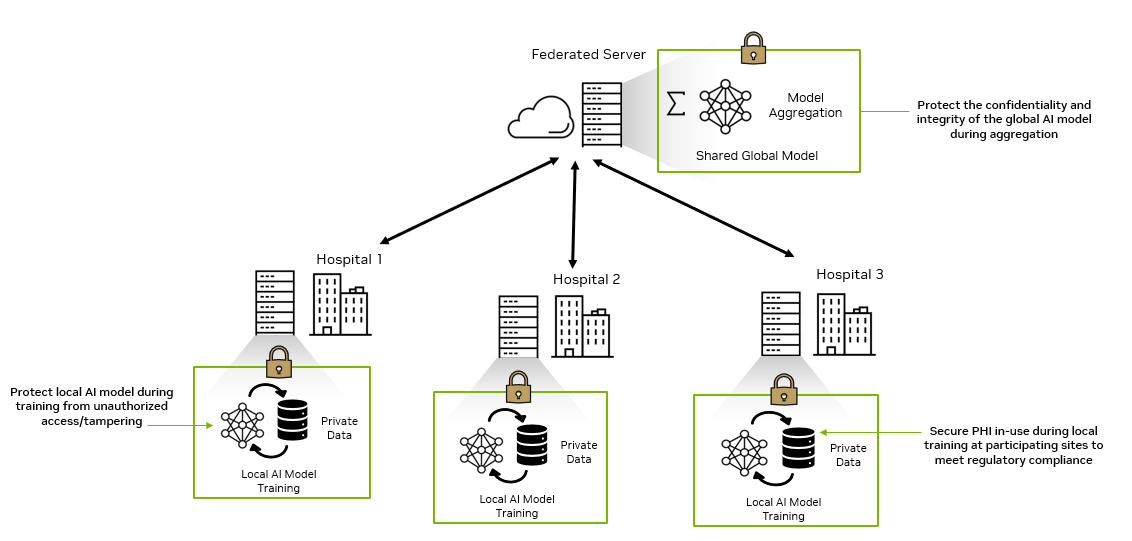
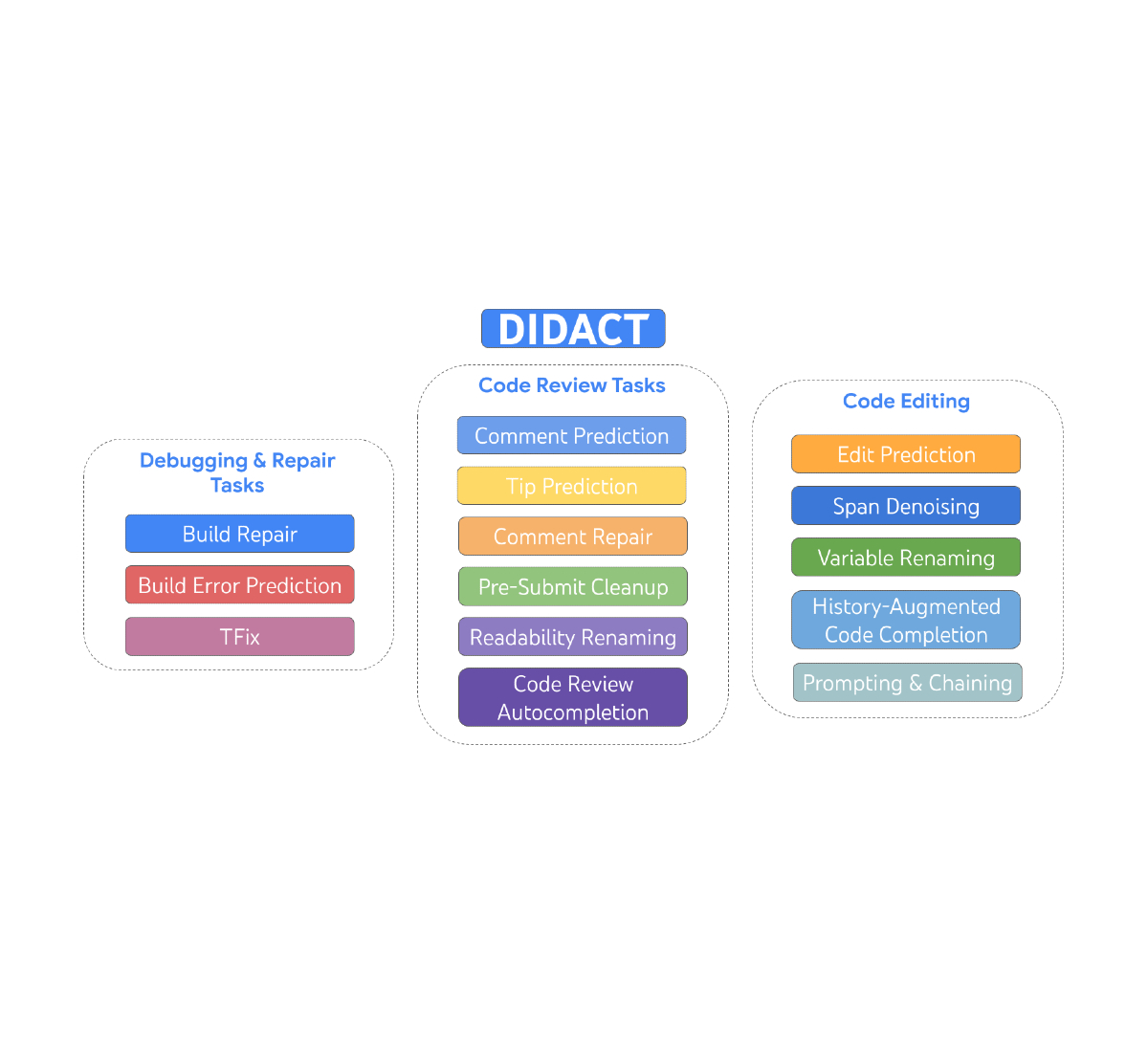
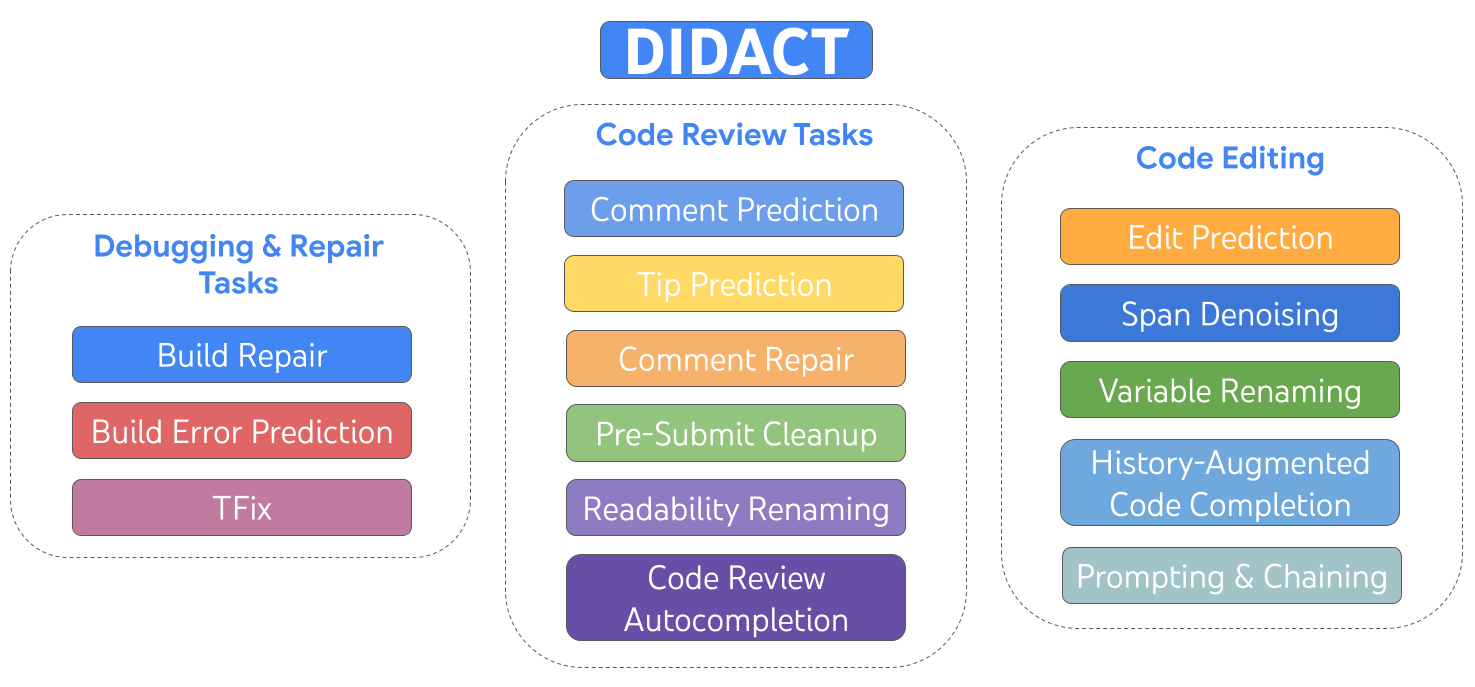




 AI is the topic of conversation around the world in 2023. It is rapidly being adopted by all industries including media, entertainment, and broadcasting. To be…
AI is the topic of conversation around the world in 2023. It is rapidly being adopted by all industries including media, entertainment, and broadcasting. To be…