
 A fundamental shift is currently taking place in how AI applications are built and deployed. AI applications are becoming more sophisticated and applied to…
A fundamental shift is currently taking place in how AI applications are built and deployed. AI applications are becoming more sophisticated and applied to…
A fundamental shift is currently taking place in how AI applications are built and deployed. AI applications are becoming more sophisticated and applied to broader use cases. This requires end-to-end AI lifecycle management—from data preparation, to model development and training, to deployment and management of AI apps. This approach can lower upfront costs, improve scalability, and decrease risk for customers using AI applications.
While the cloud-native approach to app development can be appealing to developers, machine learning (ML) projects are notoriously time-intensive and cost-intensive, as they require a team with a varied skill set to build and maintain.
This post explains how you can accelerate your vision AI model development using NVIDIA TAO Toolkit and deploying it for inference with NVIDIA Triton Inference Server—all on the Azure Machine Learning (Azure ML) platform.
NVIDIA Triton Inference Server is an open-source inference serving software that helps standardize model deployment and execution and delivers fast and scalable AI in production.
Azure ML is a cloud service for accelerating and managing the machine learning project lifecycle that enables developers to automate AI workflows, from data preparation and model training to model deployment. Developers can easily train, deploy, and manage AI models at scale with Azure ML.
Watch the video below to see a complete walkthrough of how to fine-tune your models with NVIDIA TAO Toolkit and deploy them for inference with NVIDIA Triton Inference Server—all on Azure ML.
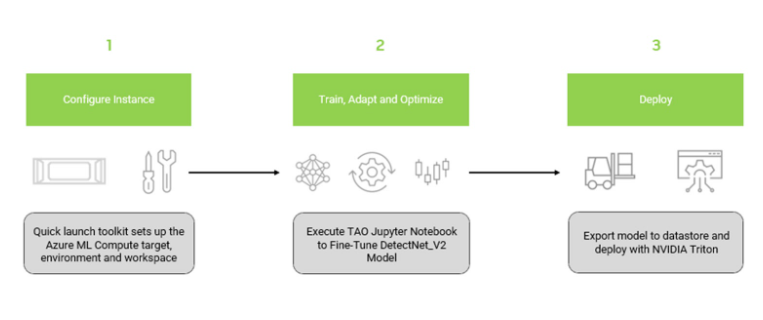
The overall workflow comprises three main steps:
- Install the NGC Azure ML Quick Launch Toolkit
- Train and optimize a pretrained object detection model
- Deploy the optimized model on Azure ML with NVIDIA Triton Inference Server
This section covers the steps required to install the NGC quick launch toolkit, which configures the Azure ML resources and uploads the necessary containers and models for training. The required config files are provided on the AzureML Quick Launch – TAO resource on the NVIDIA NGC Catalog.
Create a conda environment to install the Azure ML Quick Launch Toolkit to avoid any possible conflicts with existing libraries in your machine using the following code:
conda create -n azureml-ngc-tools python=3.8
conda activate azureml-ngc-toolsInstall the Azure ML Quick Launch Toolkit using the following code:
pip install azureml-ngc-toolsDownload resources from AzureML Quick Launch: TAO:
wget --content-disposition https://api.ngc.nvidia.com/v2/resources/nvidia/tao_detectnet_aml/versions/version1/zip -O azureml_quick_launch_tao_1.zipFile content
- The
azure_config.jsonfile contains the details pertaining to the user credentials, Azure workspace, and GPU compute resources that need to be updated. Edit theazureml_usersection with your Azure subscription ID, resource group, and workspace name. Next, edit theaml_computesection with GPU cluster details.- Recommended VMs: NCsv3, NDv2, or NC A100 v4 or ND A100 v4 series
- OS: Ubuntu 20.04
- To learn more about Azure VMs, refer to the Virtual Machine series. To learn how to spin up a Azure VM instance, refer to the Azure documentation.
- The
ngc_config.jsonfile contains the content from the NGC Catalog, such as Docker containers and Jupyter notebooks, that you can upload into the Azure Machine Learning Resources.
- Several scripts are packaged that will be used for model deployment.
- Run the toolkit using the following code:
azureml-ngc-tools --login azure_config.json --app ngc_config.jsonThis will upload all the resources to the Azure ML Datastore. After the upload, a URL is generated for the Jupyter session, which enables you to interact with the session from your local web browser. You can verify that all the resources have been uploaded in the Azure ML portal. The steps to check the resources in Azure ML portal are provided in the video above.
Train and optimize an object detection model with NVIDIA TAO Toolkit
This section covers the steps for training the model with NVIDIA TAO Toolkit on the Azure ML platform.
Before you begin the training process, you need to run the auxiliary notebook called CopyData.ipynb. The notebook is automatically generated with azureml-ngc-tools. This copies the notebooks from the Datastore to the compute cluster.
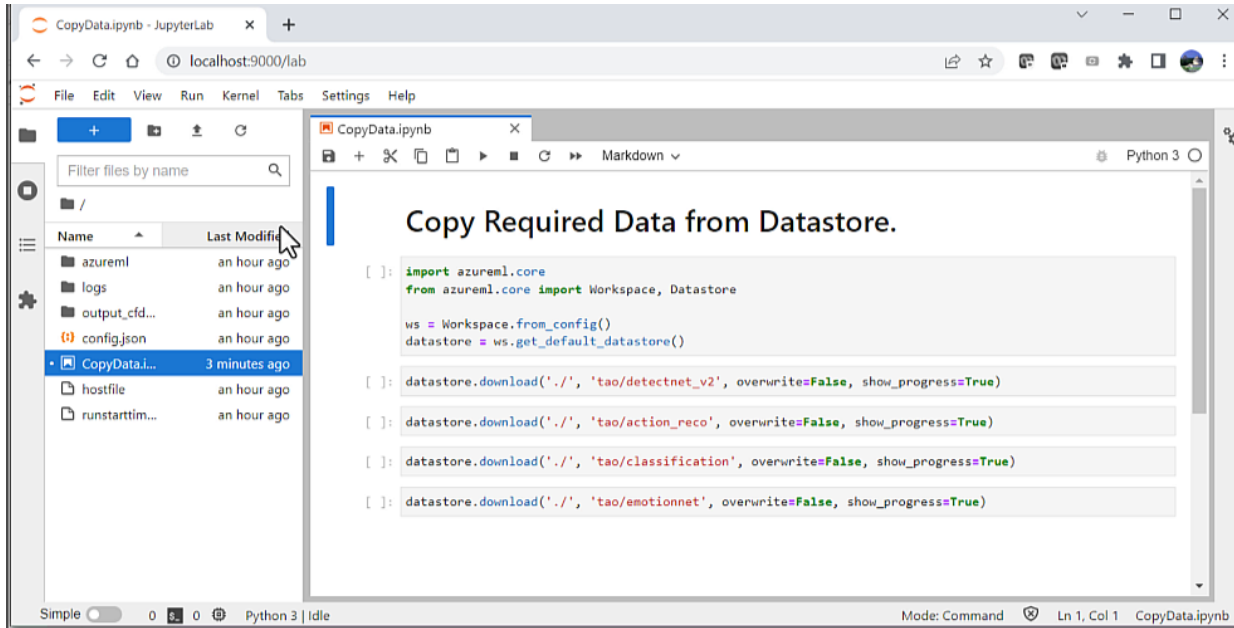
CopyData.ipynb Jupyter notebook for copying notebooks from the Datastore to the compute clusterA new folder called tao is created with all the additional data provided. This folder contains the Jupyter notebook, along with the required configuration files for training. Navigate to the TAO_detectnet_v2.ipynb notebook under folder tao/detectnet_V2. The DetectNet_v2 is one of the many computer vision notebooks available for training.
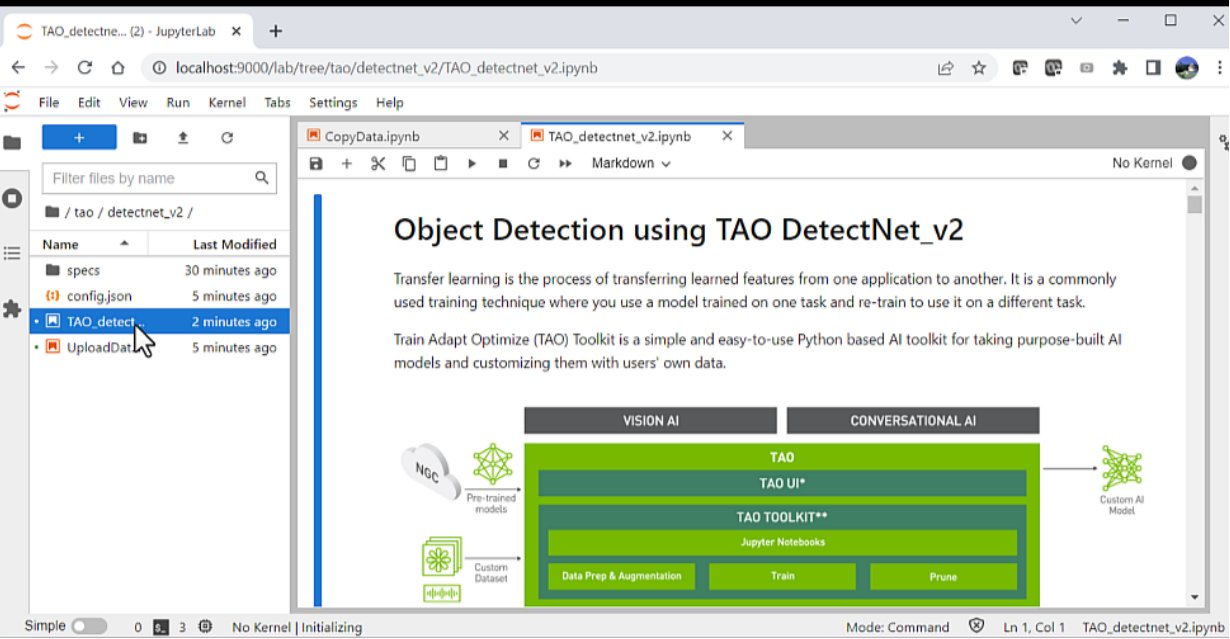
TAO DetectNet_v2 Jupyter notebook used for training the modelOnce you load up the notebook, simply execute each cell shown. For more information on this network or on how to configure hyperparameters, refer to the TAO Toolkit documentation. Some of the main steps covered in the notebook include:
- Setting environment variables
- Downloading and converting training data
- Downloading the model from the NGC catalog
- Training the model
- Pruning the model to remove unwanted layers and reduce model size
- Retraining the pruned model to recover lost accuracy
- Quantize Aware Training (QAT), which changes the precision of the model to INT8, reducing model size without sacrificing accuracy
- Exporting the model for inference
Once the model is generated on the compute cluster, you will need to upload the model to the Azure ML workspace. To upload, run the UploadData.ipnyb notebook to copy the model to the Datastore. This model will be used for deployment.
Deploy the model using NVIDIA Triton Inference Server
Next, deploy the exported model using NVIDIA Triton Inference Server. Use the model trained in the previous step with NVIDIA TAO Toolkit and stored in the Datastore. Pull the model directly from the Datastore.
Once the model has been uploaded, push the NVIDIA Triton container to the Azure Container Registry (ACR), create the inference end point, and test it using some sample images.
Register the model for inference
The next steps entail uploading the model for inference. Upload the trained model from the Datastore. Navigate to the Azure Machine Learning Studio to load the local model.
1. After logging in, go to the Azure ML workspace (created earlier) using the azureml-ngc-tool script. Select ‘Models’ from the left menu, then click ‘Register’ and ‘From datastore.’
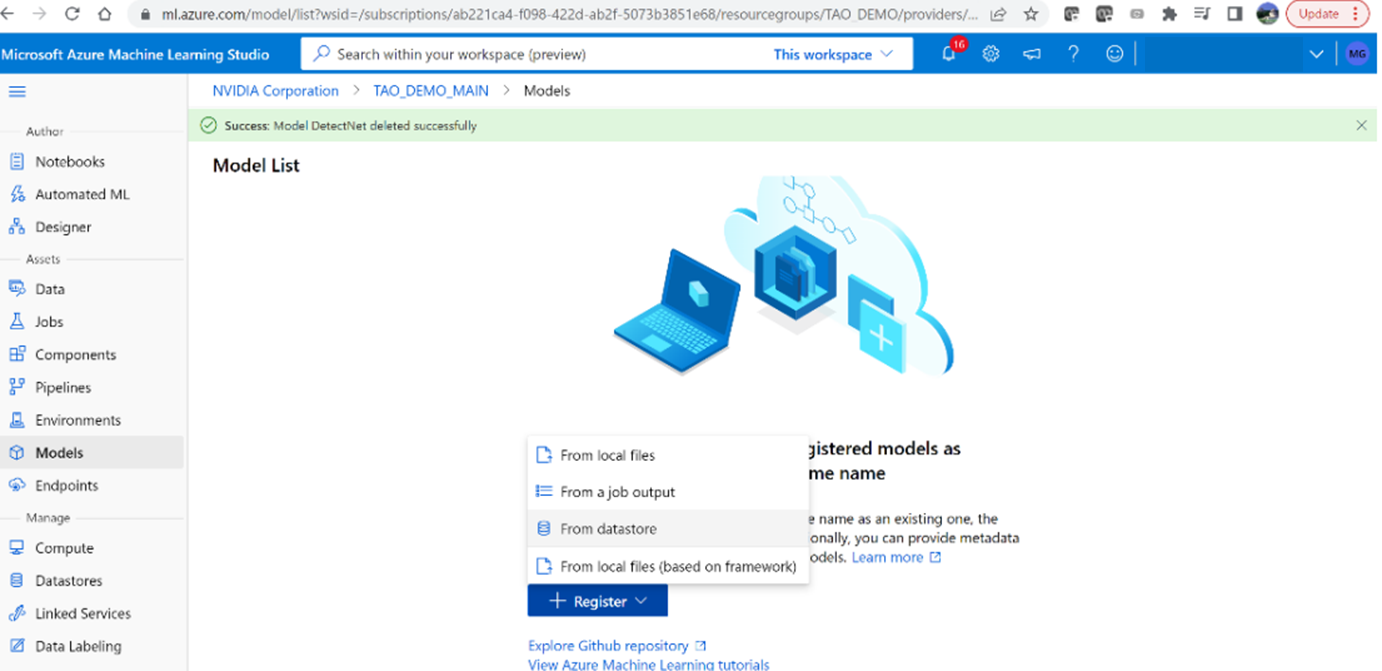
2. Select the ‘Triton’ model type to upload the model.
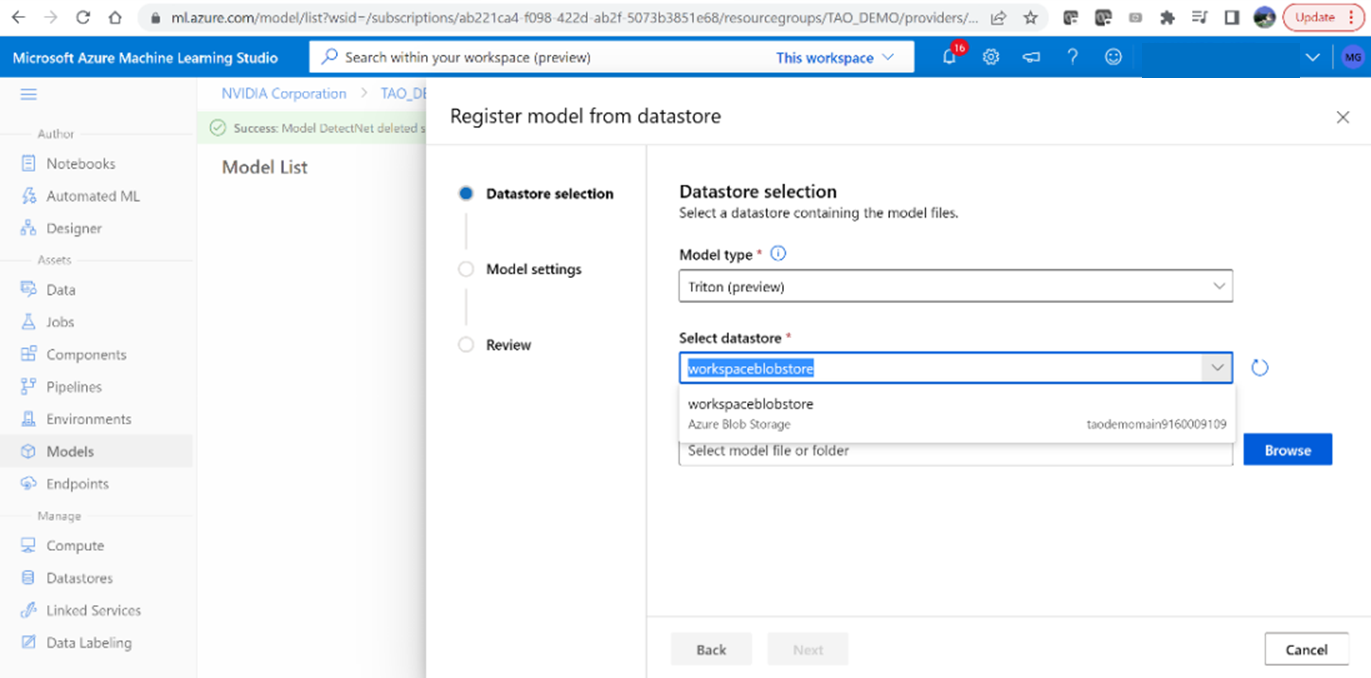
3. Browse and select the path: tao/detectnet _v2/model _repository
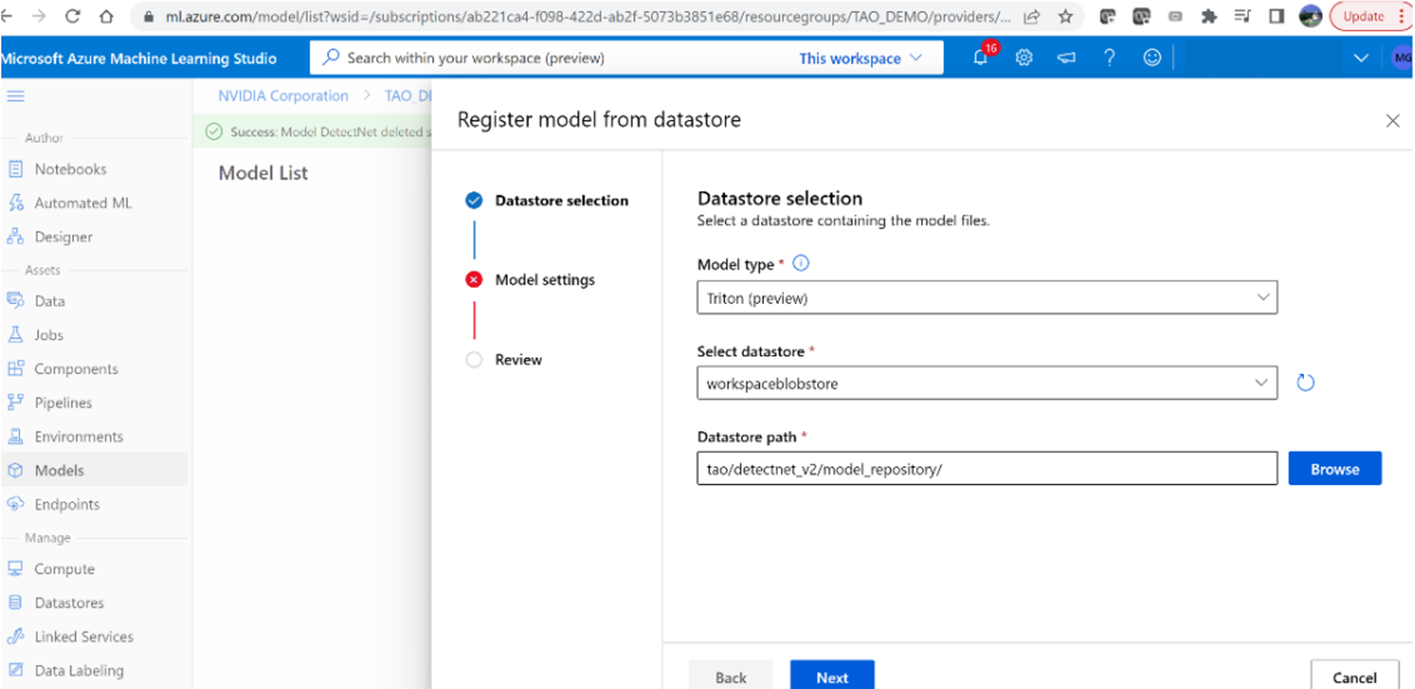
4. Name the model ‘DetectNet’ and set the version to ‘1’
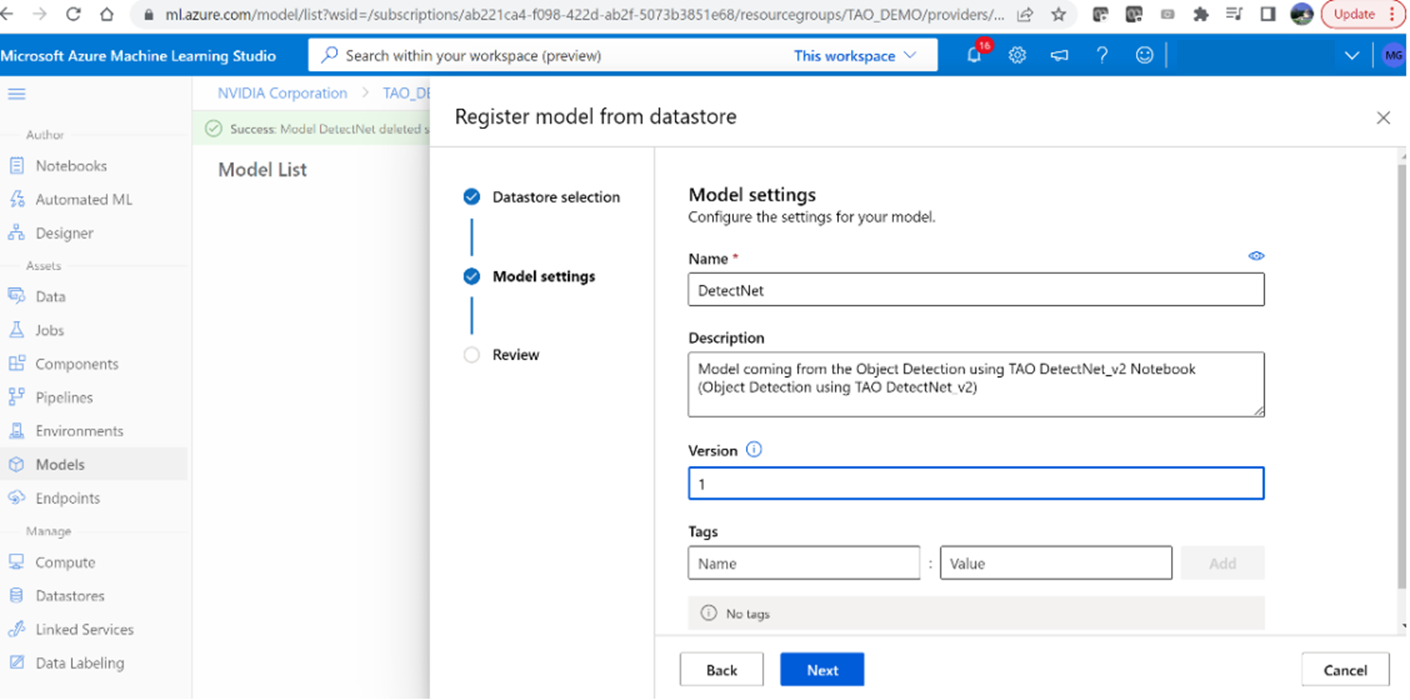
5. Once the model has successfully uploaded, you should be able to see the directory
structure.
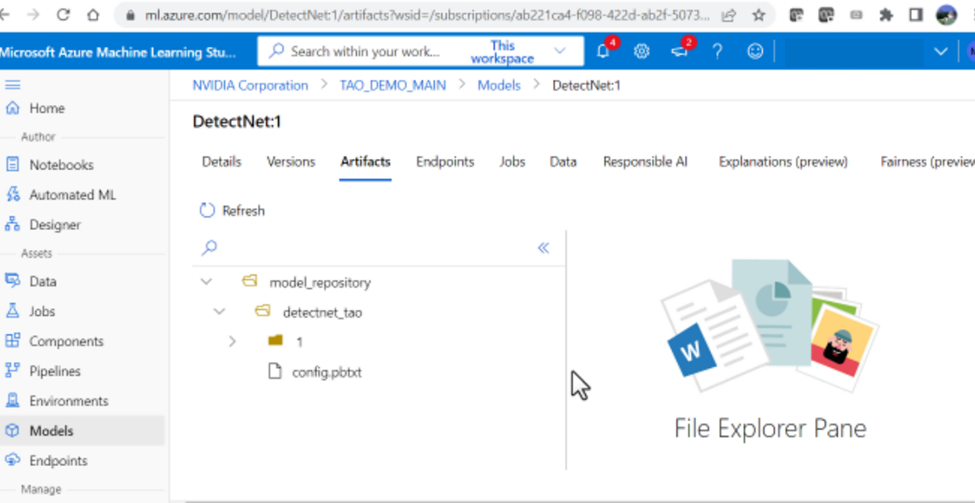
Build and upload NVIDIA Triton image to Azure Container Registry
Next, build the NVIDIA Triton container with necessary dependencies and upload the image to Azure Container Registry (ACR).
1. On your local machine, run the following script to create the NVIDIA Triton container with the necessary dependencies:
bash scripts/build_container.sh2. Verify that the image has been created locally by executing:
docker image lsIf successful, you should see the repo named nvcr.io/nvidia/tao/triton-apps.
3. Push the Docker image to ACR using the following script:
bash scripts/push_container_to_ACR.sh The registryname parameter is the name of the provided Azure ML workspace default container registry. Navigate to the Workspace essential properties dashboard to find it in the Azure portal. This script will push the Docker image to ACR and tag it as ${registryname}.azurecr.io/tao:latest.
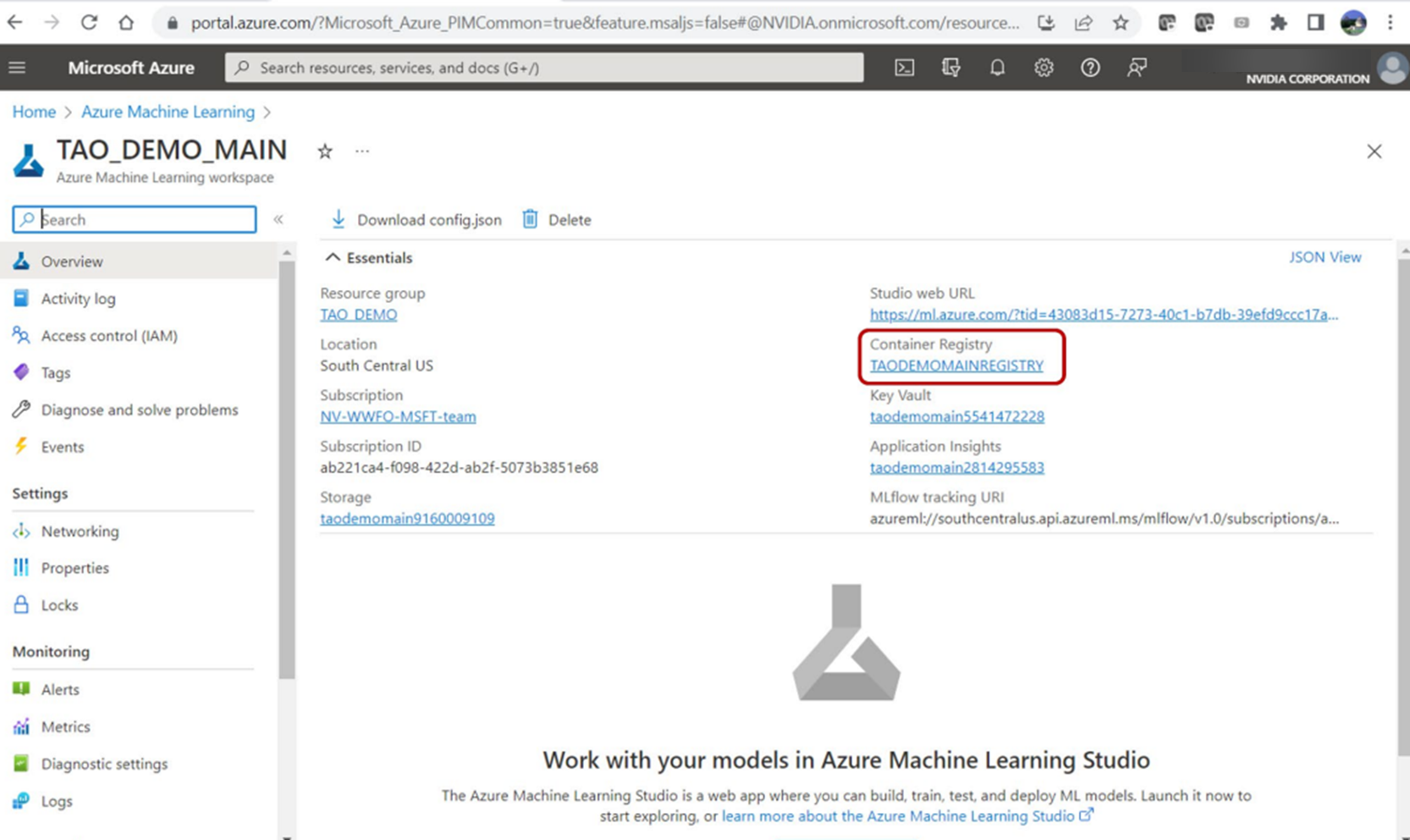
Once the script completes, navigate to ACR to see the container in the tao repository.
Create the Azure ML endpoint and deployment
On your local machine, run the following script to create an Azure ML Endpoint followed by the deployment:
bash scripts/create_endpoint _and_deployment.sh The script will create the Azure ML Endpoint with the endpoint names provided in the endpoint_aml.yml file. It then deploys the NVIDIA Triton service on Azure using the deployment_aml.yml file.
In this file, you can specify VM size. For this example, use the Standard_NC6s_v3 VM. These files are provided in scripts/auxiliary_files.
Once the script execution is complete, you should be able to see the deployment information, REST endpoint, and authentication key on the Azure portal. The deployment information can be found by clicking into the endpoint and navigating to the Deployment Logs tab.
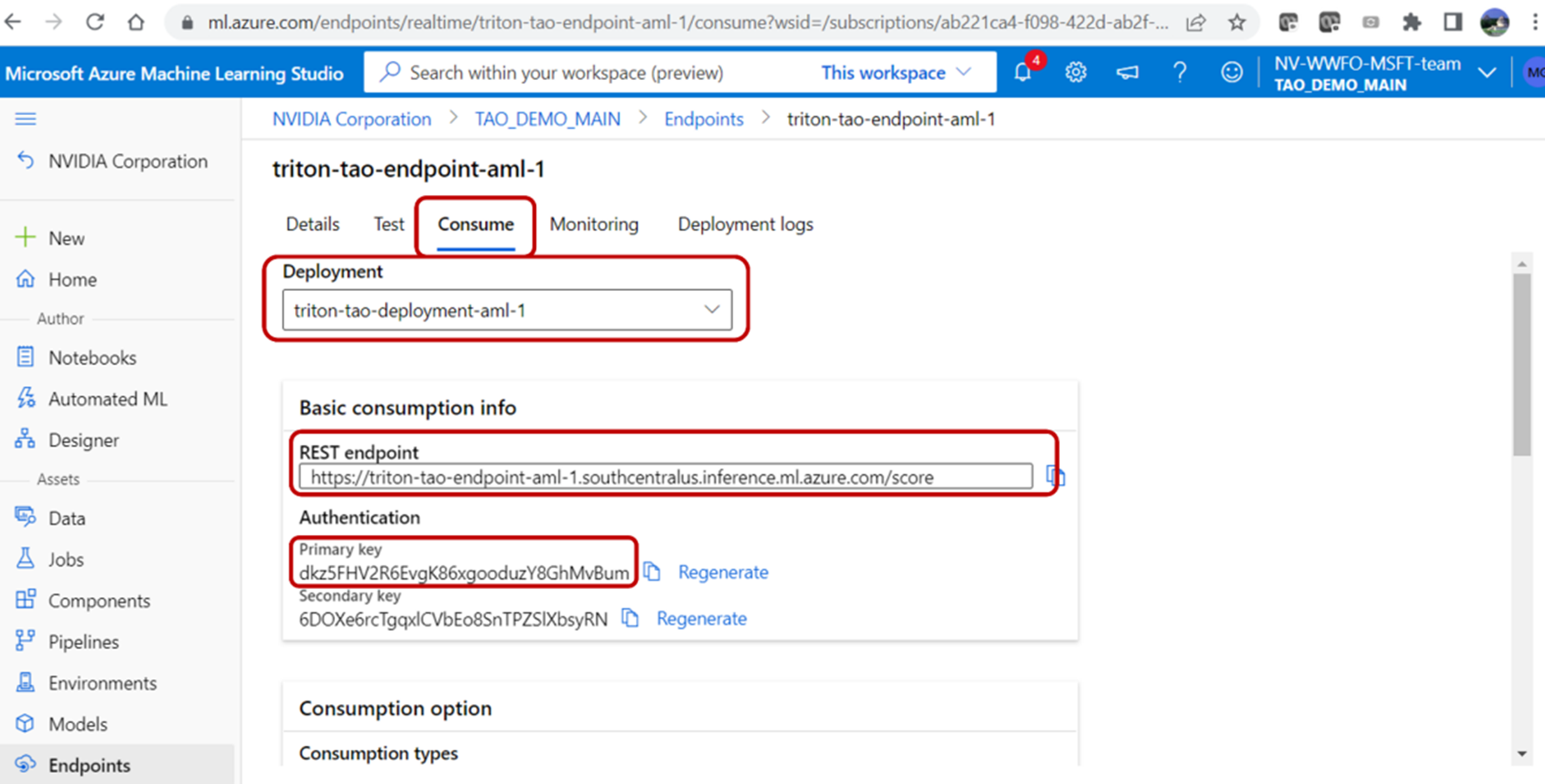
Validate the endpoint
You can validate the endpoint by using the REST endpoint URL and the primary key found under the Endpoints tab on the Azure portal. To query the Azure ML endpoint from the user local machine, run the following script:
bash scripts/infer.sh This script is provided in the zip file pulled from AzureML Quick Launch: TAO in the first step.
Next, provide the REST endpoint URL from the NVIDIA Triton deployment endpoint. The endpoint is queried with the test image provided with the option. The output image with bounding boxes is stored in .
Summary
This post showed the end-to-end workflow for fine-tuning a model with NVIDIA TAO Toolkit and deploying the trained object detection model using NVIDIA Triton Inference Server, all on Azure Machine Learning. These tools abstract away the AI framework complexity, enabling you to build and deploy AI applications in production without the need for AI expertise.