Last November, AWS integrated open-source inference serving software, NVIDIA Triton Inference Server, in Amazon SageMaker. Machine learning (ML) teams can use…
Last November, AWS integrated open-source inference serving software, NVIDIA Triton Inference Server, in Amazon SageMaker. Machine learning (ML) teams can use Amazon SageMaker as a fully managed service to build and deploy ML models at scale.
With this integration, data scientists and ML engineers can easily use the NVIDIA Triton multi-framework, high-performance inference serving with the Amazon SageMaker fully managed model deployment.
Multi-model endpoints enable higher performance at low cost on GPUs
Today, AWS announced Amazon SageMaker multi-model endpoint (MME) on GPUs. MMEs offer capabilities for running multiple deep learning or ML models on the GPU, at the same time, with Triton Inference Server.
MME enables sharing GPU instances behind an endpoint across multiple models and dynamically loads and unloads models based on the incoming traffic. With this, you can easily achieve optimal price performance.
Scaling inference with MMEs on GPUs
To harness the tremendous processing power of GPUs, MMEs use the Triton Inference Server concurrent model execution capability, which runs multiple models in parallel on the same AWS GPU instance. This functionality helps ML teams to scale AI by running many models that serve many inference requests and with stringent latency requirements. Your ML team will see an improvement in GPU utilization, and cost of inference.
Support is available in all regions where Amazon SageMaker is available, at no additional cost for the Triton Inference Server container.
Since its inception, artificial intelligence (AI) has transformed every aspect of the global economy through the ability to solve problems of all sizes in every…
Since its inception, artificial intelligence (AI) has transformed every aspect of the global economy through the ability to solve problems of all sizes in every industry. NVIDIA has spent the last decade empowering companies to solve the world’s toughest problems such as improving sustainability, stopping poachers, and bettering cancer detection and care. What many don’t know is that behind the scenes, NVIDIA has also been leveraging AI to solve day-to-day issues, such as improving efficiency and user experiences.
Improving efficiency and user experiences
NVIDIA recently adopted AI to ease the process of entering the company’s headquarters while maintaining security. The IT department thought they could improve the traditional badge-based access control entry through turnstiles.
Using AI, NVIDIA designed a new experience where employees could sign up for contactless and hands-free entry to headquarters. Especially during the COVID-19 pandemic, the contactless access program has proven to be convenient, quick, secure, and safe.
Watch the video below and read on to learn the steps NVIDIA implemented and the challenges that were overcome to deploy this scalable computer vision application.
Video 1. Learn the steps involved in deploying AI at the edge using NVIDIA Fleet Command
Unique considerations of edge environments
The objective of this project was to deliver a contactless access control solution that increased efficiency, security, and convenience for NVIDIA employees and could be scaled across multiple NVIDIA offices around the world.
The solution had to be one that fit around existing infrastructure in the entranceway and office, conformed to policies put forth by the facilities and the security teams, and could be updated, upgraded, and scaled remotely across NVIDIA offices worldwide.
Most edge AI solutions are deployed in environments where existing applications and systems already exist. Extra care needs to be taken to make sure that all constraints and requirements of the environment are taken into consideration.
Below are the steps that NVIDIA took to deploy a vision AI application for the entrance of the NVIDIA Endeavor building. The process took six months to complete.
Understand the problem and goal: The goal of the project was for the IT team to build a solution that was able to be remotely managed, updated frequently, scalable to hundreds of sites worldwide, and compatible with NVIDIA processes.
Identify teams involved: The NVIDIA facilities, engineering, and IT teams were involved with the project, along with a third-party software vendor who provided the application storage and training data.
Set constraints and requirements: Each team set their respective constraints and requirements for the application. For example, the facilities team determined the accuracy, security, and redundancy requirements while engineering determined latency and performance, and dictated which parts of the solution could be solved with engineering, and which parts IT needed to solve.
Set up a test environment to validate proof of concept (POC): The process of an employee entering headquarters through turnstiles was simulated in a lab setting. During this process, the requirements set forth by engineering such as model accuracy and latency were met.
Run the pilot: The pilot program consisted of enabling nine physical turnstiles to run in real-time and onboarding 200 employees into the program to test it.
Put the AI model into production: 3,000 employees were onboarded into the program and the application was monitored for three months. After operating successfully for three months, the application was ready to be scaled to other buildings at NVIDIA headquarters and eventually, to offices worldwide.
Figure 1. Employees walk through the security turnstiles at NVIDIA headquarters. The center turnstile showcases the AI solution that does not require swiping a badge.
Challenges implementing AI in edge environments
The biggest challenge was to create a solution that fit within the existing constraints and requirements of the environment. Every step of the process also came with unique implementation challenges, as detailed below.
Deliver the solution within the requirements
Latency: The engineering team identified the application latency requirements of detection and entrance at 700 milliseconds. At every step of the POC and pilot, this benchmark was tested and validated. Due to the heavy requests that were sent to the server to identify each person, infrastructure load issues were experienced. To mitigate this, the server was placed within 30-40 feet of the turnstiles. This helped to decrease the latency, as latency decreases when the physical distance data has to travel decreases.
Operations: Once the pilot program was scaled to 200 employees and the turnstiles were admitting multiple users into the building at a time, memory leaks were found. The memory leaks would cause the application to crash after four hours of operation. The issue was a simple engineering fix, but was not experienced during the initial pilot and POC phase.
Keep application operational: As mentioned, due to the memory leaks that were identified, the application would crash after four hours of operation. It’s important to remember that during the POC and pilot phase, the application should be run for as long as it needs to during production. For example, if the application needs to run for 12 hours, it may successfully run for four hours during the POC, but that is not a good indicator of whether the application will work for the requisite 12 hours.
Secure the application
Physical security: Edge locations are unique in that they are often physically accessible by individuals that can tamper with the solution. To avoid this, edge servers were placed in a nearby telecommunications room with access control.
Secure software supply chain: The application was developed with security in mind, which is why enterprise-grade software like NVIDIA Fleet Command, which has the ability to automatically create an audit log of all actions, was utilized. Using software from a trusted source ensures that organizations have a line of support to speak to when needed. A common mistake from organizations deploying edge applications is downloading software online without researching whether it is from a trusted source and accidentally downloading malware.
Manage the application
An edge management solution is essential. The NVIDIA IT team needed a tool that allowed for easy updates when bug fixes arose or model accuracy needed to be improved. Due to the global plans, the ability for an edge management solution to update hardware and software with minimal accuracy was also a priority.
Addressing all of these functions is NVIDIA Fleet Command, a managed platform for AI container orchestration. Not only does Fleet Command streamline the provisioning and deployment of systems at the edge, it simplifies the management of distributed computing environments by allowing for remote system provisioning, over-the-air updates, remote application and system access, monitoring and alerting, and application logging, allowing IT to ensure these widely distributed environments are operational at all times.
A successful edge AI deployment
Once edge infrastructure is in place, enterprises can easily add more models to the application. In this case, IT can add more applications to the server and even roll the solution out to NVIDIA offices worldwide, thanks to Fleet Command. It is the glue that holds our stack together and provides users with turnkey AI orchestration that keeps organizations from having to build, maintain, and secure edge AI deployments from the ground up themselves.
NVIDIA FLARE 2.2 includes a host of new features that reduce development time and accelerate deployment for federated learning, helping organizations cut costs…
NVIDIA FLARE 2.2 includes a host of new features that reduce development time and accelerate deployment for federated learning, helping organizations cut costs for building robust AI. Get the details about what’s new in this release.
An open-source platform and software development kit (SDK) for Federated Learning (FL), NVIDIA FLARE continues to evolve to enable its end users to leverage distributed, multiparty collaboration for more robust AI development from simulation to production.
The release of FLARE 2.2 brings numerous updates that simplify the research and development workflow for researchers and data scientists, streamline deployment for IT practitioners and project leaders, and strengthen security to ensure data privacy in real-world deployments. These include:
Figure 1. The end-to-end NVIDIA FLARE 2.2 workflow
FL Simulator: Rapid development and debugging
One of the key features to enable research and development workflows is the new FL Simulator. The Simulator allows researchers and developers to run and debug a FLARE application without the overhead of provisioning and deploying a project. The Simulator provides a lightweight environment with a FLARE server and any number of connected clients on which an application can be deployed. Debugging is possible by leveraging the Simulator Runner API, allowing developers to drive an application with simple Python scripts to create breakpoints within the FLARE application code.
The Simulator is designed to accommodate systems with limited resources, such as a researcher’s laptop, by running client processes sequentially in a limited number of threads. The same simulation can be easily run on a larger system with multiple GPUs by allocating a client or multiple clients per GPU. This gives the developer or researcher a flexible environment to test application scalability. Once the application has been developed and debugged, the same application code can be directly deployed on a production, distributed FL system without change.
Figure 2. The FLARE Dashboard showing the Project Admin user management panel (left), and the User panel for self-service downloads of project configuration and client software(right)
Federated learning workflows and federated data science
FLARE 2.2 also introduces new integrations and federated workflows designed to simplify application development and enable federated data science and analytics.
Federated statistics
When working with distributed datasets, it is often important to assess the data quality and distribution across the set of client datasets. FLARE 2.2 provides a set of federated statistics operators (controllers and executors) that can be used to generate global statistics based on individual client-side statistics.
The workflow controller and executor are designed to allow data scientists to quickly implement their own statistical methods (generators) based on the specifics of their datasets of interest. Commonly used statistics are provided out-of-the box, including count, sum, mean, standard deviation, and histograms, along with routines to visualize the global and individual statistics. The built-in visualization tools can be used to view statistics across all datasets at all sites as well as global aggregates, for example in a notebook utility as shown in Figure 3.
Figure 3. Example histograms from the federated statistics image example using the built-in FLARE statistics visualization class
In addition to these new workflows, the existing set of FLARE examples have been updated to integrate with the FL Simulator and leverage new privacy and security features. These example applications leverage common Python toolkits like NumPy, PyTorch, and Tensorflow, and highlight workflows in training, cross validation, and federated analysis.
Integration of FLARE and MONAI
MONAI, the Medical Open Network for AI, recently released an abstraction that allows MONAI models packaged in the MONAI Bundle (MB) format to be easily extended for federated training on any platform that implements client training algorithms in these new APIs. FLARE 2.2 includes a new client executor that makes this integration, allowing MONAI model developers to easily develop and share models using the bundle concept, and then seamlessly deploy these models in a federated paradigm using NVIDIA FLARE.
Figure 4. MONAI FL integration with ClientAlgo API
To see an example of using FLARE to train a medical image analysis model using federated averaging (FedAvg) and MONAI Bundle, visit NVFlare on GitHub. The example shows how to download the dataset, download the spleen_ct_segmentation bundle from the MONAI Model Zoo, and how to execute it with FLARE using either the FL simulator or POC mode.
MONAI also allows computing summary data statistics on the datasets defined in the bundle. These can be shared and visualized in FLARE using the federated statistics operators described above. The use of federated statistics and MONAI is included in the GitHub example above.
Figure 5. Federated spleen segmentation in abdominal CT using MONAI bundle from the Model Zoo. For details, visit NVFlare on GitHub.
XGBoost integration
A common request from the federated learning user community is support for more traditional machine learning frameworks in a federated paradigm. FLARE 2.2 provides examples that illustrate horizontal federated learning using two approaches: histogram-based collaboration and tree-based collaboration.
The community DMLC XGBoost project recently released an adaptation of the existing distributed XGBoost training algorithm that allows federated clients to act as distinct workers in the distributed algorithm. This distributed algorithm is used in a reference implementation of horizontal federated learning that demonstrates the histogram-based approach.
FLARE 2.2 also provides a reference federated implementation of tree-based boosting using two methods: Cyclic Training and Bagging Aggregation. In the Cyclic Training method, multiple sites execute tree boosting on their own local data, forwarding the resulting tree sequence to the next client in the federation for the subsequent round of boosting. In the method of Bagging Aggregation, all sites start from the same global model and boost a number of trees based on their local data. The resulting trees are then aggregated by the server for the next round’s boosting.
Real-world federated learning
The new suite of tools and workflows available in FLARE 2.2 allow developers and data scientists to quickly build applications and more easily bring them to production in a distributed federated learning deployment. When moving to a real-world distributed deployment, there are many considerations for security and privacy that must be addressed by both the project leader and developers, as well as the individual sites participating in the federated learning deployment.
FLARE Dashboard: Streamlined deployment
New in 2.2 is the FLARE Dashboard, designed to simplify project administration and deployment for lead researchers and IT practitioners supporting real-world FL deployments. The FLARE Dashboard allows a project administrator to deploy a website that can be used to define project details, gather information about participant sites, and distribute the startup kits that are used to connect client sites.
The FLARE Dashboard is backed by the same provisioning system in previous versions of the platform and allows users the flexibility to choose either the web UI or the classic command line provisioning, depending on project requirements. Both the Dashboard and provisioning CLI now support dynamic provisioning, allowing project administrators to add federated and admin clients on-demand. This ability to dynamically allocate new training and admin clients without affecting existing clients dramatically simplifies management of the FL system over the lifecycle of the project.
Unified FLARE CLI
The FLARE command-line interface (CLI) has been completely rewritten to consolidate all commands under a common top-level nvflare CLI and introduce new convenience tools for improved usability.
Subcommands include all of the pre-existing standalone CLI tools like poc, provision, and authz_preview, as well as new commands for launching the FL Simulator and the FLARE Dashboard. The nvflare command now also includes a preflight_check that provides administrators and end-users a tool to verify system configuration, connectivity to other FLARE subsystems, proper storage configuration, and perform a dry-run connection of the client or server.
Improved site security
The security framework of NVIDIA FLARE has been redesigned in 2.2 to improve both usability and overall security. The roles that are used to define privileges and system operation policies have been streamlined to include: Project Admin, Org Admin, Lead Researcher, and Member Researcher. The security framework has been strengthened based on these roles, to allow individual organizations and sites to implement their own policies to protect individual privacy and intellectual property (IP) through a Federated Authorization framework.
Federated Authorization shifts both the definition and enforcement of privacy and security policies to individual organizations and member sites, allowing participants to define their own fine-grained site policy:
Each organization defines its policy in its own authorization.json configuration
This locally defined policy is loaded by FL clients owned by the organization
The policy is also enforced by these FL clients
The site policies can be used to control all aspects of the federated learning workflow, including:
Resource management: The configuration of system resources that are solely the decisions of local IT
Authorization policy: Local authorization policy that determines what a user can or cannot do on the local site
Privacy policy: Local policy that specifies what types of studies are allowed and how to add privacy protection to the learning results produced by the FL client on the local site
Logging configuration: Each site can now define its own logging configuration for system generated log messages
These site policies also allow individual sites to enforce their own data privacy by defining custom filters and encryption applied to any information passed between the client site and the central server.
This new security framework provides project and organization administrators, researchers, and site IT the tools required to confidently take a federated learning project from proof-of-concept to a real-world deployment.
Getting started with NVIDIA FLARE 2.2
We’ve highlighted just some of the new features in FLARE 2.2 that allow researchers and developers to quickly adopt the platform to prototype and deploy federated learning workflows. Tools like the FL Simulator and FLARE Dashboard for streamlined development and deployment, along with a growing set of reference workflows, make it easier and faster than ever to get started and save valuable development time.
In addition to the examples detailed in this post, FLARE 2.2 includes many other enhancements that increase power and flexibility of the platform, including:
Examples for Docker compose and Helm deployment
Preflight checks to help identify and correct connectivity and configuration issues
Simplified POC commands to test distributed deployments locally
Updated example applications
To learn more about these features and get started with the latest examples, visit the NVIDIA FLARE documentation. As we are actively developing the FLARE platform to meet the needs of researchers, data scientists, and platform developers, we welcome any suggestions and feedback in the NVIDIA FLARE GitHub community.
Enterprises of all sizes are increasingly leveraging virtualization and hyperconverged infrastructure (HCI). This technology delivers reliable and secure…
Enterprises of all sizes are increasingly leveraging virtualization and hyperconverged infrastructure (HCI). This technology delivers reliable and secure compute resources for operations while reducing data center footprint. HCI clusters rely on robust, feature-rich networking fabrics to deliver on-premises solutions that can seamlessly connect to the cloud.
Microsoft Azure Stack HCI is a hyperconverged infrastructure cluster solution that can run containerized applications. It hosts virtualized Windows and Linux workloads and storage in a hybrid environment that combines on-premises infrastructure with Azure cloud services. The server components of Azure Stack HCI can be interconnected using devices that support the appropriate validation requirements.
NVIDIA Spectrum Ethernet switches are purpose-built networking solutions designed to support the requirements of Microsoft Azure Stack HCI. This on-premises solution enables enterprises to leverage cloud functionality, effectively creating a hybrid cloud solution.
Spectrum switches provide end-to-end ethernet for reliable networking with Azure Stack HCI. Spectrum switches also are available in multiple form factors including half-width 10/25/100 Gb/s TORs, two of which can be installed side-by-side in 1 RU (rack unit) space to accommodate the throughput, port density, and high availability required.
These features are delivered through Cumulus Linux (starting with version 5.1 and continuing in all subsequent releases), the flagship network operating system for NVIDIA Ethernet switches. Cumulus Linux is an open operating system with a “drive it your way” philosophy for management. It comes with a comprehensive data model based CLI known as NVUE (NVIDIA User Experience). But since it is a Linux network operating system, users can interact with Cumulus Linux as a pure Linux system. The flexibility of the configuration methodology allows it to easily integrate with whatever automation toolset you prefer.
“We are pleased to see NVIDIA Spectrum Ethernet switches optimized for Microsoft Azure Stack HCI,” says Tim Isaacs, General Manager at Microsoft. “With the combination of the newly introduced Network HUD feature in the latest Azure Stack HCI release and NVIDIA’s updated Cumulus Linux network operating system for Spectrum Ethernet switches, we can jointly provide our customers rich and robust visibility into their Azure Stack HCI network environment.”
Finally, NVIDIA worked closely with the Microsoft team to create standardized configurations for the switches to optimize traffic between the different hyperconverged nodes. Through testing a full Azure Stack HCI deployment using NVIDIA Spectrum switches, the configurations were generated to ensure a seamless experience during server deployment. These configurations are available through the Microsoft standard deployment experience.
To get NVIDIA Spectrum switches for your Microsoft Azure Stack HCI deployment, visit the NVIDIA online store or talk to an NVIDIA partner.
This week ‘In the NVIDIA Studio,’ we’re highlighting 3D and motion graphics artist SouthernShotty — and scenes from his soon-to-be released short film, Watermelon Girl.
A virtual event designed for healthcare developers and startups, this summit on November 10, 2022 offers a full day of technical talks to reach developers and…
A virtual event designed for healthcare developers and startups, this summit on November 10, 2022 offers a full day of technical talks to reach developers and technical leaders in the EMEA region. Get best practices and insights for applications, from biopharma to medical imaging.
When two technologies converge, they can create something new and wonderful — like cellphones and browsers were fused to forge smartphones. Today, developers are applying AI’s ability to find patterns to massive graph databases that store information about relationships among data points of all sorts. Together they produce a powerful new tool called graph neural Read article >
Sensor AI solutions specialist SenSen has turned to the NVIDIA Jetson edge AI platform to help regulators track heavy vehicles moving across Australia. Australia’s National Heavy Vehicle Regulator, or NHVR, has a big job — ensuring the safety of truck drivers across some of the world’s most sparsely populated regions. They’re now harnessing AI to Read article >

 Last November, AWS integrated open-source inference serving software, NVIDIA Triton Inference Server, in Amazon SageMaker. Machine learning (ML) teams can use…
Last November, AWS integrated open-source inference serving software, NVIDIA Triton Inference Server, in Amazon SageMaker. Machine learning (ML) teams can use…") Since its inception, artificial intelligence (AI) has transformed every aspect of the global economy through the ability to solve problems of all sizes in every…
Since its inception, artificial intelligence (AI) has transformed every aspect of the global economy through the ability to solve problems of all sizes in every…
") NVIDIA FLARE 2.2 includes a host of new features that reduce development time and accelerate deployment for federated learning, helping organizations cut costs…
NVIDIA FLARE 2.2 includes a host of new features that reduce development time and accelerate deployment for federated learning, helping organizations cut costs…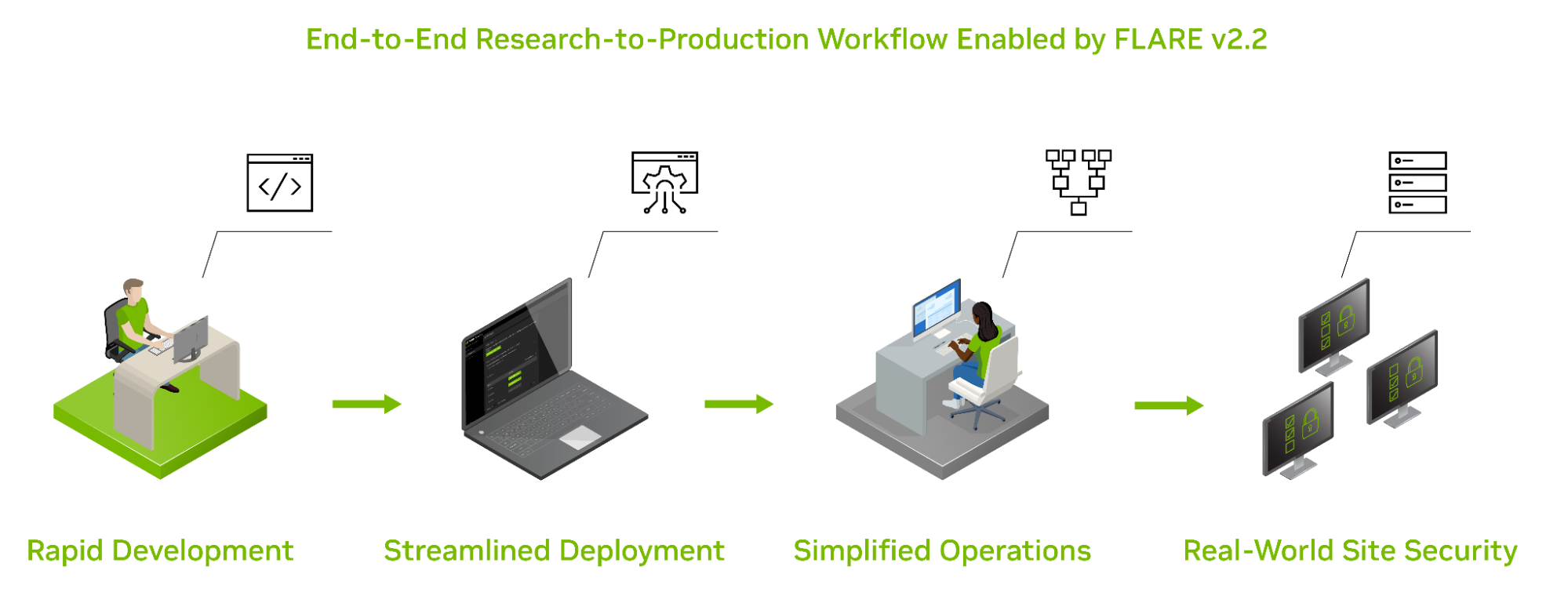




 Enterprises of all sizes are increasingly leveraging virtualization and hyperconverged infrastructure (HCI). This technology delivers reliable and secure…
Enterprises of all sizes are increasingly leveraging virtualization and hyperconverged infrastructure (HCI). This technology delivers reliable and secure… Join experts from Google, Meta, NVIDIA, and more at the first annual NVIDIA Speech AI Summit. Register now!
Join experts from Google, Meta, NVIDIA, and more at the first annual NVIDIA Speech AI Summit. Register now! A virtual event designed for healthcare developers and startups, this summit on November 10, 2022 offers a full day of technical talks to reach developers and…
A virtual event designed for healthcare developers and startups, this summit on November 10, 2022 offers a full day of technical talks to reach developers and…") Learn how to build, train, customize, and deploy a GPU-accelerated automatic speech recognition service with NVIDIA Riva in this self-paced course.
Learn how to build, train, customize, and deploy a GPU-accelerated automatic speech recognition service with NVIDIA Riva in this self-paced course.