Growing up in a military family, Christopher Scott moved more than 30 times, which instilled in him “the ability to be comfortable with, and even motivated by, new environments,” he said.
Posted by Xi Chen and Xiao Wang, Software Engineers, Google Research
Advanced language models (e.g., GPT, GLaM, PaLM and T5) have demonstrated diverse capabilities and achieved impressive results across tasks and languages by scaling up their number of parameters. Vision-language (VL) models can benefit from similar scaling to address many tasks, such as image captioning, visual question answering (VQA), object recognition, and in-context optical-character-recognition (OCR). Increasing the success rates for these practical tasks is important for everyday interactions and applications. Furthermore, for a truly universal system, vision-language models should be able to operate in many languages, not just one.
In “PaLI: A Jointly-Scaled Multilingual Language-Image Model”, we introduce a unified language-image model trained to perform many tasks and in over 100 languages. These tasks span vision, language, and multimodal image and language applications, such as visual question answering, image captioning, object detection, image classification, OCR, text reasoning, and others. Furthermore, we use a collection of public images that includes automatically collected annotations in 109 languages, which we call the WebLI dataset. The PaLI model pre-trained on WebLI achieves state-of-the-art performance on challenging image and language benchmarks, such as COCO-Captions, CC3M, nocaps, TextCaps, VQAv2, OK-VQA, TextVQA and others. It also outperforms prior models’ multilingual visual captioning and visual question answering benchmarks.
Overview One goal of this project is to examine how language and vision models interact at scale and specifically the scalability of language-image models. We explore both per-modality scaling and the resulting cross-modal interactions of scaling. We train our largest model to 17 billion (17B) parameters, where the visual component is scaled up to 4B parameters and the language model to 13B.
The PaLI model architecture is simple, reusable and scalable. It consists of a Transformer encoder that processes the input text, and an auto-regressive Transformer decoder that generates the output text. To process images, the input to the Transformer encoder also includes “visual words” that represent an image processed by a Vision Transformer (ViT). A key component of the PaLI model is reuse, in which we seed the model with weights from previously-trained uni-modal vision and language models, such as mT5-XXL and large ViTs. This reuse not only enables the transfer of capabilities from uni-modal training, but also saves computational cost.
The PaLI model addresses a wide range of tasks in the language-image, language-only and image-only domain using the same API (e.g., visual-question answering, image captioning, scene-text understanding, etc.). The model is trained to support over 100 languages and tuned to perform multilingually for multiple language-image tasks.
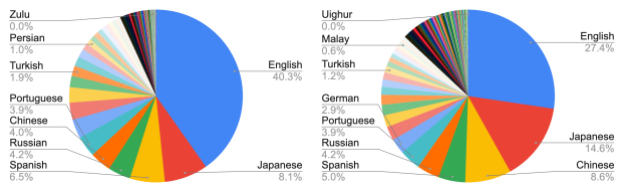
Dataset: Language-Image Understanding in 100+ Languages Scaling studies for deep learning show that larger models require larger datasets to train effectively. To unlock the potential of language-image pretraining, we construct WebLI, a multilingual language-image dataset built from images and text available on the public web.
WebLI scales up the text language from English-only datasets to 109 languages, which enables us to perform downstream tasks in many languages. The data collection process is similar to that employed by other datasets, e.g. ALIGN and LiT, and enabled us to scale the WebLI dataset to 10 billion images and 12 billion alt-texts.
In addition to annotation with web text, we apply the Cloud Vision API to perform OCR on the images, leading to 29 billion image-OCR pairs. We perform near-deduplication of the images against the train, validation and test splits of 68 common vision and vision-language datasets, to avoid leaking data from downstream evaluation tasks, as is standard in the literature. To further improve the data quality, we score image and alt-text pairs based on their cross-modal similarity, and tune the threshold to keep only 10% of the images, for a total of 1 billion images used for training PaLI.
Sampled images from WebLI associated with multilingual alt-text and OCR. The second image is by jopradier (original), used under the CC BY-NC-SA 2.0 license. Remaining images are also used with permission.
Statistics of recognized languages from alt-text and OCR in WebLI.
Image-text pair counts of WebLI and other large-scale vision-language datasets, CLIP, ALIGN and LiT.
Training Large Language-Image Models Vision-language tasks require different capabilities and sometimes have diverging goals. Some tasks inherently require localization of objects to solve the task accurately, whereas some other tasks might need a more global view. Similarly, different tasks might require either long or compact answers. To address all of these objectives, we leverage the richness of the WebLI pre-training data and introduce a mixture of pre-training tasks, which prepare the model for a variety of downstream applications. To accomplish the goal of solving a wide variety of tasks, we enable knowledge-sharing between multiple image and language tasks by casting all tasks into a single generalized API (input: image + text; output: text), which is also shared with the pretraining setup. The objectives used for pre-training are cast into the same API as a weighted mixture aimed at both maintaining the ability of the reused model components and training the model to perform new tasks (e.g., split-captioning for image description, OCR prediction for scene-text comprehension, VQG and VQA prediction).
The model is trained in JAX with Flax using the open-sourced T5X and Flaxformer framework. For the visual component, we introduce and train a large ViT architecture, named ViT-e, with 4B parameters using the open-sourced BigVision framework. ViT-e follows the same recipe as the ViT-G architecture (which has 2B parameters). For the language component, we concatenate the dense token embeddings with the patch embeddings produced by the visual component, together as the input to the multimodal encoder-decoder, which is initialized from mT5-XXL. During the training of PaLI, the weights of this visual component are frozen, and only the weights of the multimodal encoder-decoder are updated.
Results We compare PaLI on common vision-language benchmarks that are varied and challenging. The PaLI model achieves state-of-the-art results on these tasks, even outperforming very large models in the literature. For example, it outperforms the Flamingo model, which is several times larger (80B parameters), on several VQA and image-captioning tasks, and it also sustains performance on challenging language-only and vision-only tasks, which were not the main training objective.
PaLI (17B parameters) outperforms the state-of-the-art approaches (including SimVLM, CoCa, GIT2, Flamingo, BEiT3) on multiple vision-and-language tasks. In this plot we show the absolute score differences compared with the previous best model to highlight the relative improvements of PaLI. Comparison is on the official test splits when available. CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.
<!–
PaLI (17B parameters) outperforms the state-of-the-art approaches (including SimVLM, CoCa, GIT2, Flamingo, BEiT3) on multiple vision-and-language tasks. In this plot we show the absolute score differences compared with the previous best model to highlight the relative improvements of PaLI. Comparison is on the official test splits when available. CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.
–>
Model Scaling Results We examine how the image and language model components interact with each other with regards to model scaling and where the model yields the most gains. We conclude that scaling both components jointly results in the best performance, and specifically, scaling the visual component, which requires relatively few parameters, is most essential. Scaling is also critical for better performance across multilingual tasks.
Scaling both the language and the visual components of the PaLI model contribute to improved performance. The plot shows the score differences compared to the PaLI-3B model: CIDEr score is used for evaluation of the image captioning tasks, whereas VQA tasks are evaluated by VQA Accuracy.
Multilingual captioning greatly benefits from scaling the PaLI models. We evaluate PaLI on a 35-language benchmark Crossmodal-3600. Here we present the average score over all 35 languages and the individual score for seven diverse languages.
Model Introspection: Model Fairness, Biases, and Other Potential Issues To avoid creating or reinforcing unfair bias within large language and image models, important first steps are to (1) be transparent about the data that were used and how the model used those data, and (2) test for model fairness and conduct responsible data analyses. To address (1), our paper includes a data card and model card. To address (2), the paper includes results of demographic analyses of the dataset. We consider this a first step and know that it will be important to continue to measure and mitigate potential biases as we apply our model to new tasks, in alignment with our AI Principles.
Conclusion We presented PaLI, a scalable multi-modal and multilingual model designed for solving a variety of vision-language tasks. We demonstrate improved performance across visual-, language- and vision-language tasks. Our work illustrates the importance of scale in both the visual and language parts of the model and the interplay between the two. We see that accomplishing vision and language tasks, especially in multiple languages, actually requires large scale models and data, and will potentially benefit from further scaling. We hope this work inspires further research in multi-modal and multilingual models.
Acknowledgements We thank all the authors who conducted this research Soravit (Beer) Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari,Gaurav Mishra, Linting Xue, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu Karagol Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut. We also thank Claire Cui, Slav Petrov, Tania Bedrax-Weiss, Joelle Barral, Tom Duerig, Paul Natsev, Fernando Pereira, Jeff Dean, Jeremiah Harmsen, Zoubin Ghahramani, Erica Moreira, Victor Gomes, Sarah Laszlo, Kathy Meier-Hellstern, Susanna Ricco, Rich Lee, Austin Tarango, Emily Denton, Bo Pang, Wei Li, Jihyung Kil, Tomer Levinboim, Julien Amelot, Zhenhai Zhu, Xiangning Chen, Liang Chen, Filip Pavetic, Daniel Keysers, Matthias Minderer, Josip Djolonga, Ibrahim Alabdulmohsin, Mostafa Dehghani, Yi Tay, Elizabeth Adkison, James Cockerille, Eric Ni, Anna Davies, and Maysam Moussalem for their suggestions, improvements and support. We thank Tom Small for providing visualizations for the blogpost.
There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these…
There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these technologies create the large-scale transformation in healthcare that was expected.
Adopting cutting-edge technologies is not a trivial exercise for healthcare institutions. It requires a balance of legal, clinical, and technical risks against the promise of improved patient outcomes and operational efficiency.
Traditionally, the challenges around the adoption of such technologies fell into one of three buckets: people, platforms, and policy. The challenges around a platform for AI adoption are particularly unique given the nature of deep learning technology and the current state of the medical AI ecosystem.
Most deep learning applications have a narrow field of scope. If they stray beyond their domain, they can exhibit unpredictable and unintuitive behavior. This means that to achieve large-scale transformation in medicine, we need thousands of AI applications.
Each of these AI models in production will be communicating information with live clinical systems and making all kinds of inferences that must then be managed. This has the potential of creating an “AI jungle,” with a huge amount of technical debt in an environment where there hasn’t been substantial investment in people to manage such risks.
Another challenge for deploying AI at scale is the lack of interoperability of AI models. Deployment and data integration don’t scale within or across institutions. This lack of interoperability exists within information systems and semantics and between organizations. The result is a high barrier of entry for data scientists and start-ups who don’t have the capacity or domain knowledge to make an impact.
Finally, in recognition of the immaturity of the medical AI economy relative to other subdomains in MedTech, evidence generation must be at the heart of the design of a platform for AI adoption, as many of the AI applications on the market today still require extensive research and analysis of their performance. This is true not only from the perspective of monitoring but also to measure impact on health outcomes.
AIDE: An enterprise approach to AI deployment in healthcare systems
An AI platform that solves these challenges must solve them at the enterprise level to fully capture the benefits of the ‘virtuous cycle of AI’ and to fully mitigate risks around deployment of artificial intelligence.
This ensures the lowered costs of deployment by plugging into a platform that is already integrated to the clinical information systems within healthcare facilities. It also lowers costs around staff and support by creating an opportunity for a single team to service the entire institution, empowered with an enterprise-wide view for managing risks and continuous improvement.
AIDE, developed by the UK Government-funded AI Centre for Value Based Healthcare, is a new operating system for the hospital that allows healthcare providers to deploy AI models safely, effectively, and efficiently. It provides a harmonized hardware and software layer that facilitates the deployment and use of any AI application.
Figure 1. AIDE can receive a live stream of clinical data, allowing clinicians to access near real-time AI analysis within seconds
There are numerous technical risks involved in deploying a large number of models. AIDE mitigates these by providing an administration view that reports every inference of every deployed model as well as performance trend analysis to enable real-time intervention in the case of poor performance.
AIDE also solves the challenge of interoperability by packaging and deploying containerized applications and communicating with the rest of the hospital through standard protocols such as DICOM, HL7, and FHIR.
Clinicians can also review AI inference results with AIDE before they are sent to the patient’s electronic health record (EHR). This clinical review stage can collect useful data around failure instances, which can be fed back to the developer and close the feedback loop.
An open-source standard for healthcare AI with MONAI Deploy
When considering the wide scale adoption of AI, it is important to first consider, as an analogous example, the discovery of X-rays and the subsequent transformation of healthcare through the development of radiology.
After the discovery by Dr Wilhelm Roentgen in 1895 and the famous X-ray of his wife Bertha’s hand, the first uses of X-ray technology were for industrial applications, such as welding inspection, and consumer applications, such as shoe-fitting, rather than medical applications.
Today, most patient experiences involve medical imaging for diagnosis, prognosis, treatment monitoring and more. Rural medical centers can acquire images in the middle of the night and have them reported within an hour by a specialist in another part of the world.
That kind of transformation was only made possible almost 100 years after the invention of the x-ray when the American College of Radiology and National Electrical Manufacturers Association published a standard for the encoding and transfer of medical images, named “Digital Imaging and Communications in Medicine.”
With the birth of the standard in the early 1990s, a transformational journey had begun that would change what would be possible in the art of medicine, leading to advances in oncology, neurology, and many other medical specialties.
Similarly, with deep learning, industrial and consumer applications have raced ahead while medical applications have had limited adoption and even less transformational impact.
That is why the key innovation in AIDE, as an enterprise AI platform, is that it is built on top of the open-source MONAI Deploy architecture.
MONAI Deploy was built to bridge the gap from research innovation to validation and clinical production environments. It gives developers and researchers a default standard, called MONAI Deploy Application Package (MAP), that easily integrates into health IT standards such as DICOM. It also integrates into deployment options across a variety of data center, cloud, and edge environments, making it easy for you to adopt new medical AI applications.
The MONAI Deploy Working Group has defined an open architecture and standard APIs for developing, packaging, testing, deploying, and running medical AI applications in clinical production.
The high-level architecture includes the following components:
MONAI Application Package (MAP): Defines how applications can be packaged and distributed.
MONAI Informatics Gateway: Communicatesthe clinical information systems and medical devices, such as MRI scanners, over DICOM, FHIR, and HL7 standards.
MONAI Workflow Manager: Orchestrates clinical-inspired workflows, composed of AI tasks.
The system has been designed to allow pluggable execution of tasks by different inference engines. The MONAI community is going to keep moving in that direction as well.
The MONAI Deploy architecture has been co-designed by an international community of hardware, software, academic, and healthcare partners for the mutual aim of standardizing the medical AI lifecycle. This is much in the same way the ACR and NEMA did with medical images three decades ago.
A new era of data-driven medicine
This new layer of informatics, built on top of existing clinical information systems and medical devices, will help usher in the new era of data-driven medicine. For more information about AIDE, see AI Centre for Value Based Healthcare Platforms.
TGIGFNT: thank goodness it’s GFN Thursday. Start your weekend early with seven new games joining the GeForce NOW library of over 1,400 titles. Whether it’s streaming on an older-than-the-dinosaurs PC, a Mac that normally couldn’t dream of playing PC titles, or mobile devices – it’s all possible to play your way thanks to GeForce NOW. Read article >
Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with…
Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with automated code generation, and more.
As consumers expect faster, cheaper deliveries, companies are turning to AI to rethink how they move goods. Foremost among these new systems are “hub-and-spoke,” or middle-mile, operations, where companies place distribution centers closer to retail operations for quicker access to inventory. However, faster delivery is just part of the equation. These systems must also be Read article >
Virtual reality (VR), augmented reality (AR), and mixed reality (MR) environments can feel incredibly real due to the physically immersive experience. Adding a…
Virtual reality (VR), augmented reality (AR), and mixed reality (MR) environments can feel incredibly real due to the physically immersive experience. Adding a voice-based interface to your extended reality (XR) application can make it appear even more realistic.
Imagine using your voice to navigate through an environment or giving a verbal command and hearing a response back from a virtual entity.
The possibilities to harness speech AI in XR environments is fascinating. Speech AI skills, such as automatic speech recognition (ASR) and text-to-speech (TTS), make XR applications enjoyable, easy to use, and more accessible to users with speech impairments.
This post explains how speech recognition, also referred to as speech-to-text (STT), can be used in your XR app, what ASR customizations are available, and how to get started with running ASR services in your Windows applications.
Why add speech AI services to XR applications?
In most of today’s XR experiences, users don’t have access to a keyboard or mouse. The way VR game controllers typically interact with a virtual experience is clumsy and unintuitive, making navigation through menus difficult when you’re immersed in the environment.
When virtually immersed, we want our experience to feel natural, both in how we perceive it and in how we interact with it. Speech is one of the most common interactions that we use in the real world.
Adding speech AI-enabled voice commands and responses to your XR application makes interaction feel much more natural and dramatically simplifies the learning curve for users.
Examples of speech AI-enabled XR applications
Today, there are a wide array of wearable tech devices that enable people to experience immersive realities while using their voice:
AR translation glasses can provide real-time translation in AR or just transcribe spoken audio in AR to help people with hearing impairments.
Branded voices are customized and developed for digital avatars in the metaverse, making the experience more believable and realistic.
Social media platforms provide voice-activated AR filters for ease of search and usability. For instance, Snapchat users can search for their desired digital filter using a hands-free voice scan feature.
VR design review
VR can help businesses save costs by automating a number of tasks in the automotive industry, such as modeling cars, training assembly workers, and driving simulations.
An added speech AI component makes hands-free interactions possible. For example, users can leverage STT skills to give commands to VR apps, and apps can respond in a way that sounds human with TTS.
Figure 1. VR car design review workflow architecture
As shown in Figure 1, a user sends an audio request to a VR application that is then converted to text using ASR. Natural language understanding takes text as an input and generates a response, which is spoken back to the user using TTS.
Developing speech AI pipelines is not as easy as it sounds. Traditionally, there has always been a trade-off between accuracy and real-time response when building pipelines.
This post focuses solely on ASR, and we examine some of today’s available customizations for XR app developers. We also discuss using NVIDIA Riva, a GPU-accelerated speech AI SDK, for building applications customized for specific use cases while delivering real-time performance.
Solve domain– and language-specific challenges with ASR customizations
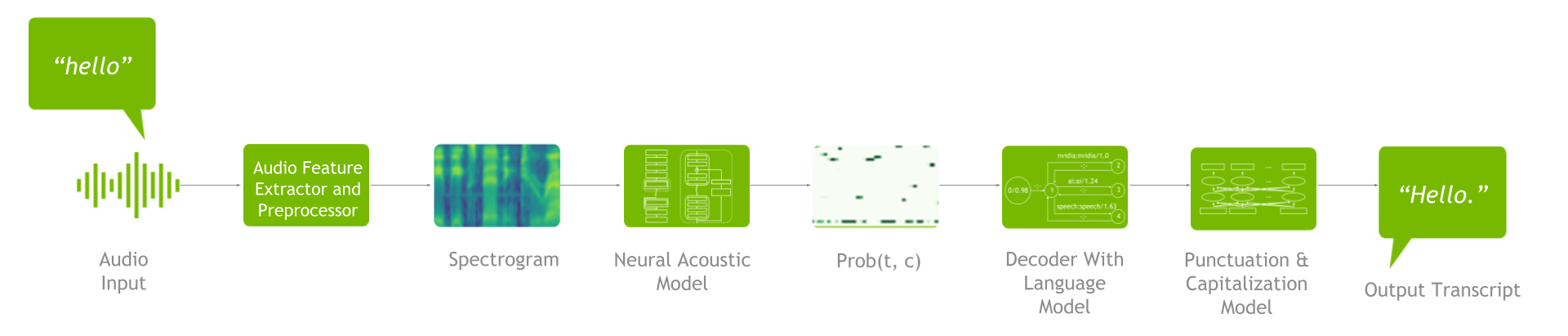
An ASR pipeline includes a feature extractor, acoustic model, decoder or language model, and punctuation and capitalization model (Figure 2).
Figure 2. ASR pipeline
To understand the ASR customizations available, it’s important to grasp the end-to-end process. First, feature extraction takes place to turn raw audio waveforms into spectrograms / mel spectrograms. These spectrograms are then fed into an acoustic model that generates a matrix with probabilities for all the characters at each time step.
Next, the decoder, in conjunction with the language model, uses that matrix as an input to produce a transcript. You can then run the resulting transcript through the punctuation and capitalization model to improve readability.
Advanced speech AI SDKs and workflows, such as Riva, support speech recognition pipeline customization. Customization helps you address several language-specific challenges, such as understanding one or more of the following:
Multiple accents
Word contextualization
Domain-specific jargon
Multiple dialects
Multiple languages
Users in noisy environments
Customizations in Riva can be applied in both the training and inference stages. Starting with training-level customizations, you can fine-tune acoustic models, decoder/language models, and punctuation and capitalization models. This ensures that your pipeline understands different language, dialects, accents, and industry-specific jargon, and is robust to noise.
When it comes to inference-level customizations, you can use word boosting. With word boosting, the ASR pipeline is more likely to recognize certain words of interest by giving them a higher score when decoding the output of the acoustic model.
Get started with integrating ASR services for XR development using NVIDIA Riva
Riva runs as a client-server model. To run Riva, you need access to a Linux server with an NVIDIA GPU, where you can install and run the Riva server (specifics and instructions are provided in this post).
The Riva client API is integrated into your Windows application. At runtime, the Windows client sends Riva requests over the network to the Riva server, and the Riva server sends back replies. A single Riva server can simultaneously support many Riva clients.
ASR services can be run in two different modes:
Offline mode: A complete speech segment is captured, and when complete it is then sent to Riva to be converted to text.
Streaming mode: The speech segment is being streamed to the Riva server in real time, and the text result is being streamed back in real time. Streaming mode is a bit more complicated, as it requires multiple threads.
Examples showing both modes are provided later in this post.
In this section, you learn several ways to integrate Riva into your Windows application:
Python ASR offline client
Python streaming ASR client
C++ offline client using Docker
C++ streaming client
First, here’s how to set up and run the Riva server.
Follow all steps to be able to run ngc commands from a command-line interface (CLI).
Access to NVIDIA Volta, NVIDIA Turing, or an NVIDIA Ampere Architecture-based A100 GPU. Linux servers with NVIDIA GPUs are also available from the major CSPs. For more information, see the support matrix.
Docker installation with support for NVIDIA GPUs. For more information about instructions, see the installation guide.
Follow the instructions to install the NVIDIA Container Toolkit and then the nvidia-docker package.
Server setup
Download the scripts from NGC by running the following command:
ngc registry resource download-version nvidia/riva/riva_quickstart:2.4.0
First, run the following command to install the riva client package. Make sure that you’re using Python version 3.7.
pip install nvidia-riva-client
The following code example runs ASR transcription in offline mode. You must change the server address, give the path to the audio file to be transcribed, and select the language code for your choice. Currently, Riva supports English, Spanish, German, Russian, and Mandarin.
import io
import IPython.display as ipd
import grpc
import riva.client
auth = riva.client.Auth(uri='server address:port number')
riva_asr = riva.client.ASRService(auth)
# Supports .wav file in LINEAR_PCM encoding, including .alaw, .mulaw, and .flac formats with single channel
# read in an audio file from local disk
path = "audio file path"
with io.open(path, 'rb') as fh:
content = fh.read()
ipd.Audio(path)
# Set up an offline/batch recognition request
config = riva.client.RecognitionConfig()
#req.config.encoding = ra.AudioEncoding.LINEAR_PCM # Audio encoding can be detected from wav
#req.config.sample_rate_hertz = 0 # Sample rate can be detected from wav and resampled if needed
config.language_code = "en-US" # Language code of the audio clip
config.max_alternatives = 1 # How many top-N hypotheses to return
config.enable_automatic_punctuation = True # Add punctuation when end of VAD detected
config.audio_channel_count = 1 # Mono channel
response = riva_asr.offline_recognize(content, config)
asr_best_transcript = response.results[0].alternatives[0].transcript
print("ASR Transcript:", asr_best_transcript)
print("nnFull Response Message:")
print(response)
Running the Python streaming ASR client
To run an ASR streaming client, clone the riva python-clients repository and run the file that comes with the repository.
To get the ASR streaming client to work on Windows, clone the repository by running the following command:
Riva_asr_client –riva_url server address:port number –audio_file audio_sample
Running the C++ ASR streaming client
To run the ASR streaming client riva_asr in C++, you must first compile the cpp sample. It is straightforward using CMake, after the following dependencies are met:
gflags
glog
grpc
rtaudio
rapidjson
protobuf
grpc_cpp_plugin
Create a folder /build within the root source folder. From the terminal, type cmake .. and then make. For more information, see the readme file included in the repository.
After the sample is compiled, run it by entering the following command:
riva_asr.exe --riva_uri={riva server url}:{riva server port} --audio_device={Input device name, e.g. "plughw:PCH,0"}
riva_uri:The address:port value of the riva server. By default, the riva server listens to port 50051.
audio_device: The input device (microphone) to be used.
The sample implements essentially four steps. Only a few short examples are shown in this post. For more information, see the file streaming_recognize_client.cc.
Open the input stream using the input (microphone) device specified from the command line. In this case, you are using one channel at 16K samples per second and 16 bits per sample.
Open the grpc communication channel with the Riva server using the protocol api interface specified by the .proto files (in the source in the folder riva/proto):
int StreamingRecognizeClient::DoStreamingFromMicrophone(const std::string& audio_device, bool& request_exit)
{
…
std::shared_ptr call = std::make_shared(1, word_time_offsets_);
call->streamer = stub_->StreamingRecognize(&call->context);
// Send first request
nr_asr::StreamingRecognizeRequest request;
auto streaming_config = request.mutable_streaming_config();
streaming_config->set_interim_results(interim_results_);
auto config = streaming_config->mutable_config();
config->set_sample_rate_hertz(sampleRate);
config->set_language_code(language_code_);
config->set_encoding(encoding);
config->set_max_alternatives(max_alternatives_);
config->set_audio_channel_count(parameters.nChannels);
config->set_enable_word_time_offsets(word_time_offsets_);
config->set_enable_automatic_punctuation(automatic_punctuation_);
config->set_enable_separate_recognition_per_channel(separate_recognition_per_channel_);
config->set_verbatim_transcripts(verbatim_transcripts_);
if (model_name_ != "") {
config->set_model(model_name_);
}
call->streamer->Write(request);
Start sending audio data, received by the microphone to riva through grpc messages:
static int MicrophoneCallbackMain( void *outputBuffer, void *inputBuffer, unsigned int nBufferFrames, double streamTime, RtAudioStreamStatus status, void *userData )
Receive the transcribed audio through grpc answers from the server:
void
StreamingRecognizeClient::ReceiveResponses(std::shared_ptr call, bool audio_device)
{
…
while (call->streamer->Read(&call->response)) { // Returns false when no m ore to read.
call->recv_times.push_back(std::chrono::steady_clock::now());
// Reset the partial transcript
call->latest_result_.partial_transcript = "";
call->latest_result_.partial_time_stamps.clear();
bool is_final = false;
for (int r = 0; r response.results_size(); ++r) {
const auto& result = call->response.results(r);
if (result.is_final()) {
is_final = true;
}
…
call->latest_result_.audio_processed = result.audio_processed();
if (print_transcripts_) {
call->AppendResult(result);
}
}
if (call->response.results_size() && interim_results_ && print_transcripts_) {
std::cout latest_result_.final_transcripts[0] +
call->latest_result_.partial_transcript
recv_final_flags.push_back(is_final);
}
Resources for developing speech AI applications
By recognizing your voice or carrying out a command, speech AI is expanding from empowering actual humans in contact centers to empowering digital humans in the metaverse.
For more information about how to add speech AI skills to your applications, see the following resources
Access beginner and advanced scripts in the /nvidia-riva/tutorials GitHub repo to try out ASR and TTS augmentations such as ASR word boosting and adjusting TTS pitch, rate, and pronunciation settings.
Learn how to add ASR or TTS services to your specific use case by downloading the free ebook, Building Speech AI Applications.
AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area…
AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area to drive efficiency is using lower precision number formats to improve computational efficiency, reduce memory usage, and optimize for interconnect bandwidth.
To realize these benefits, the industry has moved from 32-bit precisions to 16-bit, and now even 8-bit precision formats. Transformer networks, which are one of the most important innovations in AI, benefit from an 8-bit floating point precision in particular. We believe that having a common interchange format will enable rapid advancements and the interoperability of both hardware and software platforms to advance computing.
NVIDIA, Arm, and Intel have jointly authored a whitepaper, FP8 Formats for Deep Learning, describing an 8-bit floating point (FP8) specification. It provides a common format that accelerates AI development by optimizing memory usage and works for both AI training and inference. This FP8 specification has two variants, E5M2 and E4M3.
This format is natively implemented in the NVIDIA Hopper architecture and has shown excellent results in initial testing. It will immediately benefit from the work being done by the broader ecosystem, including the AI frameworks, in implementing it for developers.
Compatibility and flexibility
FP8 minimizes deviations from existing IEEE 754 floating point formats with a good balance between hardware and software to leverage existing implementations, accelerate adoption, and improve developer productivity.
E5M2 uses five bits for the exponent and two bits for the mantissa and is a truncated IEEE FP16 format. In circumstances where more precision is required at the expense of some numerical range, the E4M3 format makes a few adjustments to extend the range representable with a four-bit exponent and a three-bit mantissa.
The new format saves additional computational cycles since it uses just eight bits. It can be used for both AI training and inference without requiring any re-casting between precisions. Furthermore, by minimizing deviations from existing floating point formats, it enables the greatest latitude for future AI innovation while still adhering to current conventions.
High-accuracy training and inference
Testing the proposed FP8 format shows comparable accuracy to 16-bit precisions across a wide array of use cases, architectures, and networks. Results on transformers, computer vision, and GAN networks all show that FP8 training accuracy is similar to 16-bit precisions while delivering significant speedups. For more information about accuracy studies, see the FP8 Formats for Deep Learning whitepaper.
Figure 1. Language model AI training
In Figure 1, different networks use different accuracy metrics (PPL and Loss), as indicated.
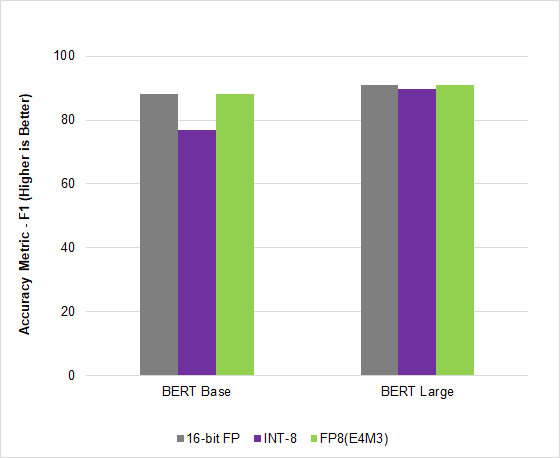
Figure 2. Language model AI inference
In MLPerf Inference v2.1, the AI industry’s leading benchmark, NVIDIA Hopper leveraged this new FP8 format to deliver a 4.5x speedup on the BERT high-accuracy model, gaining throughput without compromising on accuracy.
Moving towards standardization
NVIDIA, Arm, and Intel have published this specification in an open, license-free format to encourage broad industry adoption. They will also submit this proposal to IEEE.
By adopting an interchangeable format that maintains accuracy, AI models will operate consistently and performantly across all hardware platforms, and help advance the state of the art of AI.
Standards bodies and the industry as a whole are encouraged to build platforms that can efficiently adopt the new standard. This will help accelerate AI development and deployment by providing a universal, interchangeable precision.








 Learn about new CUDA features, digital twins for weather and climate, quantum circuit simulations, and much more with these GTC 2022 sessions.
Learn about new CUDA features, digital twins for weather and climate, quantum circuit simulations, and much more with these GTC 2022 sessions.  There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these…
There is an abundance of market-approved medical AI software that can be used to improve patient care and hospital operations, but we have not yet seen these…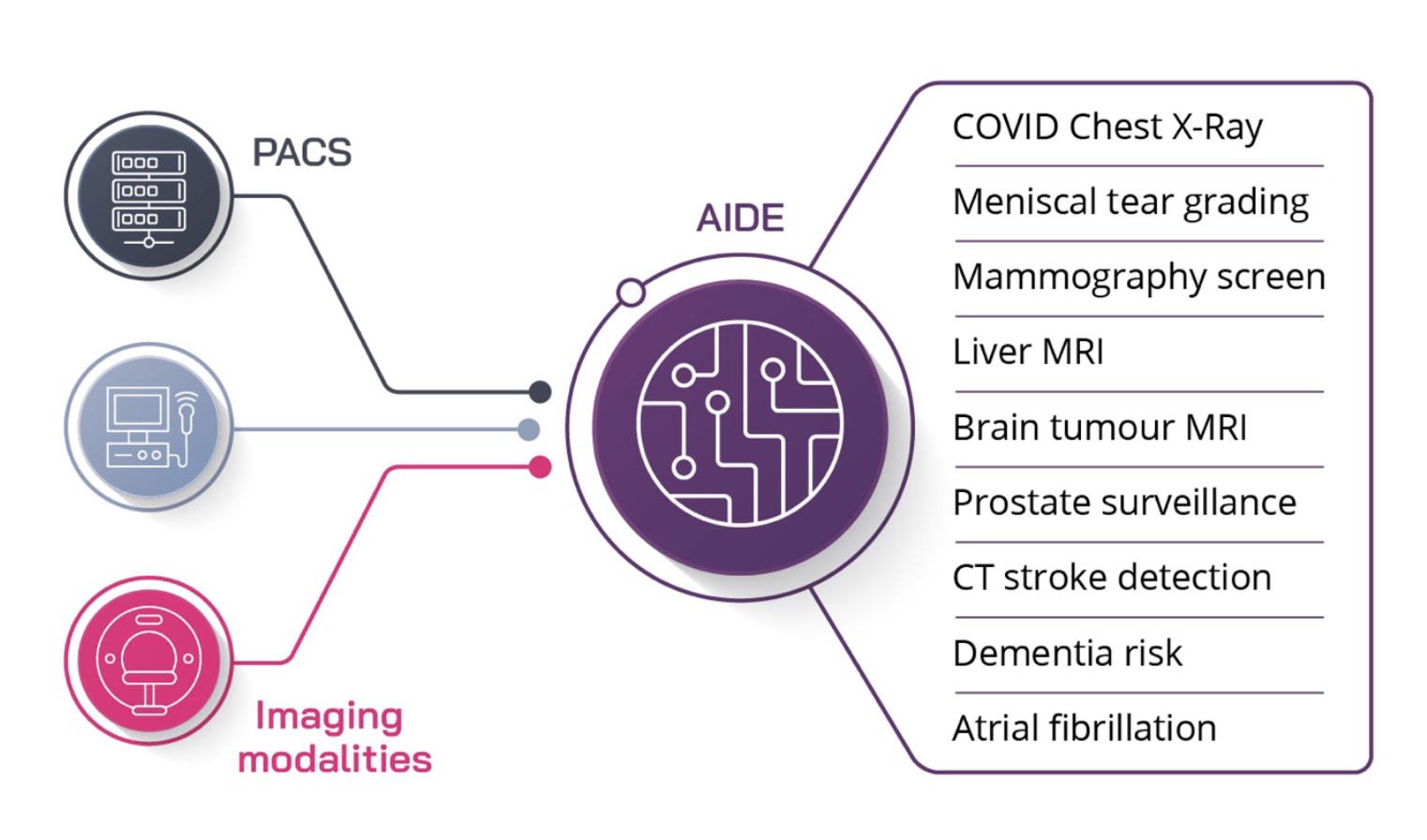
 Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with…
Join us for these featured GTC 2022 sessions to learn about optimizing PyTorch models, accelerating graph neural networks, improving GPU performance with… An exaflop is a measure of performance for a supercomputer that can calculate at least one quintillion floating point operations per second.
An exaflop is a measure of performance for a supercomputer that can calculate at least one quintillion floating point operations per second. Virtual reality (VR), augmented reality (AR), and mixed reality (MR) environments can feel incredibly real due to the physically immersive experience. Adding a…
Virtual reality (VR), augmented reality (AR), and mixed reality (MR) environments can feel incredibly real due to the physically immersive experience. Adding a…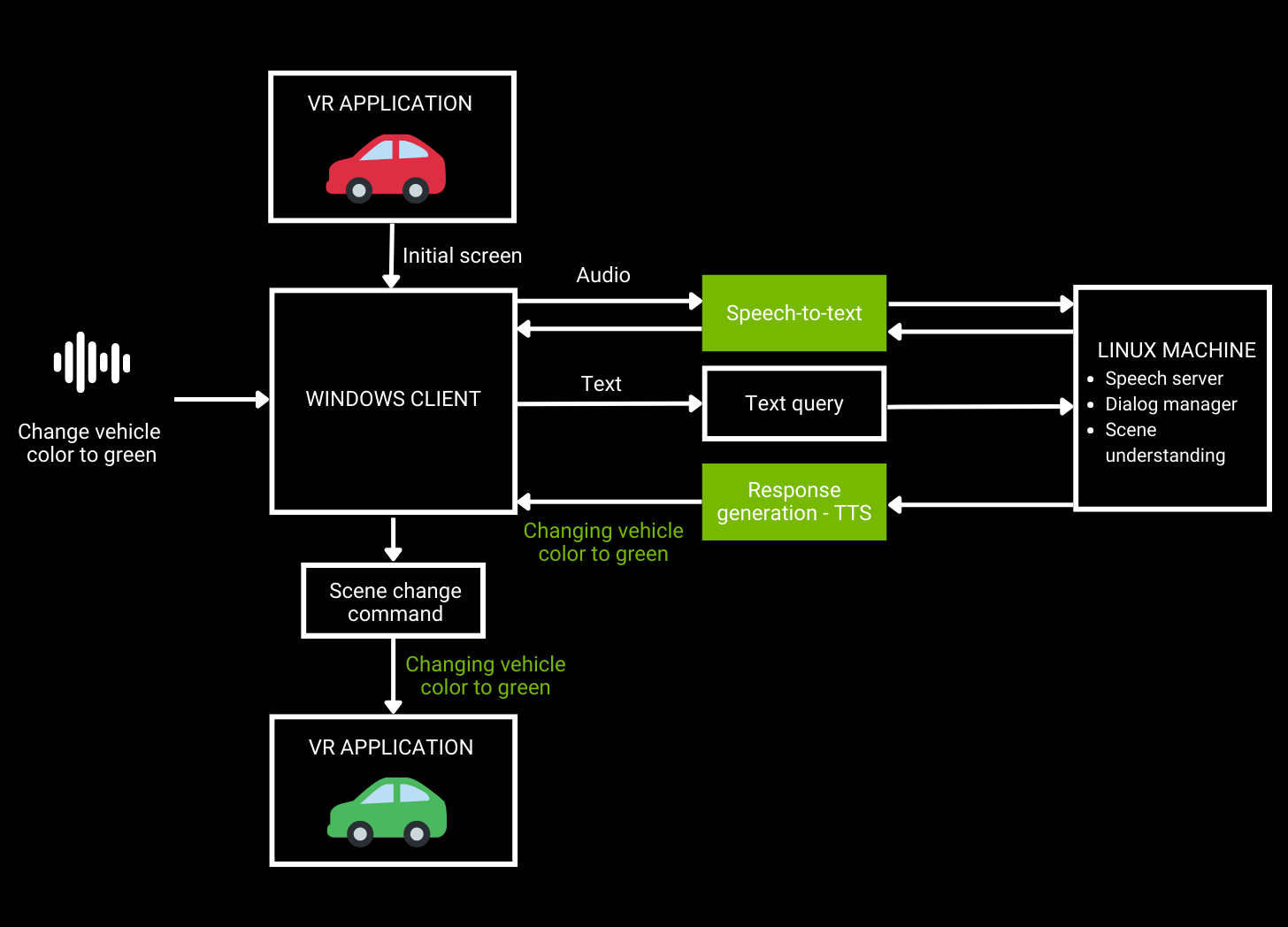
 AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area…
AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area…