Join us on October 4 to explore new features in JetPack 5.0.2. Learn how to develop for any Jetson Orin module using emulation support on the Jetson AGX Orin…
Join us on October 4 to explore new features in JetPack 5.0.2. Learn how to develop for any Jetson Orin module using emulation support on the Jetson AGX Orin Developer Kit.
Learn the basics of physics-informed deep learning and how to use NVIDIA Modulus, the physics machine learning platform, in this self-paced online course.
Learn the basics of physics-informed deep learning and how to use NVIDIA Modulus, the physics machine learning platform, in this self-paced online course.
The massive virtual worlds created by growing numbers of companies and creators could be more easily populated with a diverse array of 3D buildings, vehicles, characters and more — thanks to a new AI model from NVIDIA Research. Trained using only 2D images, NVIDIA GET3D generates 3D shapes with high-fidelity textures and complex geometric details. Read article >
Posted by Jeremy Maitin-Shepard and Laramie Leavitt, Software Engineers, Connectomics at Google
Many exciting contemporary applications of computer science and machine learning (ML) manipulate multidimensional datasets that span a single large coordinate system, for example, weather modeling from atmospheric measurements over a spatial grid or medical imaging predictions from multi-channel image intensity values in a 2d or 3d scan. In these settings, even a single dataset may require terabytes or petabytes of data storage. Such datasets are also challenging to work with as users may read and write data at irregular intervals and varying scales, and are often interested in performing analyses using numerous machines working in parallel.
Today we are introducing TensorStore, an open-source C++ and Python software library designed for storage and manipulation of n-dimensional data that:
Provides a uniform API for reading and writing multiple array formats, including zarr and N5.
Supports safe, efficient access from multiple processes and machines via optimistic concurrency.
Offers an asynchronous API to enable high-throughput access even to high-latency remote storage.
Provides advanced, fully composable indexing operations and virtual views.
TensorStore has already been used to solve key engineering challenges in scientific computing (e.g., management and processing of large datasets in neuroscience, such as peta-scale 3d electron microscopy data and “4d” videos of neuronal activity). TensorStore has also been used in the creation of large-scale machine learning models such as PaLM by addressing the problem of managing model parameters (checkpoints) during distributed training.
Familiar API for Data Access and Manipulation TensorStore provides a simple Python API for loading and manipulating large array data. In the following example, we create a TensorStore object that represents a 56 trillion voxel 3d image of a fly brain and access a small 100×100 patch of the data as a NumPy array:
>>> import tensorstore as ts >>> import numpy as np
# Create a TensorStore object to work with fly brain data. >>> dataset = ts.open({ ... 'driver': ... 'neuroglancer_precomputed', ... 'kvstore': ... 'gs://neuroglancer-janelia-flyem-hemibrain/v1.1/segmentation/', ... }).result()
# Convert a 100x100x1 slice of the data to a numpy ndarray >>> slice = np.array(dataset_3d[15000:15100, 15000:15100, 20000])
Crucially, no actual data is accessed or stored in memory until the specific 100×100 slice is requested; hence arbitrarily large underlying datasets can be loaded and manipulated without having to store the entire dataset in memory, using indexing and manipulation syntax largely identical to standard NumPy operations. TensorStore also provides extensive support for advanced indexing features, including transforms, alignment, broadcasting, and virtual views (data type conversion, downsampling, lazily on-the-fly generated arrays).
The following example demonstrates how TensorStore can be used to create a zarr array, and how its asynchronous API enables higher throughput:
>>> import tensorstore as ts >>> import numpy as np
>>> # Create a zarr array on the local filesystem >>> dataset = ts.open({ ... 'driver': 'zarr', ... 'kvstore': 'file:///tmp/my_dataset/', ... }, ... dtype=ts.uint32, ... chunk_layout=ts.ChunkLayout(chunk_shape=[256, 256, 1]), ... create=True, ... shape=[5000, 6000, 7000]).result()
>>> # Create two numpy arrays with example data to write. >>> a = np.arange(100*200*300, dtype=np.uint32).reshape((100, 200, 300)) >>> b = np.arange(200*300*400, dtype=np.uint32).reshape((200, 300, 400))
>>> # Initiate two asynchronous writes, to be performed concurrently. >>> future_a = dataset[1000:1100, 2000:2200, 3000:3300].write(a) >>> future_b = dataset[3000:3200, 4000:4300, 5000:5400].write(b)
>>> # Wait for the asynchronous writes to complete >>> future_a.result() >>> future_b.result()
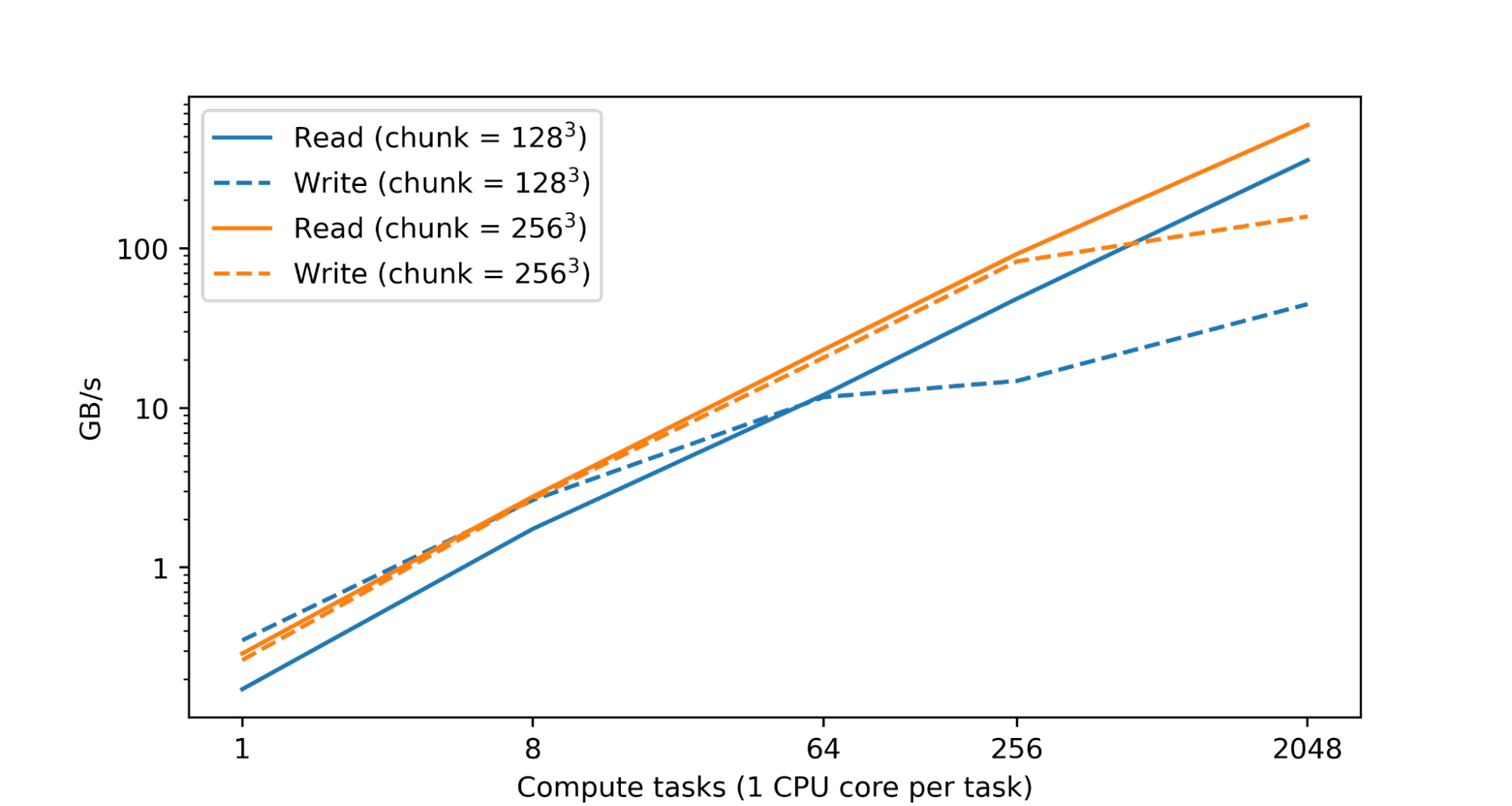
Safe and Performant Scaling Processing and analyzing large numerical datasets requires significant computational resources. This is typically achieved through parallelization across numerous CPU or accelerator cores spread across many machines. Therefore a fundamental goal of TensorStore has been to enable parallel processing of individual datasets that is both safe (i.e., avoids corruption or inconsistencies arising from parallel access patterns) and high performance (i.e., reading and writing to TensorStore is not a bottleneck during computation). In fact, in a test within Google’s datacenters, we found nearly linear scaling of read and write performance as the number of CPUs was increased:
Read and write performance for a TensorStore dataset in zarr format residing on Google Cloud Storage (GCS) accessed concurrently using a variable number of single-core compute tasks in Google data centers. Both read and write performance scales nearly linearly with the number of compute tasks.
Performance is achieved by implementing core operations in C++, extensive use of multithreading for operations such as encoding/decoding and network I/O, and partitioning large datasets into much smaller units through chunking to enable efficiently reading and writing subsets of the entire dataset. TensorStore also provides configurable in-memory caching (which reduces slower storage system interactions for frequently accessed data) and an asynchronous API that enables a read or write operation to continue in the background while a program completes other work.
Safety of parallel operations when many machines are accessing the same dataset is achieved through the use of optimistic concurrency, which maintains compatibility with diverse underlying storage layers (including Cloud storage platforms, such as GCS, as well as local filesystems) without significantly impacting performance. TensorStore also provides strong ACID guarantees for all individual operations executing within a single runtime.
To make distributed computing with TensorStore compatible with many existing data processing workflows, we have also integrated TensorStore with parallel computing libraries such as Apache Beam (example code) and Dask (example code).
Use Case: Language Models An exciting recent development in ML is the emergence of more advanced language models such as PaLM. These neural networks contain hundreds of billions of parameters and exhibit some surprising capabilities in natural language understanding and generation. These models also push the limits of computational infrastructure; in particular, training a language model such as PaLM requires thousands of TPUs working in parallel.
One challenge that arises during this training process is efficiently reading and writing the model parameters. Training is distributed across many separate machines, but parameters must be regularly saved to a single object (“checkpoint”) on a permanent storage system without slowing down the overall training process. Individual training jobs must also be able to read just the specific set of parameters they are concerned with in order to avoid the overhead that would be required to load the entire set of model parameters (which could be hundreds of gigabytes).
TensorStore has already been used to address these challenges. It has been applied to manage checkpoints associated with large-scale (“multipod”) models trained with JAX (code example) and has been integrated with frameworks such as T5X (code example) and Pathways. Model parallelism is used to partition the full set of parameters, which can occupy more than a terabyte of memory, over hundreds of TPUs. Checkpoints are stored in zarr format using TensorStore, with a chunk structure chosen to allow the partition for each TPU to be read and written independently in parallel.
When saving a checkpoint, each model parameter is written using TensorStore in zarr format using a chunk grid that further subdivides the grid used to partition the parameter over TPUs. The host machines write in parallel the zarr chunks for each of the partitions assigned to TPUs attached to that host. Using TensorStore’s asynchronous API, training proceeds even while the data is still being written to persistent storage. When resuming from a checkpoint, each host reads only the chunks that make up the partitions assigned to that host.
Use Case: 3D Brain Mapping The field of synapse-resolution connectomics aims to map the wiring of animal and human brains at the detailed level of individual synaptic connections. This requires imaging the brain at extremely high resolution (nanometers) over fields of view of up to millimeters or more, which yields datasets that can span petabytes in size. In the future these datasets may extend to exabytes as scientists contemplate mapping entire mouse or primate brains. However, even current datasets pose significant challenges related to storage, manipulation, and processing; in particular, even a single brain sample may require millions of gigabytes with a coordinate system (pixel space) of hundreds of thousands pixels in each dimension.
We have used TensorStore to solve computational challenges associated with large-scale connectomic datasets. Specifically, TensorStore has managed some of the largest and most widely accessed connectomic datasets, with Google Cloud Storage as the underlying object storage system. For example, it has been applied to the human cortex “h01” dataset, which is a 3d nanometer-resolution image of human brain tissue. The raw imaging data is 1.4 petabytes (roughly 500,000 * 350,000 * 5,000 pixels large, and is further associated with additional content such as 3d segmentations and annotations that reside in the same coordinate system. The raw data is subdivided into individual chunks 128x128x16 pixels large and stored in the “Neuroglancer precomputed” format, which is optimized for web-based interactive viewing and can be easily manipulated from TensorStore.
Autonomous vehicle sensors require the same rigorous testing and validation as the car itself, and one simulation platform is up to the task. Global tier-1 supplier Continental and software-defined lidar maker AEye announced this week at NVIDIA GTC that they will migrate their intelligent lidar sensor model into NVIDIA DRIVE Sim. The companies are the Read article >
When it rains, it pours. And this GFN Thursday brings a downpour of news for GeForce NOW members. The Logitech G CLOUD is the latest gaming handheld device to support GeForce NOW, giving members a brand new way to keep the gaming going. But that’s not all: Portal with RTX joins GeForce NOW in November, Read article >
Announced at GTC 2022, the next generation of NVIDIA GPUs—the NVIDIA GeForce RTX 40 series, NVIDIA RTX 6000 Ada Generation, and NVIDIA L40 for data…
Announced at GTC 2022, the next generation of NVIDIA GPUs—the NVIDIA GeForce RTX 40 series, NVIDIA RTX 6000 Ada Generation, and NVIDIA L40 for data center—are built with the new NVIDIA Ada Architecture.
The NVIDIA Ada Architecture features third-generation ray tracing cores, fourth-generation Tensor Cores, multiple video encoders, and a new optical flow accelerator.
To enable you to fully harness the new hardware upgrades, NVIDIA is announcing accompanying updates to the Video Codec SDK and Optical Flow SDK.
NVIDIA Video Codec SDK 12.0
AV1 is the state-of-the-art video coding format that offers both substantial performance boosts and higher fidelity compared to H.264, the popular standard. Introduced on the NVIDIA Ampere Architecture, the Video Codec SDK extended support to AV1 decoding. Now, with Video Codec SDK 12.0, NVIDIA Ada-generation GPUs support AV1 encoding.
Figure 1. PSNR compared to bit rate for AV1 and H.264
Hardware-accelerated AV1 encoding is a huge milestone in transitioning AV1 to be the new standard video format. Figure 1 shows how the AV1 bit-rate savings translate into impressive performance boosts and higher fidelity images.
PSNR (peak signal to noise ratio) is a video quality measure. To achieve 42 dB PSNR, AV1 video has a 7 Mbps bit rate while H.264 has upwards of 12 Mbps. Across all resolutions, AV1 encoding averages 40% more efficient than H.264. This fundamental performance difference opens the doors for AV1 to support higher-quality video, increased throughput, and high dynamic range (HDR).
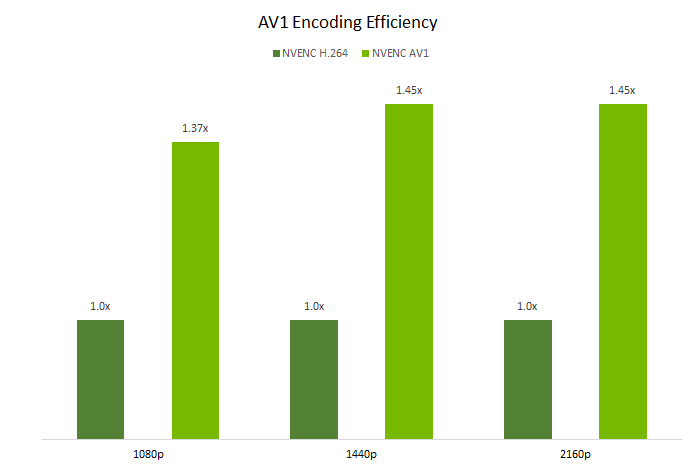
Figure 2. Bit-rate saving for AV1 compared to H.264
As Figure 2 shows, at 1440p and 2160p, NVENC AV1 is 1.45x more efficient than NVENC H.264. This new performance headroom enables higher than ever image quality, including 8k.
The benefits of AV1 are best used in unison with the multi-encoder design featured on the NVIDIA Ada Architecture. New to Video Codec SDK 12.0 on chips with multiple NVENC, the processing load is evenly distributed across each encoder simultaneously. This optimization creates a huge reduction in encoding times. Multiple encoders in combination with the AV1 format allows NVIDIA Ada to support an incredible 8k at 60 fps video encode in real time.
AV1 encoding across multiple hardware NVENC is enabling the next generation of video performance and fidelity. Broadcasters can achieve higher livestream resolutions, video editors can export video at 2x speed, and all this is enabled by the Video Codec SDK.
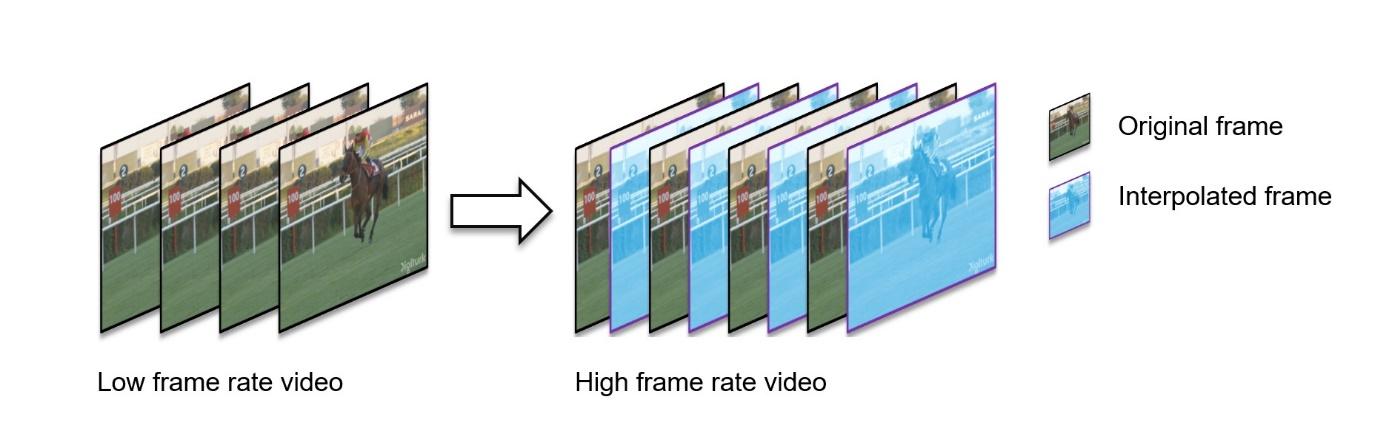
The new NVIDIA Optical Flow SDK 4.0 release introduces an engine-assisted frame rate up conversion (FRUC). FRUC generates higher frame-rate video from lower frame-rate video by inserting interpolated frames using optical flow vectors. Such high frame rate video shows smooth continuity of motion across frames. The result is improved smoothness of video playback and perceived visual quality.
The NVIDIA Ada Lovelace Architecture has a new optical flow accelerator, NVOFA, that is 2.5x more performant than the NVIDIA Ampere Architecture NVOFA. It provides a 15% quality improvement on popular benchmarks including KITTI and MPI Sintel.
The FRUC library uses the NVOFA and CUDA to interpolate frames significantly faster than software-only methods. It also works seamlessly with custom DirectX or CUDA applications, making it easy for developers to integrate.
Figure 3. Frame rate up conversion
The Optical Flow SDK 4.0 includes the FRUC library and sample application, in addition to basic Optical Flow sample applications. The FRUC library exposes NVIDIA FRUC APIs that take two consecutive frames and return an interpolated frame in between them. These APIs can be used for the up-conversion of any video.
Frame interpolation using the FRUC library is extremely fast compared to other software-only methods. The APIs are easy to use, and support ARGB and NV12 input surface formats. It can be directly integrated into any DirectX or CUDA application.
The sample application source code included in the SDK demonstrates how to use FRUC APIs for video FRUC. This source code can be reused or modified as required to build a custom application.
The Video 1 sample was created using the FRUC library. As you can see, the motion of foreground objects and background appears much smoother in the right video compared to the left video.
Video 1. Side-by-side comparison of original video and frame rate up-converted video. (left) Original video played at 15 fps. (right) Frame rate up-converted video played at 30 fps. Video created using the FRUC library. (Source: http://ultravideo.fi/#testsequences)
Inside the FRUC library
Here is a brief explanation about how FRUC library processes a pair of frames and generates an interpolated frame.
A pair of consecutive frames (previous and next) are input into the FRUC library (Figure 4).
Figure 4. Consecutive frames used as input
Using NVIDIA Optical flow APIs, forward and backward flow vector maps are generated.
Figure 5. Forward and backward flow vector maps
Flow vectors in the map are then validated using a forward-backward consistency check. Flow vectors that do not pass the consistency check are rejected. The black portions in this figure are flow vectors that did not pass the forward-backward consistency check.
Figure 6. Validated and rejected flow vectors
Using available flow vectors and advanced CUDA accelerated techniques, more accurate flow vectors are generated to fill in the rejected flow vectors. Figure 7 shows the infilled flow vector map generated.
Figure 7. Infilled flow vector map
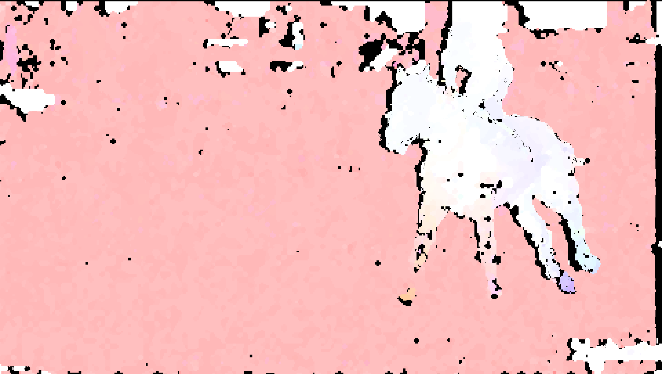
Figure 8. New interpolated frame with gray regions
Using a complete flow vector map between the two frames, the algorithm generates an interpolated frame between the two input frames. Such an image may contain few holes (pixels that don’t have valid color). This figure shows a few small gray regions near the head of the horse and in the sky that are holes.
Holes in the interpolated frame are filled using image domain hole infilling techniques to generate the final interpolated image. This is the output of the FRUC library.
Figure 9. Output of the FRUC library
The calling application can interleave this interpolated frame with original frames to increase the frame rate of video or game. Figure 10 shows the interpolated frame interleaved between previous and next image.
Figure 10. Interpolated frame interleaved
Lastly, to expand the platforms that can harness the NVOFA hardware, Optical Flow SDK 4.0 also introduces support for Windows Subsystem for Linux.
With the Jetson Orin Nano announcement this week at GTC, the entire Jetson Orin module lineup is now revealed. With up to 40 TOPS of AI performance, Orin Nano…
With the Jetson Orin Nano announcement this week at GTC, the entire Jetson Orin module lineup is now revealed. With up to 40 TOPS of AI performance, Orin Nano modules set the new standard for entry-level AI, just as Jetson AGX Orin is already redefining robotics and other autonomous edge use cases with 275 TOPS of server class compute.
All Jetson Orin modules and the Jetson AGX Orin Developer Kit are based on a single SoC architecture with an NVIDIA Ampere Architecture GPU, a high-performance CPU, and the latest accelerators. This shared architecture means you can develop software for one Jetson Orin module and then easily deploy it to any of the others.
You can begin development today for any Jetson Orin module using the Jetson AGX Orin Developer Kit. The developer kit’s ability to natively emulate performance for any of the modules lets you start now and shorten your time to market. The developer kit can accurately emulate the performance of any Jetson Orin modules by configuring the hardware features and clocks to match that of the target module.
Development teams benefit from the simplicity of needing only one type of developer kit, irrespective of which modules are targeted for production. This also simplifies CI/CD infrastructure. Whether you are developing for robotics, video analytics, or any other use case, the capability of this one developer kit brings many benefits.
Transform the Jetson AGX Orin Developer Kit into any Jetson Orin module
With one step, you can transform a Jetson AGX Orin Developer Kit into any one of the Jetson Orin modules. We provide flashing configuration files for this process.
Emulating Jetson Orin module on the Jetson AGX Orin Developer Kit, follows the same steps as mentioned in to flash a Jetson AGX Orin Developer Kit using the flashing utilities. After placing your developer kit in Force Recovery Mode, the flash.sh command-line tool is used to flash it with a new image. For example, the following command flashes the developer kit with its default configuration:
The exact command that you use should be modified with the name of the flash configuration appropriate for your targeted Jetson Orin module being emulated. For example, to emulate a Jetson Orin NX 16GB module, use the following command:
Table 1. Flash.sh commands for Jetson Orin modules
Flash configurations for Jetson Orin Nano modules are not yet included in NVIDIA JetPack, as of version 5.0.2. Use these new configurations after downloading them and applying an overlay patch on top of NVIDIA JetPack 5.0.2 per the instructions found inside the downloaded file.
After flashing is complete, complete the initial bootup and configuration. Then you can install the rest of the NVIDIA JetPack components using SDK Manager or simply by using a package manager on the running developer kit:
sudo apt update
sudo apt install nvidia-jetpack
Now you have the developer kit running and NVIDIA JetPack installed. Your Jetson AGX Orin Developer Kit now emulates the performance and power of the specified Jetson Orin module.
Accurately emulate any Jetson Orin module
This native emulation is accurate because it configures the developer kit to match the clock frequencies, number of GPU and CPU cores, and hardware accelerators available with the target module.
For example, when emulating the Jetson Orin NX 16GB module:
The developer kit GPU is configured with 1024 CUDA cores and 32 Tensor Cores with a max frequency of 918 MHz.
The CPU complex is configured with eight Arm Cortex-A78AE cores running at 2 GHz.
The DRAM is configured to 16 GB with a bandwidth of 102 GB/s.
The system offers the same power profiles supported by the Jetson Orin NX 16GB module.
Figure 1. Available power modes
Open the Jetson Power graphical user interface from the top menu on the desktop and you see that the system has been configured accurately as per the target module being emulated. Max clocks can be configured by running the following command, and the Jetson Power graphical user interface will show the change.
sudo jetson_clocks
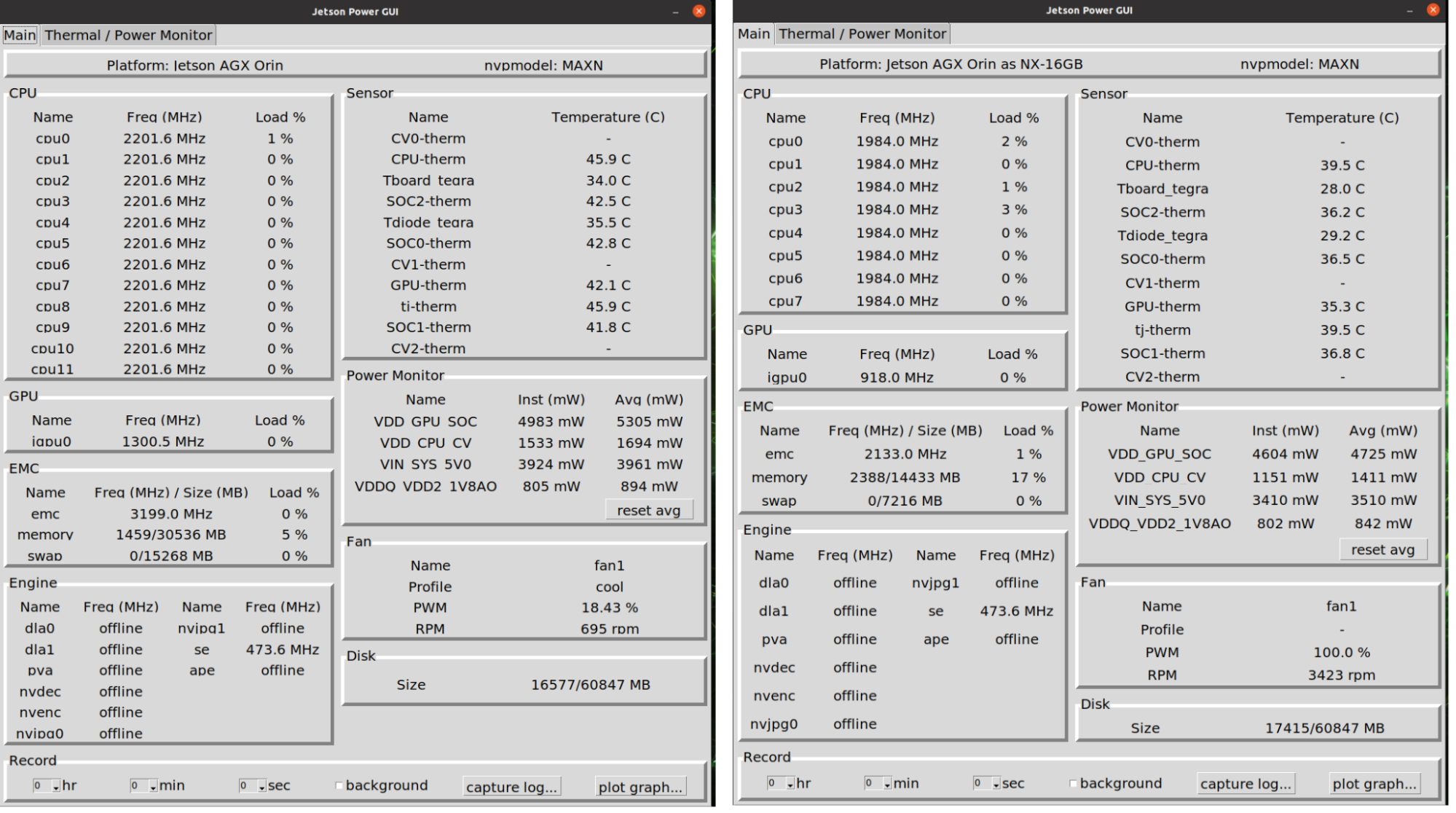
Figure 2 shows the Jetson Power graphical user interface after configuring max clocks when the Jetson AGX Orin Developer Kit is flashed to an emulated Jetson AGX Orin 64GB module compared to when flashed to emulate a Jetson Orin NX 16GB module.
Figure 2. Jetson Power graphical user interface shown on a developer kit flashed to emulate Jetson AGX Orin 64GB (left) and Jetson Orin NX 16GB with MAXN power mode selected (right)
By running various samples provided with NVIDIA JetPack, you can see that the performance is adjusted to match that of the module being emulated. For example, the benchmarking sample packaged with the VPI library can be used to show CPU, GPU, and PVA performance for Jetson AGX Orin 64GB, Jetson Orin NX 16GB, and Jetson Orin Nano 8GB modules after configuring the Jetson AGX Orin Developer Kit to emulate the respective module.
To run the VPI benchmarking sample, use the following commands:
cd /opt/nvidia/vpi2/samples/05-benchmark
sudo cmake .
sudo make
sudo ./vpi_sample_05_benchmark
The VPI benchmarking sample outputs the latency in milliseconds for the Gaussian algorithm. Table 2 shows the results for each of the targeted modules.
Table 2. Latency in milliseconds for targeted modules
Similarly, you can run multimedia samples for encode and decode.
For decode, run the following commands:
cd /usr/src/jetson_multimedia_api/samples/00_video_decode
sudo make
sudo ./video_decode H264 --disable-rendering --stats --max-perf
For encode, run the following commands:
cd /usr/src/jetson_multimedia_api/samples/01_video_encode
sudo make
sudo ./video_encode input.yuv 1920 1080 H264 out.h264 -fps 30 1 -ifi 1000 -idri 1000 --max-perf --stats
Table 3 reports the FPS numbers after running these encode and decode samples using H.264 1080P 30FPS video streams.
Encode/Decoder Sample
Emulated as Jetson AGX Orin 64GB
Emulated as Jetson Orin NX 16GB
Emulated as Jetson Orin Nano 8GB
Encode
178
142
110*
Decode
400
374
231
Table 3. FPS numbers after running encode and decode samples
*Jetson Orin Nano does not include a NVEncoder. For Table 3, encoding for Jetson Orin Nano was done on CPU using ffmpeg. 110 FPS is achieved when using four CPU cores. When using two CPU cores, FPS of 73 was achieved, and when using a single CPU core, FPS of 33 was achieved.
To demonstrate the accuracy of emulation, we ran some AI model benchmarks on the Jetson AGX Orin Developer Kit emulated as Jetson AGX Orin 32GB. We then compared it with results obtained by running the same benchmarks on the real Jetson AGX Orin 32GB module. As you can see from the results, the difference between emulated and real performance is insignificant.
Although Jetson AGX Orin Developer Kit includes a 32GB module, it provides the same level of performance and comes with 275 TOPS matching the Jetson AGX Orin 64GB. There is no special flashing configuration required for emulation of Jetson AGX Orin 64 GB but you must use the appropriate flashing configuration to emulate Jetson AGX Orin 32GB on Jetson AGX Orin Developer Kit.
Model
Jetson AGX Orin 32GB Emulated
Jetson AGX Orin 32GB Real
PeopleNet (V2.5)
327
320
Action Recognition 2D
1161
1151
Action Recognition 3D
70
71
LPR Net
2776
2724
Dashcam Net
1321
1303
BodyPose Net
359
363
Table 4. Performance comparison between real and emulated Jetson AGX Orin modules
Do end-to-end development for any Jetson Orin module
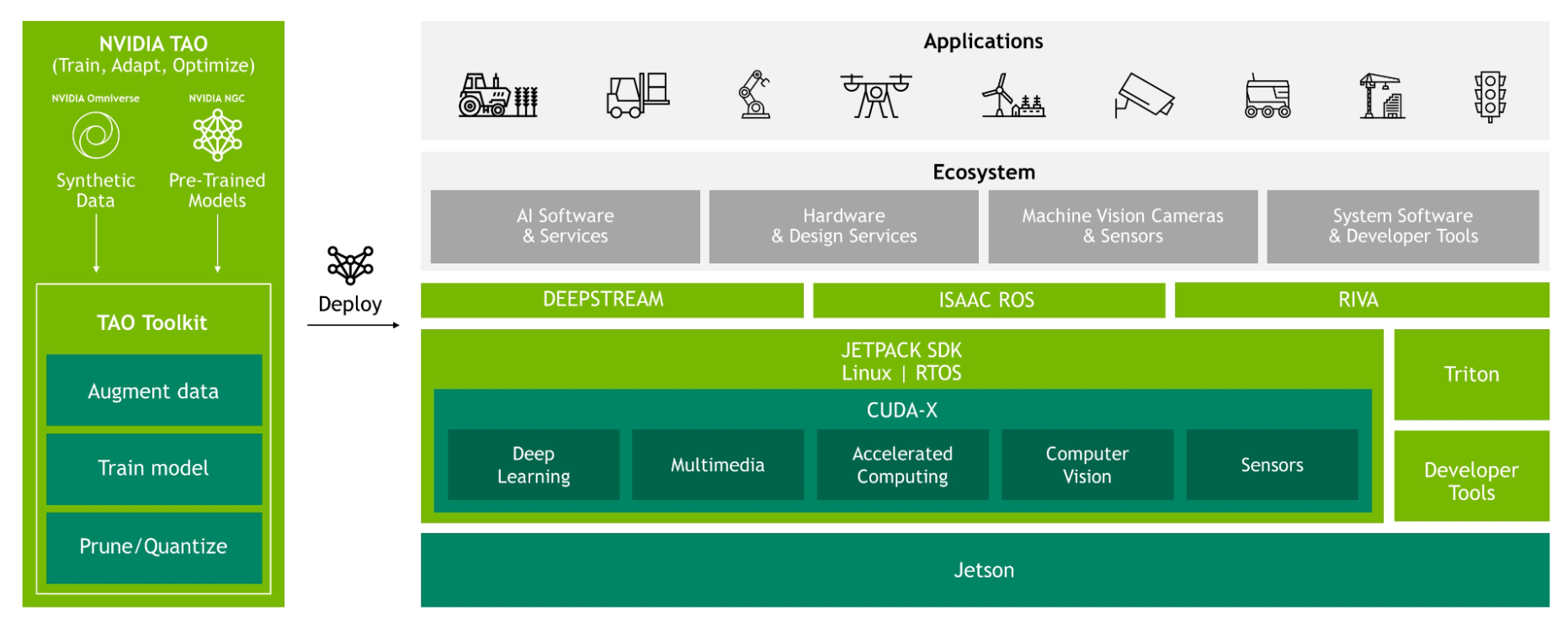
You can work with the entire Jetson software stack while emulating a Jetson Orin module. Frameworks such as NVIDIA DeepStream, NVIDIA Isaac, and NVIDIA Riva work in emulation mode, and tools like TAO Toolkit perform as expected with pretrained models from NGC. The software stack is agnostic of the emulation and the performance accurately matches that of the target being emulated.
Figure 4. NVIDIA Jetson software stack
If you are developing a robotics use case or developing a vision AI pipeline, you can do end-to-end development today for any Jetson Orin module using the Jetson AGX Orin Developer Kit and emulation mode.
Develop robotics applications with NVIDIA Isaac ROS for any Jetson Orin module. Just use the right flashing configuration to flash and start your ROS development. Figure 5 shows running Isaac ROS Stereo Disparity DNN on the Jetson AGX Orin Developer Kit emulated as Jetson Orin Nano 8GB.
Figure 5. NVIDIA Isaac ROS Stereo Disparity DNN running on Jetson AGX Orin Developer Kit emulated as Jetson Orin Nano 8GB
Develop vision AI pipelines using DeepStream on the Jetson AGX Orin Developer Kit for any Jetson Orin module. It just works!
Figure 6 shows an IVA pipeline running people detection using DeepStream on the Jetson AGX Orin Developer Kit emulated as Jetson Orin Nano 8GB with four streams of H.265 1080P 30FPS.
Figure 6. DeepStream vision pipeline running people and car detection running on Jetson AGX Orin Developer Kit emulated as Jetson Orin Nano 8GB
Get to market faster with the Jetson AGX Orin Developer Kit
With the emulation support, you can get to production faster by starting and finishing your application development on the Jetson AGX Orin Developer Kit. Buy the kit and start your development. We will also cover emulation in detail in the upcoming NVIDIA JetPack 5.0.2 webinar. Register for the webinar today!
Network traffic continues to increase, as the number of Internet users across the globe reached 5 billion in 2022 and continues to rise. As the number of users…
Network traffic continues to increase, as the number of Internet users across the globe reached 5 billion in 2022 and continues to rise. As the number of users expands, so does the number of connected devices, which is expected to grow into the trillions.
The ever-increasing number of connected users and devices leads to an overwhelming amount of data generated across the network. According to IDC, data is growing exponentially every year, and it’s projected the world will generate 179.6 zettabytes of data by 2025. This equates to an average of 493 exabytes of data generated per day.
All this data and network traffic poses a cybersecurity challenge. Enterprises are generating more data than they can collect and analyze, and the vast majority of the data coming in goes untapped.
Without tapping into this data, an enterprise can’t build robust and rich models and detect abnormal deviations in their environment. The inability to examine this data leads to undetected security breaches, long remediation times, and ultimately huge financial losses for the company being breached.
With cyberattack attempts per week rising by an alarming 50% in 2021, cybersecurity teams must find ways to better protect these vast networks, data, and devices.
To address the cybersecurity data problem, security teams might implement smart sampling, or smart filtering, where they either analyze a subset of the data or filter out data deemed insignificant. These methods are typically adopted because it is cost-prohibitive and extremely challenging to analyze all the data across a network.
Companies may not have the infrastructure to process that scale of data or to do so in a timely manner. In fact, it takes 277 days on average to identify and contain a breach. To provide the best protection against cyberthreats, analyzing all the data quickly yields better results.
The NVIDIA Morpheus GPU-accelerated cybersecurity AI framework enables, for the first time, the ability to inspect all network traffic in real time to address the cybersecurity data problem on a scale previously impossible.
With Morpheus, you can build optimized AI pipelines to filter, process, and classify these large volumes of real-time data, enabling cybersecurity analysts to detect and remediate threats faster.
New visualization capabilities help pinpoint threats faster
The latest release of NVIDIA Morpheus provides visualizations for cybersecurity data, enabling cybersecurity analysts to detect and remediate threats more efficiently. Previously, cybersecurity analysts would have examined large amounts of raw data, potentially parsing through hundreds of thousands of events per week, looking for anomalies.
Morpheus includes several prebuilt, end-to-end workflows to address different cybersecurity use cases. Digital fingerprinting is one of the prebuilt workflows, designed to analyze the behavior of every human and machine across the network to detect anomalous behavior.
The Morpheus digital fingerprinting pretrained model enables up to 100% data visibility and uniquely fingerprints every user, service, account, and machine across the enterprise data center. It uses unsupervised learning to flag when user and machine activities shift.
The digital fingerprinting workflow includes fine-tunable explainability, providing metrics behind highlighted anomalies, and thresholding to determine when certain events should be flagged. Both are customizable for your environment.
Digital fingerprinting also now includes a new visualization tool that provides insights to a security analyst on deviations from normal behavior, including how it has deviated, and what is related to that deviation. Not only do analysts get an issue alert, they can quickly dive into the details and determine a set of actionable next steps.
This gives organizations orders of magnitude improvement in data analysis, potentially reducing the time to detect a threat from weeks to minutes for certain attack patterns.
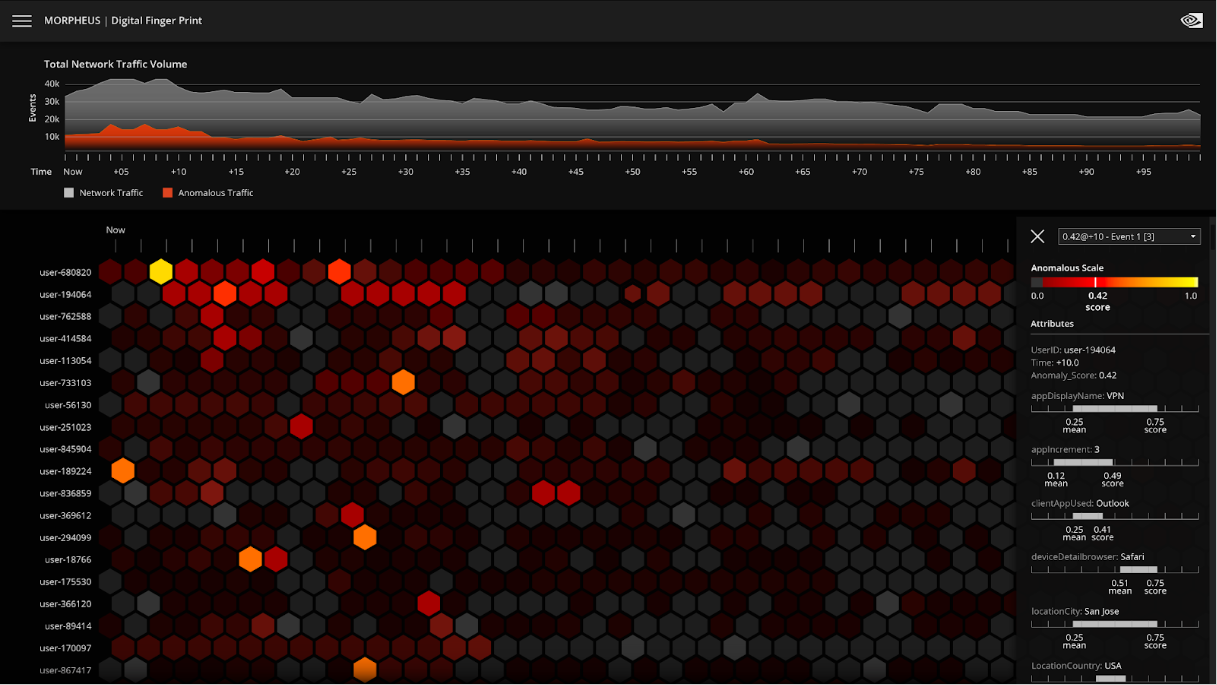
Figure 1 shows a closer look at the visualization for the digital fingerprinting use case in Morpheus. This example looks at cybersecurity data on a massive scale: tens of thousands of users, where each hexagon represents events related to a user over a period of time. No human can keep track of this many users.
Figure 1. NVIDIA Morpheus visualization for digital fingerprinting workflow
NVIDIA Morpheus has parsed and prioritized the data so it’s easy to see when an anomaly has been identified. In the visualization, the data is organized such that the most important data is at the top and colors indicate the anomaly score: darker colors are good and lighter colors are bad. A security analyst can easily identify an anomaly because it’s prioritized and easy to spot. The security analyst can select a light-colored hexagon and quickly view data associated with the event.
With NVIDIA Morpheus, AI performs massive data filtration and reduction, surfacing critical behavior anomalies as they propagate throughout the network. It can provide security analysts with more context around individual events to help connect the dots to other potentially bad things happening.
NVIDIA Morpheus digital fingerprinting workflow in action
The following video shows a breach. With Morpheus, you can reduce from hundreds of millions of events per week to just 8–10 potentially actionable things to investigate daily. This cuts the time to detect threats from weeks to minutes for certain attack patterns.
Video 1. NVIDIA Morpheus digital fingerprinting workflow deployed across an enterprise of 25K employees
Morpheus helps keep sensitive information safe
Another prebuilt workflow included with Morpheus is sensitive information detection, to help find and classify leaked credentials, keys, passwords, credit card numbers, bank account numbers, and more.
The sensitive information detection workflow for Morpheus now includes a visual graph-based explainer to enable security analysts to spot leaked sensitive data more easily. In the visualization for sensitive information detection, you see a representation of a network, where dots are servers and lines are packets flowing between the servers.
With Morpheus deployed, AI inferencing is enabled across the entire network. The sensitive information detection model is trained to identify sensitive information, such as AWS credentials, GitHub credentials, private keys, and passwords. If any of these are observed in the packet, they appear as red lines.
The AI model in Morpheus searches through every packet, continually flagging when it encounters sensitive data. Rather than using pattern matching, this is done with a deep neural network trained to generalize and identify patterns beyond static rulesets.
Notice all the individual lines; you can see how quickly a human can become overwhelmed by all of the data coming in. With the visualization capabilities in Morpheus, you immediately see the lines that represent leaked sensitive information. Hovering over one of the red lines shows information about the credential, making it easier to triage and remediate.
With Morpheus, cybersecurity applications can integrate and collect information for automated incident management and action prioritization. To speed recovery, the originating servers, destination servers, exposed credentials, and even the raw data is available.
Video 2. NVIDIA Morpheus visualization for sensitive information detection workflow
Multi-process pipeline support enables new cybersecurity workflows
Multi-process pipeline support enables Morpheus to support new cybersecurity workflows, which can be intelligently batched to reduce latency. For example, a cybersecurity workflow with both deep learning and machine learning might use the same data, but with different derived features. The ensemble must ultimately come together, but machine learning is much faster than deep learning. Morpheus can now dynamically batch throughout multiple pipelines to optimize end-to-end times and minimize latency.
Enabling new AI-based cybersecurity solutions
With Morpheus, cybersecurity practitioners can access prebuilt AI workflows such as digital fingerprinting, sensitive information detection, and more:
Crypto-mining malware detection
Phishing detection
Fraudulent transaction and identity detection
Ransomware detection
Morpheus enables cybersecurity developers and ISVs to build AI-based solutions. It includes developer toolkits and fine-tuning scripts to make it easy to integrate Morpheus into existing models. NVIDIA also partners with leading systems integrators who are enabling any organization to leverage AI-based cybersecurity.
Democratizing AI-based cybersecurity
Morpheus enables enterprises to develop AI-based cybersecurity tools more easily and better protect data centers. Systems integrators and cybersecurity vendors are using Morpheus to build more advanced, higher-performing cybersecurity solutions to take to organizations across every industry.
Best Buy
Best Buy deployed Morpheus on NVIDIA DGX to improve phishing detection capabilities and accelerate proactive response. Their deployment of Morpheus for the phishing detection use case enabled them to increase suspicious message detection by 15%.
Booz Allen Hamilton
Booz Allen Hamilton is helping to better enable incident response teams, particularly those tasked with threat hunting at the tactical edge. They’ve developed a highly customized, GPU-accelerated Cyber Precog platform that integrates operationally honed cyber tooling, AI models, and modular pipelines for rapid capability deployment.
Built using the NVIDIA Morpheus framework, Cyber Precog offers an initial suite of core capabilities along with a flexible software fabric for developing, testing, and deploying new GPU-accelerated analytics for incident response.
During incident response, operators may have to evaluate data on a disconnected edge network under conditions in which they cannot exfil data, so they can bring with them an uncompromised flyaway kit to securely access cyberdata.
Using NVIDIA GPUs and Morpheus, Cyber Precog enables up to a 300x speedup in data ingest and pipeline, 32x faster training, and 24x faster inference compared to CPU-based solutions. Booz Allen benchmarks show that a single NVIDIA GPU-accelerated server replaces up to 135 CPU-only server nodes, providing expedited decision-making for cyber operators.
The Cyber Precog platform is available to public and private sector customers.
CyberPoint
CyberPointis focused on zero trust across a spectrum of cybersecurity use cases with dozens of mission partners and networks across various organizations, making analysis incredibly challenging.
Delivering AI-based solutions to identify threat entities and malicious behavior is critical to security operations center analysts, enabling them to pivot and focus on only the most salient threats.
Using NVIDIA Morpheus, they’ve built user behavior models to help analysts identify threats on live data as it comes in. They’ve developed their own stages within Morpheus to fit their use cases, leveraging graph neural networks and natural language processing models, and integrating them with Graphistry to provide 360-degree views of users and devices.
By using Morpheus, CyberPoint has seen a 17x speedup for their cybersecurity workflows.
IntelliGenesis
IntelliGenesishas a flyaway kit built on NVIDIA Morpheus designed to be environment-agnostic and tailored for immediate detection and remediation at the edge. They’ve built an enterprise solution to conduct AI-based real-time threat detection at scale. It’s customizable yet simple enough to enable any level of data scientist or domain expert to use. Using Morpheus and GPU-acceleration, they immediately saw exponential increases in performance.
Splunk
Splunkcreated a Copilot for Splunk SPL, enabling users to write a description of what they want to achieve in plain English and get suggested queries to execute. The Splunk team spoke about this at .conf22 and, notably, there were many machine learning engineers in the crowd. The feedback was overwhelmingly positive and indicated that we’re only scratching the surface of what can be done with NLP today.
At first blush, this may not seem like a cybersecurity project. However, in implementing this, they’re able to identify sensitive information leakage, which is a stellar example of Morpheus’s flexibility in extracting insights from data. Using Morpheus, Splunk achieved 5–10x speedups to their pipeline.
World Wide Technology
World Wide Technology (WWT)is using Morpheus and NVIDIA converged accelerators for their AI Defined Networking (AIDN) solution. AIDN expands upon existing IT monitoring infrastructure to observe and correlate telemetry, system, and application data points over time to build actionable insights and alert network operators. Alerts are then used as event triggers for scripted actions, allowing AIDN to assist operators with repetitive tasks, such as ticket submission.
Morpheus at GTC and beyond
For more information about how NVIDIA and our partners are helping to address cybersecurity challenges with AI, add the following GTC sessions to your calendar:
Learn About the Latest Developments with AI-Powered Cybersecurity: Learn about the latest innovations available with NVIDIA Morpheus, being introduced in the Fall 2022 release, and find out how today’s security analysts are using Morpheus in their everyday investigations and workflows. Bartley Richardson, Director of Cybersecurity Engineering, NVIDIA
Deriving Cyber Resilience from the Data Supply Chain: Hear how NVIDIA tackles these challenges through the application of zero-trust architectures in combination with AI and data analytics, combating our joint adversaries with a data-first response with the application of DPU, GPU, and AI SDKs and tools. Learn where the promise of cyber-AI is working in application. Daniel Rohrer, Vice President of Software Product Security, NVIDIA
Accelerating the Next Generation of Cybersecurity Research: Discover how to apply prebuilt models for digital fingerprinting to analyze behavior of every user and machine, analyze raw emails to automatically detect phishing, find and classify leaked credentials and sensitive information, profile behaviors to detect malicious code and behavior, and leverage graph neural networks to identify fraud. Killian Sexsmith, Senior Developer Relations Manager, NVIDIA

") Join us on October 4 to explore new features in JetPack 5.0.2. Learn how to develop for any Jetson Orin module using emulation support on the Jetson AGX Orin…
Join us on October 4 to explore new features in JetPack 5.0.2. Learn how to develop for any Jetson Orin module using emulation support on the Jetson AGX Orin… Build better GPU-accelerated Speech AI applications with the latest NVIDIA Riva updates, including enterprise support.
Build better GPU-accelerated Speech AI applications with the latest NVIDIA Riva updates, including enterprise support.") Learn the basics of physics-informed deep learning and how to use NVIDIA Modulus, the physics machine learning platform, in this self-paced online course.
Learn the basics of physics-informed deep learning and how to use NVIDIA Modulus, the physics machine learning platform, in this self-paced online course.

 Announced at GTC 2022, the next generation of NVIDIA GPUs—the NVIDIA GeForce RTX 40 series, NVIDIA RTX 6000 Ada Generation, and NVIDIA L40 for data…
Announced at GTC 2022, the next generation of NVIDIA GPUs—the NVIDIA GeForce RTX 40 series, NVIDIA RTX 6000 Ada Generation, and NVIDIA L40 for data…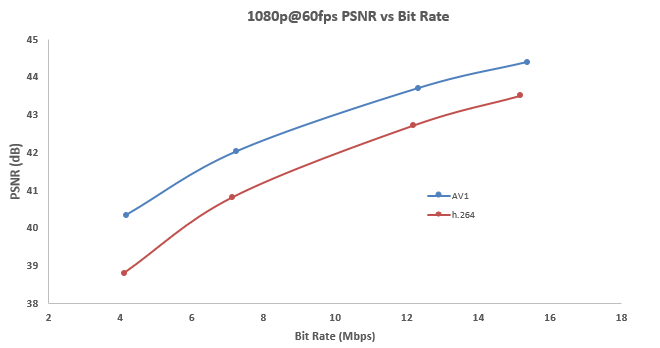






 With the Jetson Orin Nano announcement this week at GTC, the entire Jetson Orin module lineup is now revealed. With up to 40 TOPS of AI performance, Orin Nano…
With the Jetson Orin Nano announcement this week at GTC, the entire Jetson Orin module lineup is now revealed. With up to 40 TOPS of AI performance, Orin Nano…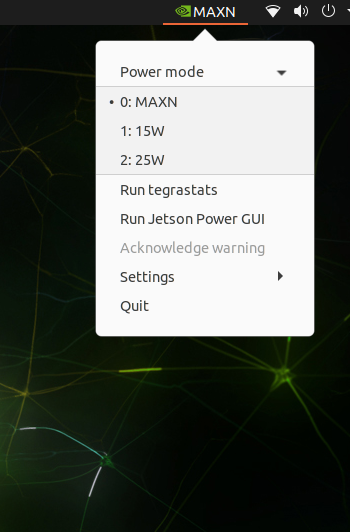


 Network traffic continues to increase, as the number of Internet users across the globe reached 5 billion in 2022 and continues to rise. As the number of users…
Network traffic continues to increase, as the number of Internet users across the globe reached 5 billion in 2022 and continues to rise. As the number of users…