
 AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area…
AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area…
AI processing requires full-stack innovation across hardware and software platforms to address the growing computational demands of neural networks. A key area to drive efficiency is using lower precision number formats to improve computational efficiency, reduce memory usage, and optimize for interconnect bandwidth.
To realize these benefits, the industry has moved from 32-bit precisions to 16-bit, and now even 8-bit precision formats. Transformer networks, which are one of the most important innovations in AI, benefit from an 8-bit floating point precision in particular. We believe that having a common interchange format will enable rapid advancements and the interoperability of both hardware and software platforms to advance computing.
NVIDIA, Arm, and Intel have jointly authored a whitepaper, FP8 Formats for Deep Learning, describing an 8-bit floating point (FP8) specification. It provides a common format that accelerates AI development by optimizing memory usage and works for both AI training and inference. This FP8 specification has two variants, E5M2 and E4M3.
This format is natively implemented in the NVIDIA Hopper architecture and has shown excellent results in initial testing. It will immediately benefit from the work being done by the broader ecosystem, including the AI frameworks, in implementing it for developers.
Compatibility and flexibility
FP8 minimizes deviations from existing IEEE 754 floating point formats with a good balance between hardware and software to leverage existing implementations, accelerate adoption, and improve developer productivity.
E5M2 uses five bits for the exponent and two bits for the mantissa and is a truncated IEEE FP16 format. In circumstances where more precision is required at the expense of some numerical range, the E4M3 format makes a few adjustments to extend the range representable with a four-bit exponent and a three-bit mantissa.
The new format saves additional computational cycles since it uses just eight bits. It can be used for both AI training and inference without requiring any re-casting between precisions. Furthermore, by minimizing deviations from existing floating point formats, it enables the greatest latitude for future AI innovation while still adhering to current conventions.
High-accuracy training and inference
Testing the proposed FP8 format shows comparable accuracy to 16-bit precisions across a wide array of use cases, architectures, and networks. Results on transformers, computer vision, and GAN networks all show that FP8 training accuracy is similar to 16-bit precisions while delivering significant speedups. For more information about accuracy studies, see the FP8 Formats for Deep Learning whitepaper.

In Figure 1, different networks use different accuracy metrics (PPL and Loss), as indicated.
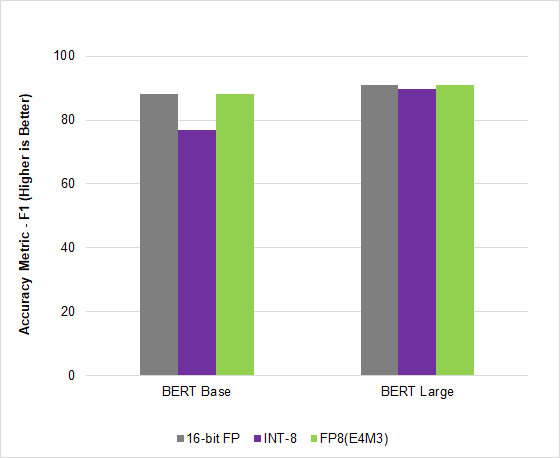
In MLPerf Inference v2.1, the AI industry’s leading benchmark, NVIDIA Hopper leveraged this new FP8 format to deliver a 4.5x speedup on the BERT high-accuracy model, gaining throughput without compromising on accuracy.
Moving towards standardization
NVIDIA, Arm, and Intel have published this specification in an open, license-free format to encourage broad industry adoption. They will also submit this proposal to IEEE.
By adopting an interchangeable format that maintains accuracy, AI models will operate consistently and performantly across all hardware platforms, and help advance the state of the art of AI.
Standards bodies and the industry as a whole are encouraged to build platforms that can efficiently adopt the new standard. This will help accelerate AI development and deployment by providing a universal, interchangeable precision.