Hello, I am working on a project to detect and classify different types and stages of brain cancer. My issue is that no matter what I do I can’t get past ~80% accuracy. I have looked into various resources and papers and I can’t notice anything else I can do other than changing my model to a Dictionary Learning Model (I am currently using a CNN because I am quite new to machine learning).
If anyone could help me out if I have any obvious code errors or if they have any ideas on how to improve the accuracy that would be great.
Learn how to develop an end-to-end workflow starting with synthetic data generation in NVIDIA Isaac Sim, fine-tuning with the TAO Toolkit and deploying model with NVIDIA Isaac ROS.
From building cars to helping surgeons and delivering pizzas, robots not only automate but also speed up human tasks manyfold. With the advent of AI, you can build even smarter robots that can better perceive their surroundings and make decisions with minimal human intervention.
Take, for instance, an autonomous robot used in warehouses to move payloads from one place to another. It must perceive the free space around it, detect and avoid any obstacles in its path, and make “on-the-fly” decisions to pick a new path without any delay.
Therein lies the challenge. This means building an application powered by an AI model that has been trained and optimized to work in this environment. It requires collecting copious amounts of high-quality data and developing a highly accurate AI model to power the application. These are the key barriers when it comes to moving applications from the lab into a production environment.
In this post, we show how you can solve both your data challenge and model creation challenge with the NVIDIA Isaac platform and the TAO framework. You use NVIDIA Isaac Sim, a robotics simulation application to create virtual environments and generate synthetic data. The NVIDIA TAO Toolkit is a low-code AI model development solution with built-in transfer learning to fine-tune a pretrained model with a fraction of the data, compared to training from scratch. Finally, deploy the optimized model using NVIDIA Isaac ROS onto a robot and put it to work in the real world.
Figure 1. Overview of workflow to train a TAO toolkit model on synthetic data using NVIDIA Isaac Sim to adapt a real-world use case.
Prerequisites
Before you start, you must have the following resources for training and deploying:
NVIDIA GPU Driver version: >470
NVIDIA Docker: 2.5.0-1
NVIDIA GPU in the cloud or on-premises:
NVIDIA A100
NVIDIA V100
NVIDIA T4
NVIDIA RTX 30×0 (NVIDIA Isaac Sim supports NVIDIA RTX 20 series as well)
In the section, we outline the steps for generating synthetic data in NVIDIA Isaac Sim. Synthetic data is annotated information that computer simulations or algorithms generate. Synthetic data can help solve data challenges when real data is difficult or expensive to acquire.
NVIDIA Isaac Sim provides three methods for generating synthetic data:
Replicator composer
Python scripts
GUI
For this experiment, we chose to use Python scripts to generate data with domain randomization. Domain randomization varies the parameters that define a scene in the simulation environment, including the position, scale of various objects in a scene, the lighting of the simulated environment, the color and texture of objects, and more.
Adding domain randomization to simultaneously vary many parameters of the scene improves the dataset quality and enhances the model’s performance by exposing it to a wide variety of domain parameters seen in the real world.
In this case, you use two environments for training data: a warehouse and a small room. Next steps include adding objects into the scene that obey the laws of physics. We used sample objects from NVIDIA Isaac Sim, which also includes everyday objects from the YCB dataset.
Figure 2. Sample simulation images from the simple room and warehouse environments
After installing NVIDIA Isaac Sim, the Isaac Sim App Selector provides an option for Open in Folder, which contains a python.sh script. This is used to run the scripts for data generation.
Follow the steps listed to generate the data.
Select the environment and add a camera to the scene
def add_camera_to_viewport(self):
# Add a camera to the scene and attach it to the viewport
self.camera_rig = UsdGeom.Xformable(create_prim("/Root/CameraRig", "Xform"))
self.camera = create_prim("/Root/CameraRig/Camera", "Camera")
Add a semantic ID to the floor:
def add_floor_semantics(self):
# Get the floor from the stage and update its semantics
stage = kit.context.get_stage()
floor_prim = stage.GetPrimAtPath("/Root/Towel_Room01_floor_bottom_218")
add_update_semantics(floor_prim, "floor")
Add objects in the scene with Physics:
def load_single_asset(self, object_transform_path, object_path, usd_object):
# Random x, y points for the position of the USD object
translate_x , translate_y = 150 * random.random(), 150 * random.random()
# Load the USD Object
try:
asset = create_prim(object_transform_path, "Xform",
position=np.array([150 + translate_x, 175 + translate_y, -55]),
orientation=euler_angles_to_quat(np.array([0, 0.0, 0]),
usd_path=object_path)
# Set the object with correct physics
utils.setRigidBody(asset, "convexHull", False)
Initialize domain randomization components:
def create_camera_randomization(self):
# A range of values to move and rotate the camera
camera_tranlsate_min_range, camera_translate_max_range = (100, 100, -58),
(220, 220, -52)
camera_rotate_min_range, camera_rotate_max_range = (80, 0, 0), (85, 0 ,360)
# Create a Transformation DR Component for the Camera
self.camera_transform = self.dr.commands.CreateTransformComponentCommand(
prim_paths=[self.camera.GetPath()],
translate_min_range=camera_tranlsate_min_range,
translate_max_range=camera_translate_max_range,
rotate_min_range=camera_rotate_min_range,
rotate_max_range=camera_rotate_max_range,
duration=0,5).do()
Make sure that the camera position and properties in the simulation are similar to the real-world attributes. Adding a semantic ID to the floor is necessary for generating the correct free space segmentation masks. As mentioned earlier, domain randomization was applied to help with the sim2real performance of the model.
The Offline Data Generation sample provided in the NVIDIA Isaac Sim documentation is the starting point for our scripts. Changes have been made for this use case that include adding objects to a scene with physics, updating domain randomization, and adding semantics to the floor. We have generated nearly 30,000 images with their corresponding segmentation masks for the dataset.
Train, adapt, and optimize with the TAO Toolkit
In this section, you use the TAO Toolkit to fine-tune the model with the generated synthetic data. For this task, we chose to experiment with UNET models available from NGC.
!ngc registry model list nvidia/tao/pretrained_semantic_segmentation:*
Set up your data, spec file (TAO specifications), and experiment directories:
A pretrained AI and deep learning model is one that has been trained on representative datasets and fine-tuned with weights and biases. You can quickly and easily fine-tune a pretrained model by applying transfer learning with only a fraction of data compared to training from scratch.
Within the realm of pretrained models, there are models that perform a specific task like detecting people, cars, license plates, and so on.
We first picked a U-Net model with ResNet10 and ResNet18 backbones. The results obtained from the models showed the walls and the floor merged as a single entity on real-world data, instead of two separate entities. This was true even though the performance of the model on simulation images showed high levels of accuracy.
BackBone
Pruned
Dataset Size
Image Size
Training Evaluations
Train
Val
F1 Score
mIoU (%)
Epochs
RN10
NO
25K
4.5K
512×512
89.2
80.1
50
RN18
NO
25K
4.5K
512×512
91.1
83.0
50
Table 1. Experiments on different pretrained models available from the NGC platform for TAO.
We experimented with different backbones and image sizes to observe the trade-off of latency (FPS) to accuracy. All models in the table are the same (UNET); only the backbones are different.
Figure 3. Predictions of ResNet18 model. (left) Simulation image; (right) a real-world image.
Based on the results, it was evident that we needed a different model that better fit the use case. We picked the PeopleSemSeg model available in the NGC catalog. The model was pretrained on five million objects for the “person” class with the dataset consisting of a mix of camera heights, crowd density, and field-of-view (FOV). This model also can segment the background and the free space as two separate entities.
After training this model with the same dataset, the mean IOU increased by more than 10% and the resulting images clearly show better segmentation between floor and walls.
BackBone
Pruned
Dataset Size
Image Size
Training Evaluations
Train
Val
F1 Score
mIoU (%)
Epochs
PeopleSemSegNet
NO
25K
4.5K
512×512
98.1
96.4
50
PeopleSemSegNet
NO
25K
4.5K
960×544
99.0
98.1
50
Table 2. Experiments with PeopleSemSegNet Trainable model
Figure 4. Prediction results for transfer learning on the peoplesemseg TAO model with synthetic data (left) and real-world data (right).
Figure 4 shows free space identification on the simulation image and the real-world images from the robot’s perspective before fine-tuning on the PeopleSemSeg model with real-world data. That is, with models trained on purely NVIDIA Isaac Sim data.
The key takeaway is that while there may be many pretrained models that can do the task, it is important to pick one that is closest to your current application. This is where TAO’s purpose-built models are useful.
When you are satisfied with the model performance on NVIDIA Isaac Sim data and the Sim2Sim validation performance, prune the model.
To run this model with minimal latency, optimize it to run on the target GPU. There are two ways to achieve this:
Pruning: The pruning feature in the TAO Toolkit automatically removes the unwanted layers and neurons, effectively reducing the size of the model. You must retrain the model to recover the accuracy lost during pruning.
Post-training quantization: Another feature in the TAO toolkit enables the model size to be further reduced. This changes its precision from FP32 to INT8, enhancing performance without sacrificing its accuracy.
Table 1 shows a summary of the results between unpruned and pruned models. The final pruned and quantized model, chosen for deployment, was 17x smaller and delivered an inference performance 5x faster compared to the original model, measured on NVIDIA Jetson Xavier NX.
Model
Dataset
Training Evaluations
Inference Performance
Pruned
Fine-Tune on Real World Data
Training Set
Validation Set
F1 Score (%)
mIoU (%)
Precision
FPS
NO
NO
Sim
Sim
0.990
0.981
FP16
3.9
YES
NO
Sim
Sim
0.991
0.982
FP16
15.29
YES
NO
Sim
Real
0.680
0.515
FP16
15.29
YES
YES
Real
Real
0.979
0.960
FP16
15.29
YES
YES
Real
Real
0.974
0.959
INT8
20.25
Table 3. Results on Sim2Sim and Sim2Real
The training dataset for the sim data consists of 25K images, whereas training data for real-world images for fine-tuning, consists of 44 images only. The validation dataset of real images consists of 56 images only. For real-world data, we collected a dataset in three different indoor scenarios. The input image size for the model is 960×544. The inference performance is measured using the NVIDIA TensorRT trtexec tool.
Figure 5. Results on real-world images from the robot after fine-tuning on real-world data
Deployment with NVIDIA Isaac ROS
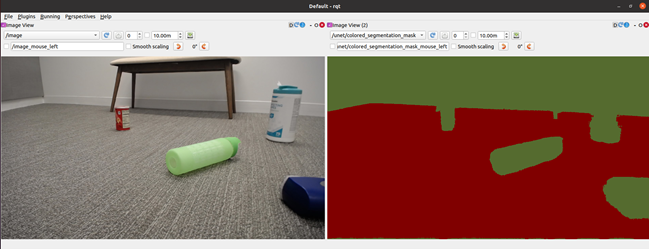
In this section, we show the steps to take the trained and optimized model and deploy it using NVIDIA Isaac ROS on iRobot’s Create 3 robot powered by Jetson Xavier NX. Both Create 3 and the NVIDIA Isaac ROS image segmentation node run on ROS2.
Figure 6. Image and segmentation mask using rqt_image_viewer in ROS2. (left) Uses a USB camera on the Create 3 robot; (right) Uses the isaac-ros-image-segmentation node.
In this post, we showed you an end-to-end workflow starting with synthetic data generation in NVIDIA Isaac Sim, fine-tuning with the TAO Toolkit, and deploying the model with NVIDIA Isaac ROS.
Both NVIDIA Isaac Sim and TAO Toolkit are solutions that abstract away the AI framework complexity, enabling you to build and deploy AI-powered robotic applications in production, without the need for any AI expertise.
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology accelerates creative workflows. This week In the NVIDIA Studio, we welcome Yangtian Li, a senior concept artist at Singularity6. Li is a concept designer and illustrator Read article >
So I am trying to use neural networks for time series forecasting. I have created 3 different models (LSTM, CNN and a LSTM-CNN hybrid). Now I want to compare their performance based on the metrics MAE, RMSE and sMAPE. Here comes the dilemma, whenever I retrain the models on the same dataset, the performance of every model changes, and the previously best performing model now performs the worst now. I have tried to set the random seed to a constant, yet I am facing the same issue. Please help 🙁 Thanks.
Join an upcoming webinar highlighting the newest features of NVIDIA TensorRT and learn how to optimize inference engines for production on the Orin AI platform.
Jack Morrison and Isaac Roberts, co-founders of Replica Labs, were restless two years after their 3D vision startup was acquired, seeking another adventure. Then, in 2018, when Morrison was mowing his lawn, it struck him: autonomous lawn mowers. The two, along with Davis Foster, co-founded Scythe Robotics. The company, based in Boulder, Colo., has a Read article >
Edward McEvenue grew up making claymations in LEGO towns. Now, he’s creating photorealistic animations in virtual cities, drawing on more than a decade of experience in the motion graphics industry.
Using remote sensing and an ensemble of convolutional neural networks, the study could guide sustainable forest management and climate mitigation efforts.
A new study from researchers at ETH Zurich’s EcoVision Lab is the first to produce an interactive Global Canopy Height map. Using a newly developed deep learning algorithm that processes publicly available satellite images, the study could help scientists identify areas of ecosystem degradation and deforestation. The work could also guide sustainable forest management by identifying areas for prime carbon storage—a cornerstone in mitigating climate change.
“Global high-resolution data on vegetation characteristics are needed to sustainably manage terrestrial ecosystems, mitigate climate change, and prevent biodiversity loss. With this project, we aim to fill the missing data gaps by merging data from two space missions with the help of deep learning,” said Konrad Schindler, a Professor in the Department of Civil, Environmental, and Geomatic Engineering at ETH Zurich.
From rainforests to boreal woodland, forests play a key role in climate mitigation, absorbing up to 2 billion tons of carbon dioxide every year. Aboveground biomass, which includes all parts of the tree such as the trunk, bark, or branches, correlates with the amount of carbon stored in a forest.
Tree height is often an indicator of biomass, meaning accurate measurements could help with more precise carbon sequestration data and climate science models. This information could also guide forest management by identifying areas in need of conservation, restoration, and reforestation.
There have been many studies using AI-powered remote sensing models for forest monitoring. However, these typically work regionally and pose a compute challenge due to vast amounts of data. Models have also been unsuccessful in measuring heights over 30 meters, leading to an underestimation of tall canopies.
A handful of current studies are deploying satellites for capturing and measuring vegetation from space. One such mission, NASA’s Global Ecosystem Dynamics Investigation (GEDI), aims to monitor the structure of forests worldwide using a space-borne laser scanner. However, it captures only sparse samples that cover less than 4% of the global landmass.
Other global remote sensing missions offer complete coverage. The Copernicus Sentinel-2 satellites capture images at a resolution of 10×10 meters per pixel and the entire globe is captured every 5 days. However, it only sees a bird’s-eye view of the vegetation and does not measure height.
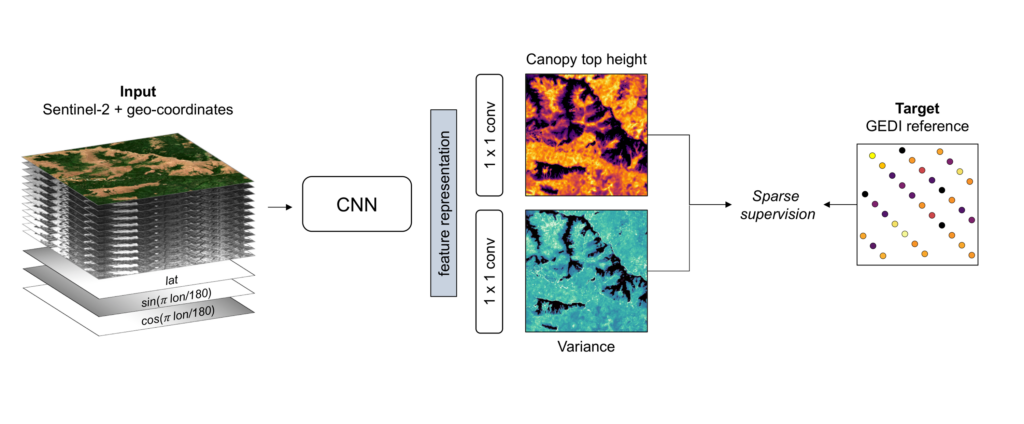
The researchers developed, trained, and deployed deep learning algorithms using data from these separate remote sensing missions to create the first global vegetation height map. The team trained an ensemble of fully convolutional neural networks (CNNs) on canopy top height from the GEDI data. Using a dataset of 600 million GEDI footprints, along with the corresponding Sentinel-2 image patches, the algorithm learns to extract canopy height from spectral and textural image patterns.
Figure 1. Illustration of the model training process with sparse supervision from GEDI LIDAR. The CNN takes the Sentinel-2 image and encoded geographical coordinates as an input to estimate dense canopy top height and its uncertainty (variance).
When the models are up and running, they automatically process over 250,000 images and estimate canopy height for the map at a 10-meter ground-sampling distance. It takes 10 days to cover the globe using a high-performance cluster equipped with NVIDIA RTX 2080 GPUs. According to Schindler, ETH Zurich’s high-performance computing system Euler, contains a variety of GPUs running over 1,500 graphics cards.
By modeling the uncertainty in the data and using an ensemble of five separately trained CNNs the models have a level of transparency not often seen in deep learning algorithms. Uncertainty is quantified for every single pixel estimate, which could give researchers and forest managers confidence when making decisions based on the information.
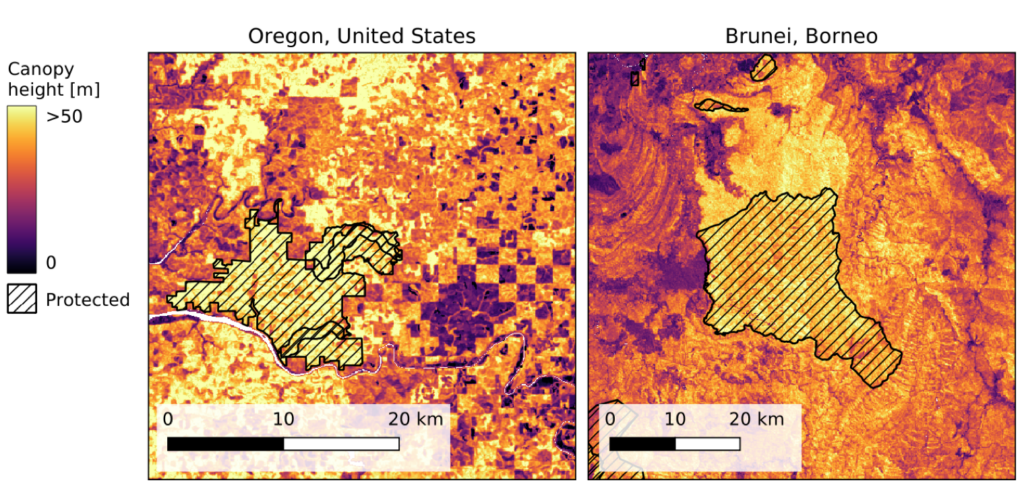
The researchers found that protected areas, such as the Oregon Coast Range and the Ulu Temburong National Park in Borneo often contained higher vegetation. About 34% of canopies taller than 30 meters grow in these areas.
Figure 2. A dense canopy height map reveals the spatial patterns of protected areas (left) Devil’s Staircase Wilderness, Oregon, and (right) Ulu Temburong National Park, Borneo.
According to the study, the model can be deployed annually to track canopy height change over time. The researchers also point out that the maps could be used to evaluate regions where wildfires have occurred, giving a more accurate map of damage.
“We hope that this work will advance future research in climate, carbon, and biodiversity modeling. We also hope that our freely available map can support the work of conservationists in practice. In the future, we would like to expand our approach to mapping biomass as well as temporal changes on a global scale,” said lead author Nico Lang, a PhD student in the EcoVision Lab, part of the Photogrammetry and Remote Sensing group at ETH Zürich.
EcoVision also plans to make the code available soon. The lab, founded by ETH Zurich Professor Konrad Schindler and University of Zurich Professor Jan Dirk Wegner in 2017, is dedicated to developing machine learning algorithms for large-scale environmental data analysis. For more information refer to their project page, A high-resolution canopy height model of the Earth.
I built a neural network to solve a regression problem for me. I would like to wrap a physical equation around it which depends on the input features. Instead of predicting Y directly, I want to predict a parameter alpha which is part of a physical equation.
Let the model predict alpha
Instead of calculating the loss as MSE(y_true, y_pred) directly, calculate y_pred as follows before (simple example): y_pred = alpha * X[0] + X[1] where X is the vector containing the model input, alpha the parameter the NN should learn.
This is how I implemented it, you can see the custom_loss function and part where I call the fit() method. This is a workflow for testing I found on stackoverflow, if you know a better method to implement something like this, great!
However, my model is super unstable and doesn’t converge. Sometimes I get only NaNs as loss, sometimes the loss circles around a value but doesn’t finish the thing. Using only MSE, the model works quite well. Let’s assume the physical equation embedded in the loss function “makes sense”, this is just an example.
Did anybody do something like this before? Another problem I am facing – the input X is normalized (StandardScaler). For the physical equation to make sense, I would need the “de-normalized” values, right? How would I attempt this? scikit-learn works with numpy not with tensors I guess.
spe=FLAGS.train_spe, File " neuralgymneuralgymtrainmultigpu_trainer.py", line 25, in __init__ super().__init__(**self.context) File " neuralgymneuralgymtraintrainer.py", line 38, in __init__ self._train_op, self._loss = self.train_ops_and_losses() File " neuralgymneuralgymtrainmultigpu_trainer.py", line 75, in train_ops_and_losses gpu_id=gpu, **graph_def_kwargs) ... File " tensorflow115libsite-packageskerasenginebase_layer.py", line 489, in __call__ output = self.call(inputs, **kwargs) File " tensorflow115libsite-packageskerasenginenetwork.py", line 583, in call output_tensors, _, _ = self.run_internal_graph(inputs, masks) File " tensorflow115libsite-packageskerasenginenetwork.py", line 740, in run_internal_graph layer.call(computed_tensor, **kwargs)) File " tensorflow115libsite-packageskeraslayersnormalization.py", line 185, in call epsilon=self.epsilon) File " tensorflow115libsite-packageskerasbackendtensorflow_backend.py", line 2315, in normalize_batch_in_training epsilon=epsilon) File " tensorflow115libsite-packageskerasbackendtensorflow_backend.py", line 2288, in _fused_normalize_batch_in_training data_format=tf_data_format) File " tensorflow115libsite-packagestensorflow_corepythonopsnn_impl.py", line 1501, in fused_batch_norm name=name) File " tensorflow115libsite-packagestensorflow_corepythonopsgen_nn_ops.py", line 4620, in fused_batch_norm_v3 name=name) File " tensorflow115libsite-packagestensorflow_corepythonframeworkop_def_library.py", line 794, in _apply_op_helper op_def=op_def) File " tensorflow115libsite-packagestensorflow_corepythonutildeprecation.py", line 507, in new_func return func(*args, **kwargs) File " tensorflow115libsite-packagestensorflow_corepythonframeworkops.py", line 3357, in create_op attrs, op_def, compute_device) File " tensorflow115libsite-packagestensorflow_corepythonframeworkops.py", line 3426, in _create_op_internal op_def=op_def) File " tensorflow115libsite-packagestensorflow_corepythonframeworkops.py", line 1748, in __init__ self._traceback = tf_stack.extract_stack()
when running in tf 2.x:
log_dir=FLAGS.log_dir, File " ngneuralgymtrainmultigpu_trainer.py", line 25, i __init__ super().__init__(**self.context) File " ngneuralgymtraintrainer.py", line 38, in __init_ self._train_op, self._loss = self.train_ops_and_losses() File " ngneuralgymtrainmultigpu_trainer.py", line 75, i train_ops_and_losses gpu_id=gpu, **graph_def_kwargs) File " inpaint_model.py", line 203, in build_graph_with_loses surface_attention=FLAGS.surface_attention, File " inpaint_model.py", line 127, in build_inpaint_net x = gen_deconv(x, cnum, name="allconv15_upsample") File " inpaint_ops.py", line 85, in gen_deconv x = resize(x, func=tf.compat.v1.image.resize_nearest_neighbor) File " ngneuralgymopslayers.py", line 152, in resize x = func(x, new_xs, align_corners=align_corners) File "C:ProgramDataAnaconda3libsite-packagestensorflowpythonopsimage_ps_impl.py", line 4659, in resize_nearest_neighbor name=name) File "C:ProgramDataAnaconda3libsite-packagestensorflowpythonopsgen_imge_ops.py", line 3873, in resize_nearest_neighbor name=name) File "C:ProgramDataAnaconda3libsite-packagestensorflowpythonframeworkp_def_library.py", line 742, in _apply_op_helper attrs=attr_protos, op_def=op_def) File "C:ProgramDataAnaconda3libsite-packagestensorflowpythonframeworkps.py", line 3784, in _create_op_internal op_def=op_def) File "C:ProgramDataAnaconda3libsite-packagestensorflowpythonframeworkps.py", line 2175, in __init__ self._traceback = tf_stack.extract_stack_for_node(self._c_op)

 Learn how to develop an end-to-end workflow starting with synthetic data generation in NVIDIA Isaac Sim, fine-tuning with the TAO Toolkit and deploying model with NVIDIA Isaac ROS.
Learn how to develop an end-to-end workflow starting with synthetic data generation in NVIDIA Isaac Sim, fine-tuning with the TAO Toolkit and deploying model with NVIDIA Isaac ROS.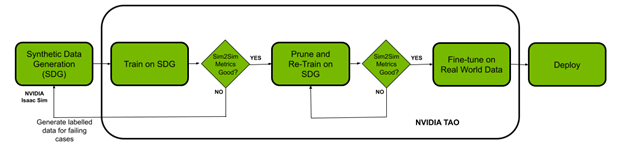




 Join an upcoming webinar highlighting the newest features of NVIDIA TensorRT and learn how to optimize inference engines for production on the Orin AI platform.
Join an upcoming webinar highlighting the newest features of NVIDIA TensorRT and learn how to optimize inference engines for production on the Orin AI platform. Using remote sensing and an ensemble of convolutional neural networks, the study could guide sustainable forest management and climate mitigation efforts.
Using remote sensing and an ensemble of convolutional neural networks, the study could guide sustainable forest management and climate mitigation efforts.