
Video recognition is a core task in computer vision with applications from video content analysis to action recognition. However, training models for video recognition often requires untrimmed videos to be manually annotated, which can be prohibitively time consuming. In order to reduce the effort of collecting videos with annotations, learning visual knowledge from videos with weak labels, i.e., where the annotation is auto-generated without manual intervention, has attracted growing research interest, thanks to the large volume of easily accessible video data. Untrimmed videos, for example, are often acquired by querying with keywords for classes that the video recognition model aims to classify. A keyword, which we refer to as a weak label, is then assigned to each untrimmed video obtained.
Although large-scale videos with weak labels are easier to collect, training with unverified weak labels poses another challenge in developing robust models. Recent studies have demonstrated that, in addition to the label noise (e.g., incorrect action labels on untrimmed videos), there is temporal noise due to the lack of accurate temporal action localization — i.e., an untrimmed video may include other non-targeted content or may only show the target action in a small proportion of the video.
Reducing noise effects for large-scale weakly-supervised pre-training is critical but particularly challenging in practice. Recent work indicates that querying short videos (e.g., ~1 minute in length) to obtain more accurate temporal localization of target actions or applying a teacher model to do filtering can yield improved results. However, such data pre-processing methods prevent models from fully utilizing available video data, especially longer videos with richer content.
In “Learning from Weakly-Labeled Web Videos via Exploring Sub-Concepts“, we propose a solution to these issues that uses a simple learning framework to conduct effective pre-training on untrimmed videos. Instead of simply filtering the potential temporal noise, this approach converts such “noisy” data to useful supervision by creating a new set of meaningful “middle ground” pseudo-labels that expand the original weak label space, a novel concept we call Sub-Pseudo Label (SPL). The model is pre-trained on this more “fine-grained” space and then fine-tuned on a target dataset. Our experiments demonstrate that the learned representations are much better than previous approaches. Moreover, SPL has been shown to be effective in improving the action recognition model quality for Google Cloud Video AI, which enables content producers to easily search through massive libraries of their video assets to quickly source content of interest.
 |
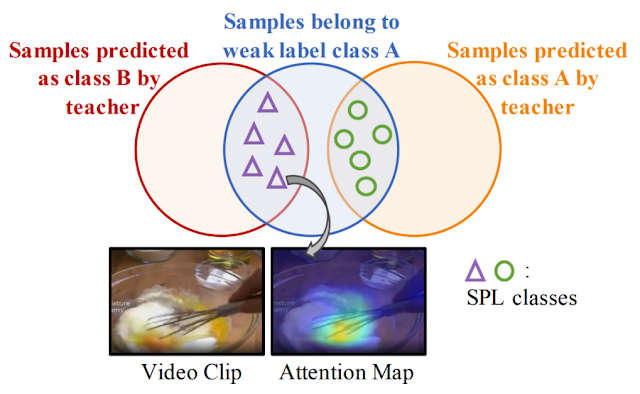 |
| Sampled training clips may represent a different visual action (whisking eggs) from the query label of the whole untrimmed video (baking cookies). SPL converts the potential label noise to useful supervision signals by creating a new set of “middle ground” pseudo-classes (i.e., sub-concepts) via extrapolating two related action classes. Enriched supervision is provided for effective model pre-training. |
Sub-Pseudo Label (SPL)
SPL is a simple technique that advances the teacher-student training framework, which is known to be effective for self-training and to improve semi-supervised learning. In the teacher-student framework, a teacher model is trained on high-quality labeled data and then assigns pseudo-labels to unlabeled data. The student model trains on both high-quality labeled data and the unlabeled data that has the teacher-predicted labels. While previous methods have proposed a number of ways to improve the pseudo-label quality, SPL takes a novel approach that combines knowledge from both weak labels (i.e., query text used to acquire data) and teacher-predicted labels, which results in better pseudo-labels overall. This method focuses on video recognition where temporal noise is challenging, but it can be extended easily to other domains, like image classification.
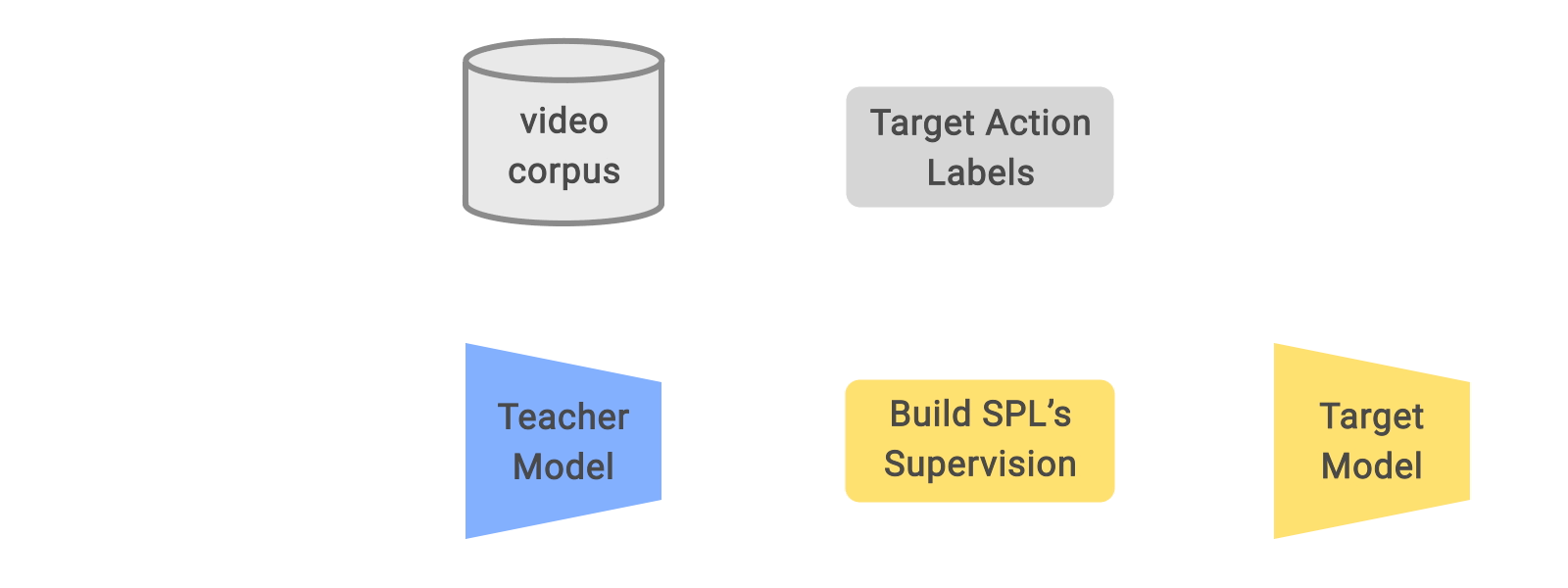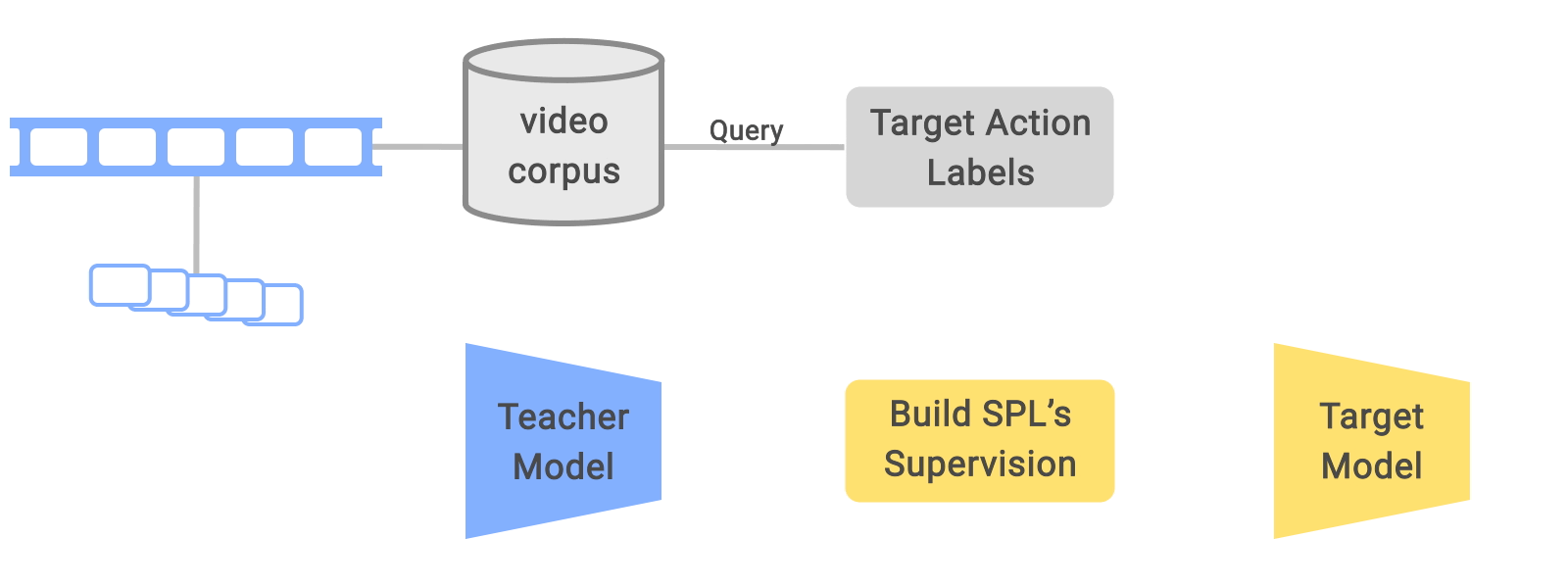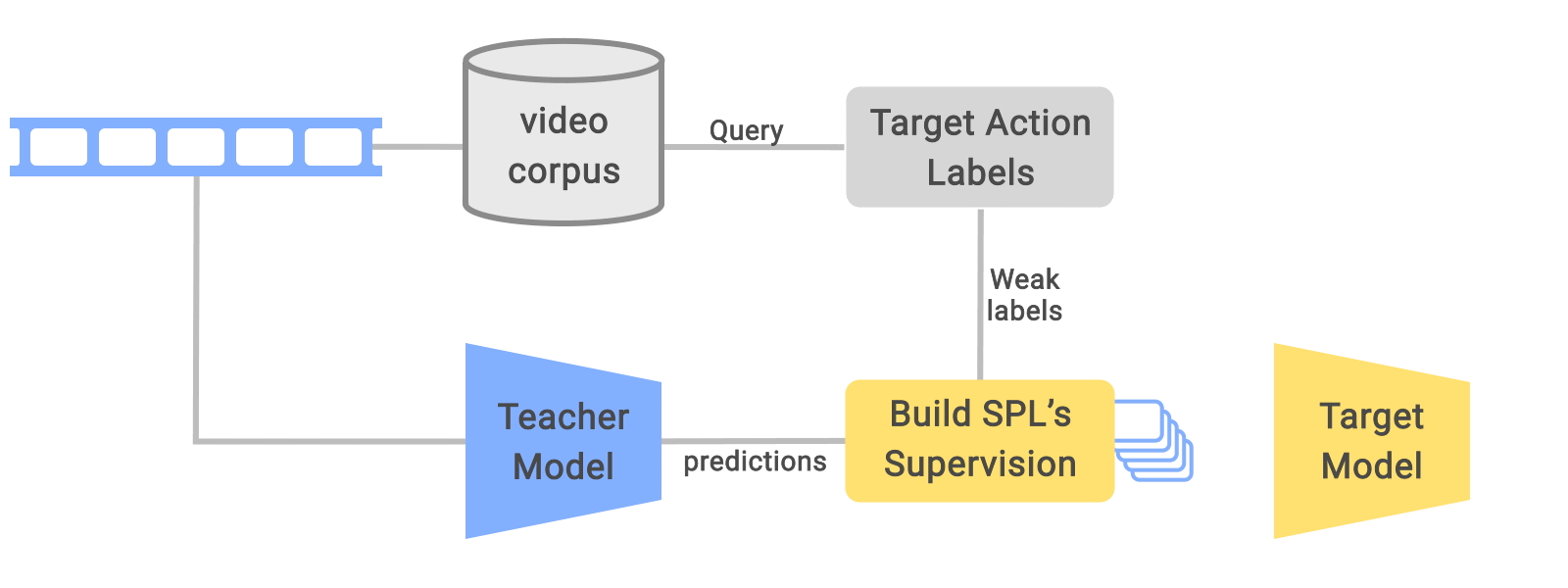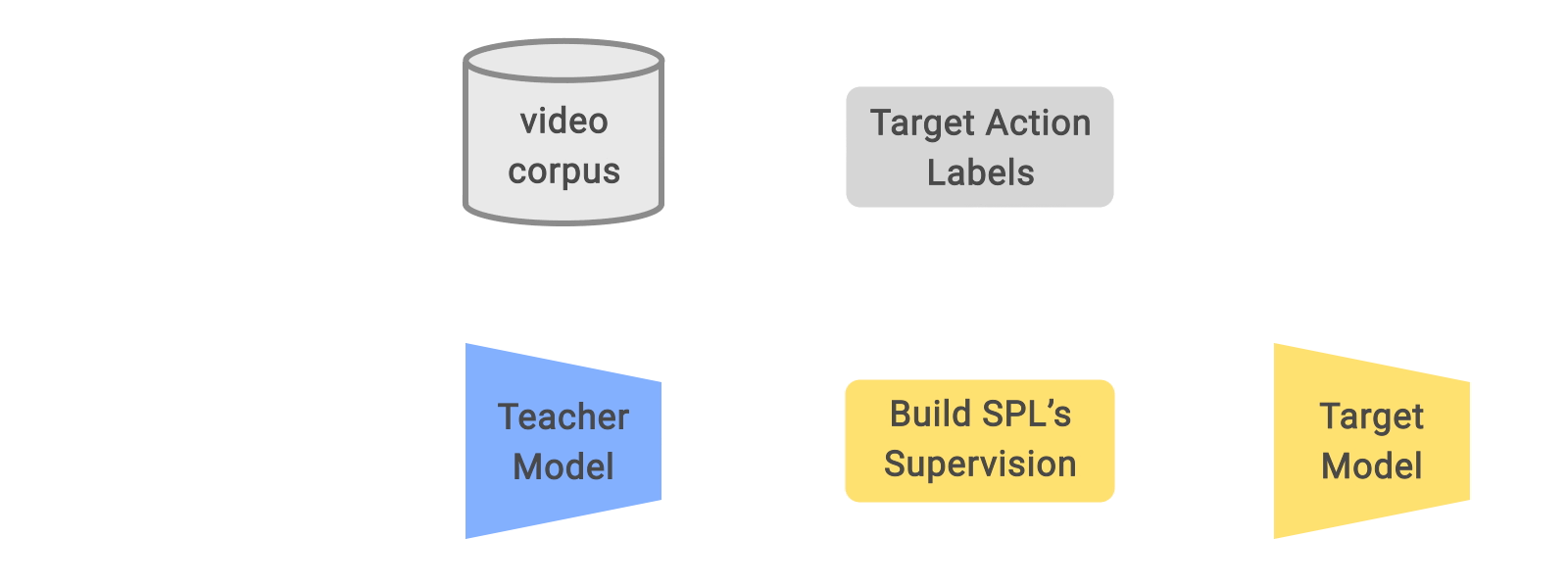 |
| The overall pre-training framework for learning from weakly labeled videos via SPLs. Each trimmed video clip is re-labeled using SPL given the teacher-predicted labels and the weak labels used to query the corresponding untrimmed video. |
The SPL method is motivated by the observation that within an untrimmed video “noisy” video clips have semantic relations with the target action (i.e., the weak label class), but may also include essential visual components of other actions, such as the teacher model–predicted class. Our approach uses the extrapolated SPLs from weak labels together with the distilled labels to capture the enriched supervision signals, encouraging learning better representations during pre-training that can be used for downstream fine-tuning tasks.
It is straightforward to determine the SPL class for each video clip. We first perform inference on each video clip using the teacher model trained from a target dataset to get a teacher prediction class. Each clip is also labeled by the class (i.e., query text) of the untrimmed source video. A 2-dimensional confusion matrix is used to summarize the alignments between the teacher model inferences and the original weak annotations. Based on this confusion matrix, we conduct label extrapolation between teacher model predictions and weak labels to obtain the raw SPL label space.
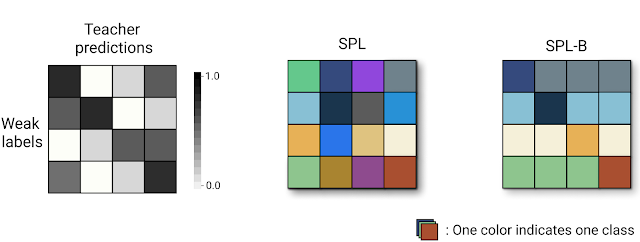 |
| Left: The confusion matrix, which is the basis of the raw SPL label space. Middle: The resulting SPL label spaces (16 classes in this example). Right: SPL-B, another SPL version, that reduces the label space by collating agreed and disagreed entries of each row as independent SPL classes, which in this example results in only 8 classes. |
Effectiveness of SPL
We evaluate the effectiveness of SPL in comparison to different pre-training methods applied to a 3D ResNet50 model that is fine-tuned on Kinetics-200 (K200). One pre-training approach simply initializes the model using ImageNet. The other pre-training methods use 670k video clips sampled from an internal dataset of 147k videos, collected following standard processes similar to those described for Kinetics-200, that cover a broad range of actions. Weak label training and teacher prediction training use either the weak labels or teacher-predicted labels on the videos, respectively. Agreement filtering uses only the training data for which the weak labels and teacher-predicted labels match. We find that SPL outperforms each of these methods. Though the dataset used to illustrate the SPL approach was constructed for this work, in principle the method we describe applies to any dataset that has weak labels.
| Pre-training Method | Top-1 | Top-5 | ||
| ImageNet Initialized | 80.6 | 94.7 | ||
| Weak Label Train | 82.8 | 95.6 | ||
| Teacher Prediction Train | 81.9 | 95.0 | ||
| Agreement Filtering Train | 82.9 | 95.4 | ||
| SPL | 84.3 | 95.7 |
We also demonstrate that sampling more video clips from a given number of untrimmed videos can help improve the model performance. With a sufficient number of video clips available, SPL methods consistently outperform weak label pre-training by providing enriched supervision.
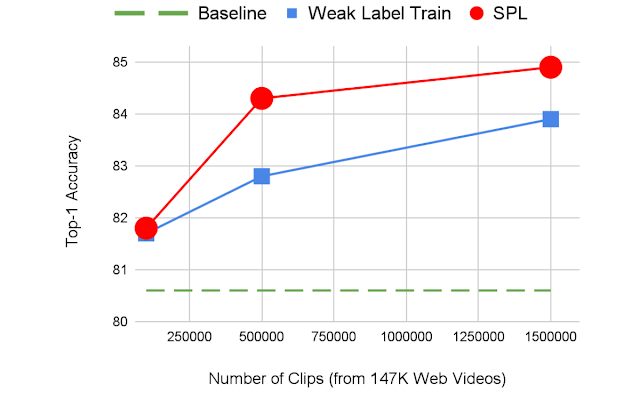 |
| As more clips are sampled from 147K videos, the label noise is increased gradually. SPL becomes more and more effective at utilizing the weakly-labeled clips to achieve better pre-training. |
We visualize the visual concepts learned from SPL with attention visualization by applying Grad-CAM on the trained model. It is interesting to observe some meaningful “middle ground” concepts that can be learned by SPL.
 |
| Examples of attention visualization for SPL classes. Some meaningful “middle ground” concepts can be learned by SPL, such as mixing up the eggs and flour (left) and using the abseiling equipment (right). |
Conclusion
We demonstrate that SPLs can provide enriched supervision for pre-training. SPL does not increase training complexity and can be treated as an off-the-shelf technique to integrate with teacher-student–based training frameworks. We believe this is a promising direction for discovering meaningful visual concepts by bridging weak labels and the knowledge distilled from teacher models. SPL has also demonstrated promising generalization to the image recognition domain and we expect future extensions that apply to tasks that have noise in labels. We have successfully applied SPL for Google Cloud Video AI where it has improved the accuracy of the action recognition models, helping users to better understand, search, and monetize their video content library.
Acknowledgements
We gratefully acknowledge the contributions of other co-authors, including Kunpeng Li, Xuehan Xiong, Chen-Yu Lee, Zhichao Lu, Yun Fu, Tomas Pfister. We also thank Debidatta Dwibedi, David A Ross, Chen Sun, Jonathan C. Stroud, and Wei Hua for their valuable comments and help on this work, and Tom Small for figure creation.
