
 The greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences of prior-generation GPUs.
The greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences of prior-generation GPUs.
AI is transforming every industry, enabling powerful new applications and use cases that simply weren’t possible with traditional software. As AI continues to proliferate, and with the size and complexity of AI models on the rise, significant advances in AI compute performance are required to keep up.
That’s where the NVIDIA platform comes in.
With a full-stack approach spanning chips, systems, software, and even the entire data center, NVIDIA delivers both the highest performance and the greatest versatility for all AI workloads, including AI training. NVIDIA demonstrated this in the MLPerf Training v1.1, the latest edition of an industry-standard, peer-reviewed benchmark suite that measures ML training performance across a wide range of networks. Systems powered by the NVIDIA A100 Tensor Core GPU, including the Azure NDm A100 v4 cloud instance, delivered chart-topping results, set new records, and were the only ones to complete all eight MLPerf Training tests.
All major cloud service providers offer NVIDIA GPU-accelerated instances powered by the A100, making the public cloud a great place to tap into the performance and capabilities of the NVIDIA platform. In this post, I show how a strategy of selecting current-generation instances based on the A100 not only delivers the fastest time to train AI models in the cloud but is also the most cost-effective.
NVIDIA A100 turbocharges AI training
The NVIDIA A100 is based on the Ampere architecture, which incorporates a host of innovations that speed up AI training compared to the prior-generation NVIDIA V100, such as third-generation Tensor Cores, a new generation of NVLink, and much greater memory bandwidth. These enhancements deliver a giant performance leap, enabling the reduction in the time to train a wide range of AI networks.
In this post, I use ResNet-50 to represent image classification, BERT Large for natural language processing, and DLRM for recommender systems.

GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536.
Faster training times speed time to insight, maximizing the productivity of an organization’s data science teams and getting the trained network deployed sooner. There’s also another important benefit: lower costs!
Cloud instances are commonly priced per unit of time, with hourly pricing typical for on-demand usage. The cost to train a model is the product of both hourly instance pricing and the time required to train a model.
Although it can be tempting to select the instances with the lowest hourly price, this might not lead to the lowest cost to train. An instance might be slightly cheaper on a per-hour basis but take significantly longer to train a model. The total cost to train is higher than it would be with the higher-priced instance that gets the job done more quickly. In addition, there’s the time lost waiting for the slower instance to complete the training run.
In the performance numbers shown earlier, the NVIDIA A100 can train models much more quickly than NVIDIA V100. That’s almost 3x as fast in the case of BERT Large Fine Tuning. At the same time, A100-based instances from major cloud providers are often only priced at modest premiums to their prior-generation, V100-based counterparts.
In this post, I discuss how using A100-based cloud instances enables you to save time and money while training AI models, compared to V100-based cloud instances.
Translating performance into savings
Given the immense computational demands of AI training, it is common to train models using multiple GPUs working in concert to reduce training times significantly.
The NVIDIA platform has been designed to deliver industry-leading per-accelerator performance and achieve the best performance and highest ROI at scale, thanks to technologies like NVLink and NVSwitch. That’s why, in this post, I estimate the cost savings that instances with eight NVIDIA A100 GPUs can deliver compared to instances with eight NVIDIA V100 GPUs.
For this analysis, I estimate the relative costs to train ResNet-50, fine tune BERT Large, and train DLRM on V100- and A100-based instances from three major cloud service providers: Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
| CSP | Instance | GPU Configuration |
| Amazon Web Services | p4d.24xlarge | 8x NVIDIA A100 40GB |
| p3dn.24xlarge | 8x NVIDIA V100 32GB | |
| p3.16xlarge | 8x NVIDIA V100 16GB | |
| Google Cloud Platform | a2-highgpu-8g | 8x NVIDIA A100 40GB |
| n1-highmem-96 | 8x NVIDIA V100 16GB | |
| Microsoft Azure | Standard_ND96asr_v4 | 8x NVIDIA A100 40GB |
| ND40rs v2 | 8x NVIDIA V100 32GB |
Estimate methodology
To estimate the training performance of the cloud instances, I used measured time to train data on NVIDIA DGX systems with GPU configurations that correspond to those in the instances. As a result of the deep engineering collaboration with these cloud partners, the performance of NVIDIA-powered cloud instances should be similar to the performance achievable on the DGX systems.
Then, with the measured time-to-train data, I used on-demand, per-hour instance pricing to estimate the cost to train ResNet-50, fine tune BERT Large, and train DLRM.
Estimated cost savings
The following charts all tell a similar story: no matter which cloud service provider you choose, selecting instances based on the latest NVIDIA A100 GPUs can translate into significant cost savings when training a range of AI models. This is even though, on a per-hour basis, instances based on the NVIDIA A100 are more expensive than instances using prior-generation V100 GPUs.
Amazon Web Services:
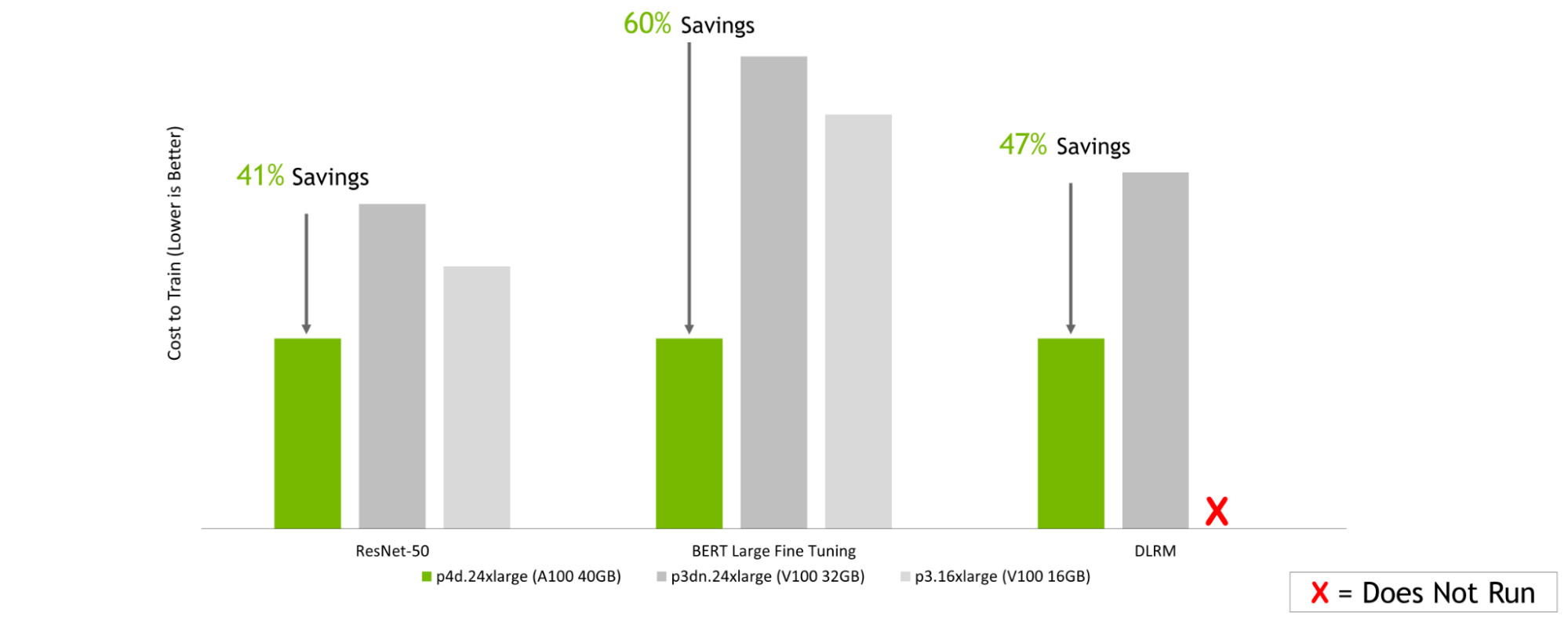
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: Imagenet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Cost estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
Google Cloud Platform:
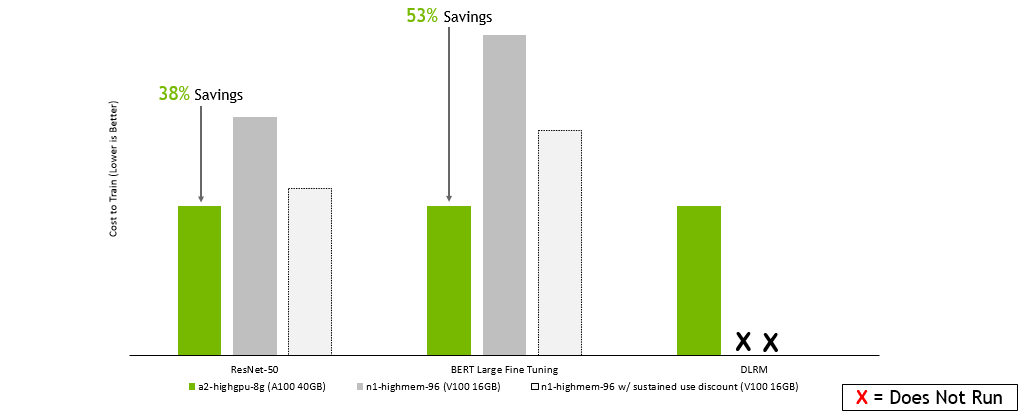
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Cost estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
Microsoft Azure:
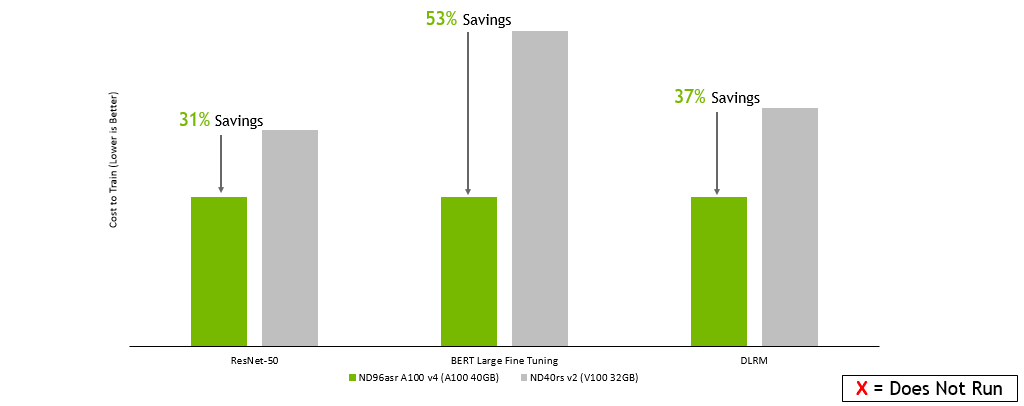
GPU Server: Dual socket AMD EPYC 7742 @ 2.25GHz w/ 8x NVIDIA A100 SXM4-40GB, Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-32GB, and Dual socket Intel Xeon E5-2698 v4 @ 2.2GHz w/ 8x NVIDIA V100 SXM2-16GB. Frameworks: TensorFlow for ResNet-50 v1.5, PyTorch for BERT-Large and DLRM; Precision: Mixed+XLA for ResNet-50 v1.5, Mixed for BERT-Large and DLRM. NVIDIA Driver: 465.19.01; Dataset: ImageNet2012 for ResNet-50 v1.5, SQuaD v1.1 for BERT Large Fine Tuning, Criteo Terabyte Dataset for DLRM, Batch sizes for ResNet-50: A100, V100 = 256; Batch sizes for BERT Large: A100 = 32, V100 = 10; Batch sizes for DLRM: A100, V100 = 65536; Costs estimated using performance data run on the earlier configurations as well as on-demand instance pricing as of 2/8/2022.
In addition to delivering lower training costs and saving users a significant amount of time, there’s another benefit to using current-generation instances: they enable fundamentally new AI use cases. For example, AI-based recommendation engines are becoming increasingly popular and NVIDIA GPUs are commonly used to train them. Figure 5 summarizes the cost and time savings that A100-instances deliver across different cloud providers:
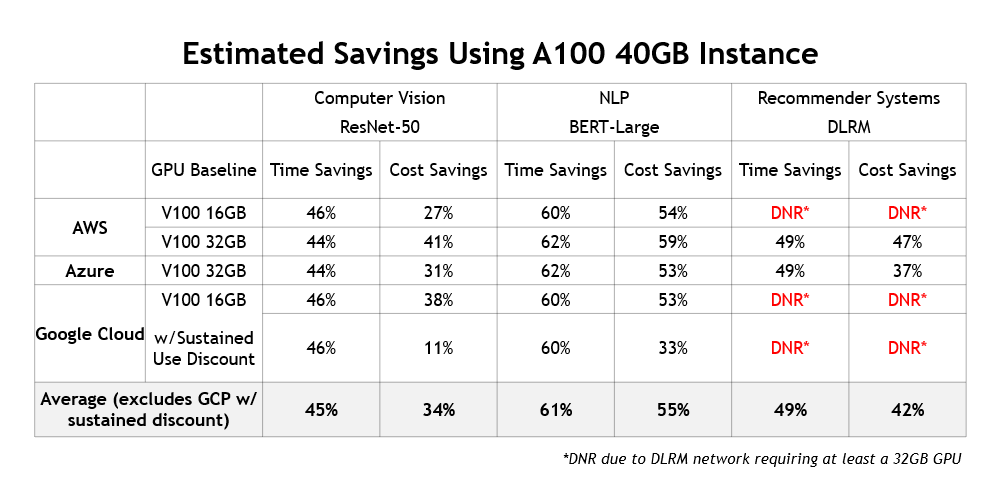
Higher performance also means higher savings
These results presented here show that the much greater performance delivered by current-generation NVIDIA GPU-accelerated instances more than outweighs the per-hour pricing differences compared to older instances that use prior-generation GPUs.
Instances based on the latest NVIDIA A100 GPUs not only maximize the productivity of your data science teams by minimizing training time, but they’re also the most cost-effective way to train your models in the cloud.
To learn more about the many options for using NVIDIA acceleration in the cloud, see Cloud Computing.