
 The Data Processing Unit, or DPU, has recently become popular in data center circles. But not everyone agrees on what tasks a DPU should perform or how it should do them. Idan Burstein, DPU Architect at NVIDIA, presents the applications and use cases that drive the architecture of the NVIDIA BlueField DPU.
The Data Processing Unit, or DPU, has recently become popular in data center circles. But not everyone agrees on what tasks a DPU should perform or how it should do them. Idan Burstein, DPU Architect at NVIDIA, presents the applications and use cases that drive the architecture of the NVIDIA BlueField DPU.
Today’s data centers are evolving rapidly and require new types of processors called data processing units (DPUs). The new requirements demand a specific type of DPU architecture, capable of offloading, accelerating, and isolating specific workloads. On August 23 at the Hot Chips 33 conference, NVIDIA silicon architect Idan Burstein discusses changing data center requirements and how they have driven the architecture of the NVIDIA BlueField DPU family.
Why is a DPU needed?
Data centers today have changed from running applications in silos on dedicated server clusters. Now, resources such as CPU compute, GPU compute, and storage are disaggregated so that they can be composed (allocated and assembled) as needed. They are then recomposed (reallocated) as the applications and workloads change.
GPU-accelerated AI is becoming mainstream and enhancing myriad business applications, not just scientific applications. Servers that were primarily virtualized are now more likely to run in containers on bare metal servers, which still need software-defined infrastructure even though they no longer have a hypervisor or VMs. Cybersecurity tools such as firewall agents and anti-malware filters must run on every server to support a zero-trust approach to information security. These changes have huge consequences for the way networking, security, and management need to work, driving the need for DPUs in every server.
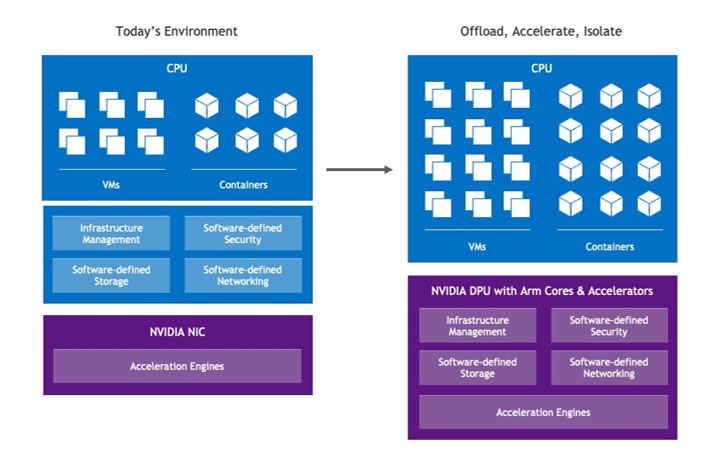
The best definition of the DPU’s mission is to offload, accelerate, and isolate infrastructure workloads.
- Offload: Take over infrastructure tasks from the server CPU so more CPU power can be used to run applications.
- Accelerate: Run infrastructure functions more quickly than the CPU can, using hardware acceleration in the DPU silicon.
- Isolate: Move key data plane and control plane functions to a separate domain on the DPU, both to relieve the server CPU from the work and to protect the functions in case the CPU or its software are compromised.
A DPU should be able to do all three tasks.
Moving CPU cores around is not enough
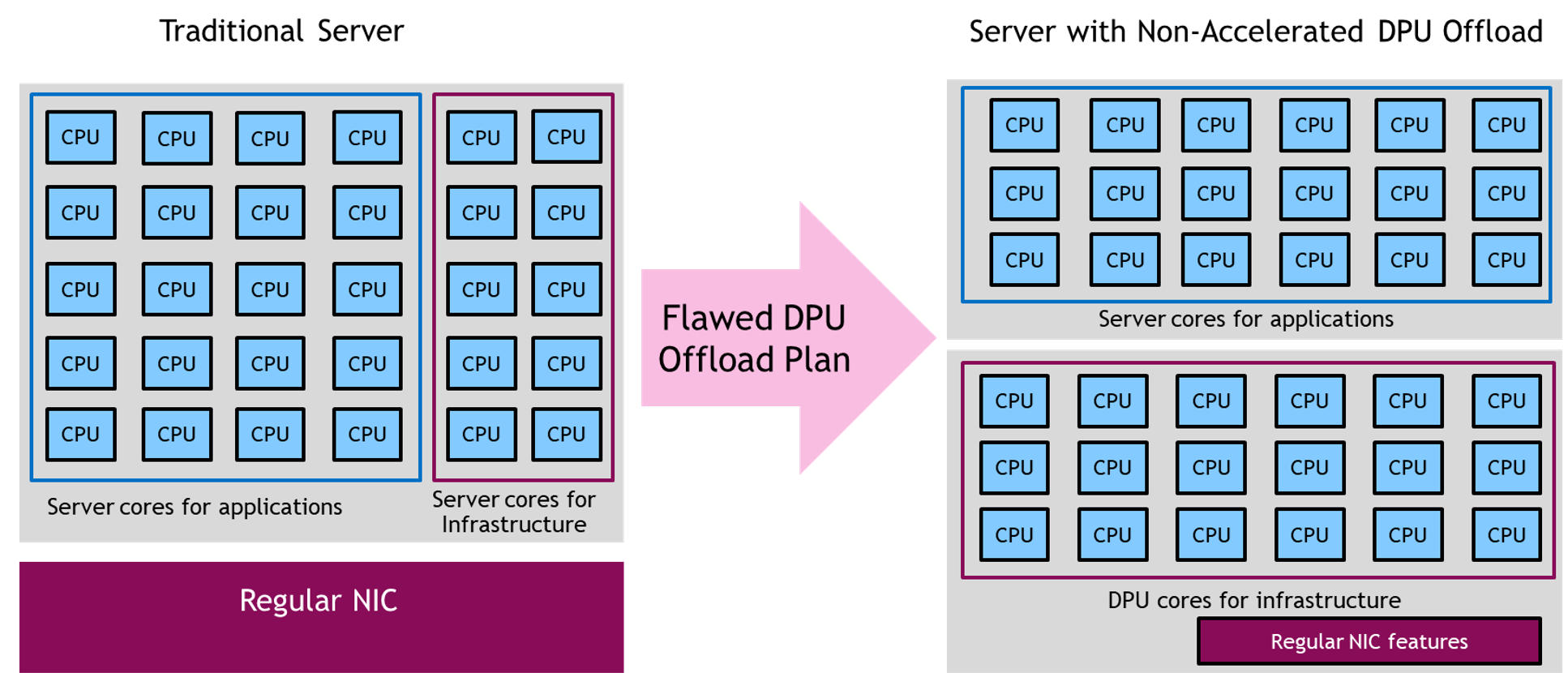
One approach tried by some DPU vendors is to place a large number of CPU cores on the DPU to offload the workloads from the server CPU. Whether these are Arm, RISC, X86, or some other type of CPU core, the approach is fundamentally flawed because the server’s CPUs or GPUs are already efficient for CPU-optimal or GPU-optimal workloads. While it’s true that Arm (or RISC or other) cores on a DPU might be more power efficient than a typical server CPU, the power savings are not worth the added complexity unless the Arm cores have an accelerator for that specific workload.
In addition, servers built on Arm CPUs are already available, for example, Amazon EC2 Graviton-based instances, Oracle A1 instances, or servers built on Ampere Computing’s Altra CPUs and Fujitsu’s A64FX CPUs. Applications that run more efficiently on Arm can already be deployed on server Arm cores. They should only be moved to DPU Arm cores if it’s part of the control plane or an infrastructure application that must be isolated from the server CPU.
Offloading a standard application workload from n number of server X86 cores to n or 2n Arm cores on a DPU doesn’t make technical or financial sense. Neither does offloading AI or serious machine learning workloads from server GPUs to DPU Arm cores. Moving workloads from a server’s CPU and GPU to the DPU’s CPU without any type of acceleration is at best a shell game and at worst decreases server performance and efficiency.
Best types of acceleration for a DPU
It’s clear that a proper DPU must use hardware acceleration to add maximum benefit to the data center. But what should it accelerate? The DPU is best suited for offloading workloads involving data movement, and security. For example, networking is an ideal task to offload to DPU silicon, along with remote direct memory access (RDMA), used to accelerate data movement between servers for AI, HPC, and big data, and storage workloads.
When the DPU has acceleration hardware for specific tasks, it can offload and run those with much higher efficiency than a CPU core. A properly designed DPU can perform the work of 30, 100, or even 300 CPU cores when the workload meets the DPU’s hardware acceleration capabilities.
The DPU’s CPU cores are ideal for running control plane or security workloads that must be isolated from the server’s application and OS domain. For example in a bare metal server, the tenants don’t want a hypervisor or VM running on their server to do remote management, telemetry, or security, because it hurts performance or may interfere with their applications. Yet the cloud operator still needs the ability to monitor the server’s performance and detect, block, or isolate security threats if they invade that server.
A DPU can run this software in isolation from the application domain, providing security and control while not interfering with the server’s performance or operations.
Learn more at Hot Chips
To learn more about how the NVIDIA BlueField DPU chip architecture meets the performance, security, and manageability requirements of modern data center, attend Idan Burstein’s session at Hot Chips 33. Idan explores what DPUs should offload or isolate. He explains what current and upcoming NVIDIA DPUs accelerate, allowing them to improve performance, efficiency, and security in modern data centers.
 Edge computing is quickly becoming standard technology for organizations heavily invested in IoT, allowing organizations to process more data and generate better insights.
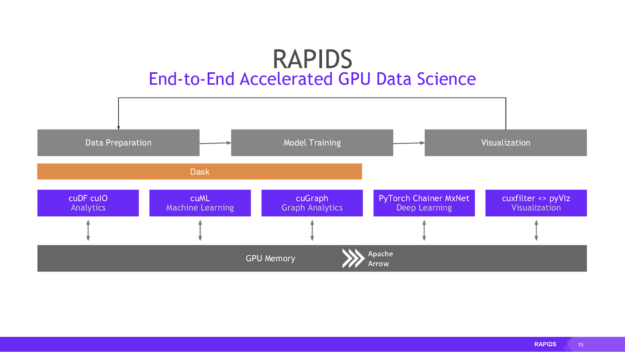
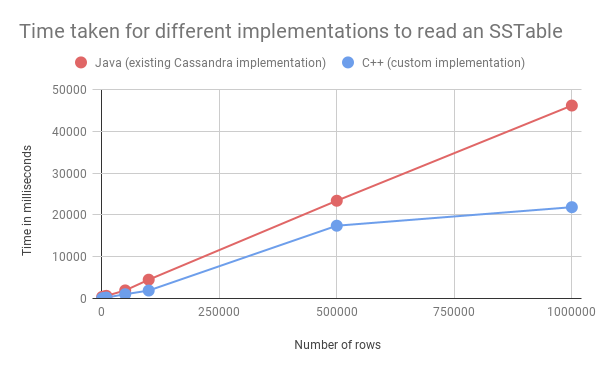
Edge computing is quickly becoming standard technology for organizations heavily invested in IoT, allowing organizations to process more data and generate better insights.  Editor’s Note: Watch the Analysing Cassandra Data using GPUs workshop. Organizations keep much of their high-speed transactional data in fast NoSQL data stores like Apache Cassandra®. Eventually, requirements emerge to obtain analytical insights from this data. Historically, users have leveraged external, massively parallel processing analytics systems like Apache Spark for this purpose. However, today’s analytics …
Editor’s Note: Watch the Analysing Cassandra Data using GPUs workshop. Organizations keep much of their high-speed transactional data in fast NoSQL data stores like Apache Cassandra®. Eventually, requirements emerge to obtain analytical insights from this data. Historically, users have leveraged external, massively parallel processing analytics systems like Apache Spark for this purpose. However, today’s analytics … 
 NVIDIA researchers are presenting five papers on our groundbreaking research in speech recognition and synthesis at INTERSPEECH 2021.
NVIDIA researchers are presenting five papers on our groundbreaking research in speech recognition and synthesis at INTERSPEECH 2021. 
