Im trying to create a conda env with tf-gpu 2.5. When conda installing jupyter, I get all these package conflicts. I didn’t have this problem with tf 2.3. Does jupyter not support the latter versions of tensorflow?
I want to place my own objects in empty spaces. I can detect objects and empty spaces in the image, but I cannot implement them on empty spaces, which method should I use?
NVIDIA today announced the availability of NVIDIA AI Enterprise, a comprehensive software suite of AI tools and frameworks that enables the hundreds of thousands of companies running VMware vSphere to virtualize AI workloads on NVIDIA-Certified Systems™.
I am trying to quantize my model for tflite with representative dataset with a section of my training dataset ( shape (7000,51,300,1) ). using the generator let’s say data_rep = np.array(data_prepped_train[0:100])
The trouble is I am having the below error.
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
I am trying to design a model to minimize the output value of a certain function which takes an input array and performs certain math operations with each elements of the input array and returns a final result. I have written this function using numpy and am trying to define a loss like –
function = function_using_numpy(input_array) #returns scalar float
loss_function(truth, prediction):
loss = k.abs(function(truth) – function (prediction))
return loss
The problem is tensorflow cannot convert a tensor to numpy array to compute the loss. Is the a way around this? Would be grateful for some pointers. Thanks in advance
Apply for the Sept. 22-24 MONAI virtual bootcamp featuring presentations, hands-on labs, and a mini-challenge day.
Due to the success of the 2020 MONAI Virtual Bootcamp, MONAI is hosting another Bootcamp this year from September 22 to September 24, 2021—the week before MICCAI.
The MONAI Bootcamp will be a three-day virtual event with presentations, hands-on labs, and a mini-challenge day. Applicants are encouraged but not required to have some basic knowledge in deep learning and Python programming.
Everyone is welcome to join and learn more about MONAI!
With the growth of MONAI, there will be content for everyone.
Day one begins with a beginner-friendly introduction to MONAI, for those just getting started with deep learning in medical imaging.
Day two focuses on more advanced topics in MONAI and expands on other releases, like MONAI Label and the upcoming MONAI Deploy project.
Day three consists of a series of increasingly difficult mini-challenges, with beginner-friendly challenges and some that hopefully challenge even experienced researchers.
Find a tentative schedule below. A more detailed agenda will be available closer to the event.
Agenda
Day 1: September 22, 2021, 7:30am – 12:30 pm PST Welcome and Introductions What is MONAI? Lab 1 – Getting started with MONAI Lightning Talks Lab 2 – MONAI Deep Dive Lab 3 – End-to-End Workflow with MONAI
Day 2: September 23, 2021, 7:30am – 12:30 pm PST Opening Remarks and Overview MONAI – Advanced Topics on Medical Imaging MONAI Label MONAI Deploy
Day 3: September 24, 2021, 7:30am – 12:30 pm PST MONAI Mini-Challenges Day
The deadline to register is September 8. Apply today!
NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server with Google Kubernetes Engine(GKE).
The rapid growth in artificial intelligence is driving up the size of data sets, as well as the size and complexity of networks. AI-enabled applications like e-commerce product recommendations, voice-based assistants, and contact center automation require tens to hundreds of trained AI models. Inference serving helps infrastructure managers deploy, manage and scale these models with a guaranteed real-time quality-of-service (QoS) in production. Additionally, infrastructure managers look to provision and manage the right compute infrastructure on which to deploy these AI models, with maximum utilization of compute resources and flexibility to scale up or down to optimize operational costs of deployment. Taking AI to production is both an inference serving and infrastructure management challenge.
NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server, a universal inference serving platform for CPUs and GPUs with Google Kubernetes Engine(GKE), a managed environment to deploy, scale and manage containerized AI applications in a secure Google infrastructure.
Inference Serving on CPUs and GPUs on Google Cloud with NVIDIA Triton Inference Server
Operationalizing AI models within enterprise applications poses a number of challenges – serving models trained in multiple frameworks, handling different types of inference query types and building a serving solution that can optimize across multiple deployment platforms like CPUs and GPUs.
Triton Inference Server addresses these challenges by providing a single standardized inference platform that can deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, OpenVINO or a custom C++/Python framework), from local storage or Google Cloud’s managed storage on any GPU- or CPU-based infrastructure.
Figure 1. Triton Inference Server deployed on Google Kubernetes Engine (GKE)
One-Click Deployment of NVIDIA Triton Inference Server on GKE Clusters
Triton on Google Kubernetes Engine (GKE) delivers the benefit of a universal inference serving platform for AI models deployed on both CPUs and GPUs combined with the ease of Kubernetes cluster management, load balancing, and auto scaling compute based on demand.
The Triton Inference Server App for GKE is a helm chart deployer that automatically installs and configures Triton for use on a GKE cluster with NVIDIA GPU node pools, including the NVIDIA A100 Tensor Core GPUs and NVIDIA T4 Tensor Core GPUs, and leverages Istio on Google Cloud for traffic ingress and load balancing. It also includes a horizontal pod autoscaler (HPA) which relies on stack driver custom metrics adapter to monitor GPU duty cycle and auto scale the GPU nodes in the GKE cluster based on inference queries and SLA requirements.
To learn more about the One-Click Triton Inference Server in Google Kubernetes Engine (GKE), check out this in-depth blog by Google Cloud and NVIDIA and see how the solution scales to meet stringent latency budgets, and optimize operational costs for your AI deployments.
You can also register for “Building a Computer Vision Service Using NVIDIA NGC and Google Cloud” webinar on August 25 to learn how to build an end-to-end computer vision service on Google Cloud by combining NVIDIA GPU-optimized pretrained models and Transfer Learning Toolkit (TLT) from NGC Catalog and the Triton Inference Server App for GKE.
This is the fourth post in the Accelerating IO series. It addresses storage issues and shares recent results and directions with our partners. We cover the new GPUDirect Storage release, benefits, and implementation. Accelerated computing needs accelerated IO. Otherwise, computing resources get starved for data. Given that the fraction of all workflows for which data … Continued
This is the fourth post in the Accelerating IO series. It addresses storage issues and shares recent results and directions with our partners. We cover the new GPUDirect Storage release, benefits, and implementation.
Accelerated computing needs accelerated IO. Otherwise, computing resources get starved for data. Given that the fraction of all workflows for which data fits in memory is shrinking, optimizing storage IO is of increasing importance. The value of stored data, efforts to pilfer or corrupt data, and regulatory requirements to protect it are also all ratcheting up. To that end, there is growing demand for data center infrastructure that can provide greater isolation of users from data that they shouldn’t access.
GPUDirect Storage
GPUDirect Storage streamlines the flow of data between storage and GPU buffers for applications that consume or produce data on the GPU without needing CPU processing. No extra copies that add latency and impede bandwidth are needed. This simple optimization leads to game-changing role reversals where data can be fed to GPUs faster from remote storage rather than CPU memory.
The newest member of the GPUDirect family
The GPUDirect family of technologies enables access and efficient data movement into and out of the GPU. Until recently, it was focused on memory-to-memory transfers. With the addition of GPUDirect Storage (GDS), access and data movement with storage are also accelerated. GPUDirect Storage makes the significant step of adding file IO between local and remote storage to CUDA.
Release v1.0 with CUDA 11.4
GPUDirect Storage has been vetted for more than two years and is currently available as production software. Previously available only through a separate installation, GDS is now incorporated into CUDA version 11.4 and later, and it can be either part of the CUDA installation or installed separately. For an installation of CUDA version X-Y, the libcufile-X-Y.so user library, gds-tools-X-Y are installed by default and the nvidia-fs.ko kernel driver is an optional install. For more information, see the GDS troubleshooting and installation documentation.
GPUDirect Storage enables a direct datapath between storage and GPU memory. Data is moved using the direct memory access (DMA) engine in local NVMe drives or in a NIC that communicates with remote storage.
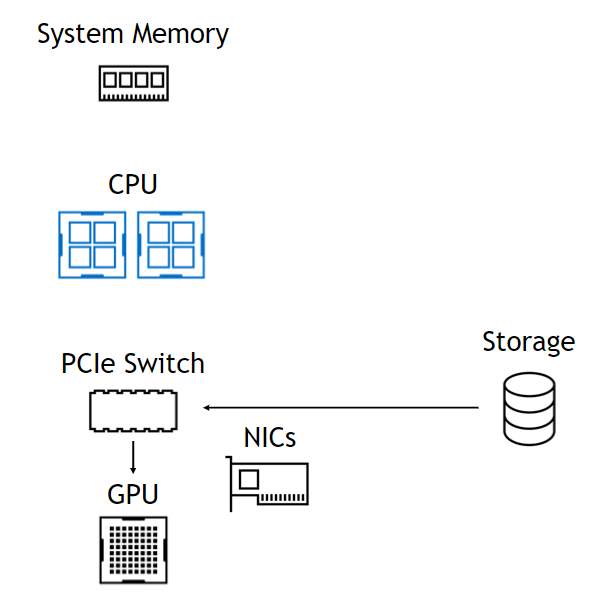
Use of that DMA engine means that, although the setup of the DMA is a CPU operation, the CPU and GPU are totally uninvolved in the datapath, leaving them free and unencumbered (Figure 1). On the left, data from storage comes in through a PCIe switch, goes through the CPU to system memory and all the way back down to the GPU. On the right, the datapath skips the CPU and system memory. The benefits are summarized at the bottom.
WITHOUT GPUDIRECT STORAGE
Limited by bandwidth into and out of the CPU. Incurs the latency of a CPU bounce buffer. Memory capacity is limited to O(1TB). Storage is not part of CUDA. No topology-based optimization.
WITH GPUDIRECT STORAGE
Bandwidth into GPUs limited only by NICs. Lower latency due to direct copy. Access to O(PB) capacity. Simple CUDA programming model. Adaptively route through NVLink, GPU buffers.
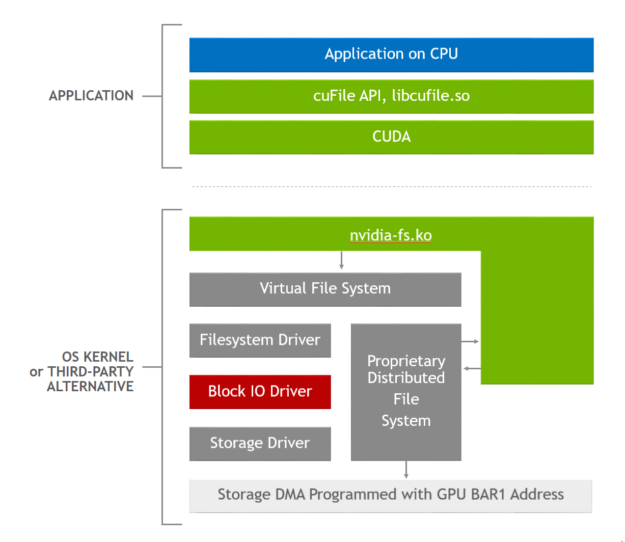
Figure 1. GDS software stack, where the applications use cuFile APIs, and the GDS-enabled storage drivers call out to the nvidia-fs.ko kernel driver to obtain the correct DMA address.
GPUDirect storage offers three basic performance benefits:
Increased bandwidth: By removing the need to go through a bounce buffer in the CPU, alternate paths become available on some platforms, including those that may offer higher bandwidth through a PCIe switch or over NVLink. While DGX platforms have both PCIe switches and NVLinks, not all platforms do. We recommend using both to maximize performance. The Mars lander example achieved an 8x bandwidth gain.
Decreased latency: Reduce latency by avoiding the delay of an extra copy through CPU memory and the overhead of managing memory, which can be severe in extreme cases. A 3x reduction in latency is common.
Decreased CPU utilization: Use of a bounce buffer introduces extra operations on the CPU, both to perform the extra copy and to manage the memory buffers. When CPU utilization becomes the bottleneck, effective bandwidth can drop significantly. We’ve measured 3x improvements in CPU utilization with multiple file systems.
Without GDS, there’s only one available datapath: from storage to the CPU and from the CPU to the relevant GPU with cudaMemcpy. With GDS, there are additional optimizations available:
The CPU threads used to interact with the DMA engine are affinitized to the closest CPU core.
If the storage and GPU hang off different sockets and NVLink is an available connection, then data may be staged through a fast bounce buffer in the memory of a GPU near the storage, and then transferred using CUDA to the final GPU memory target buffer. This can be considerably faster than using the intersocket path, for example, UPI.
There is no cudaMemcpy involved to take care of segmenting the IO transfer to fit in the GPU BAR1 aperture, whose size varies by GPU SKU, or into prepinned buffers in case the target buffer is not pinned with cuFileBufRegister. These operations are managed with the libcufile.so user library code.
Handle unaligned accesses, where the offset of the data within the file to be transferred does not align with a page boundary.
In future GDS releases, the cuFile APIs will support asynchronous and batched operations. This enables a CUDA kernel to be sequenced after a read in the CUDA stream that provides inputs to that kernel, and a write to be sequenced after a kernel that produces data to be written. In time, cuFile APIs will be usable in the context of CUDA Graphs as well.
Table 1 shows the peak and measured bandwidths on NVIDIA DGX-2 and DGX A100 systems. This data shows that the achievable bandwidth into GPUs from local storage exceeds the maximum bandwidth from up to 1 TB of CPU memory in ideal conditions. Commonly measured bandwidths from petabytes of remote memory can be well more than double of the bandwidth that CPU memory provides in practice.
Spilling data that won’t fit in GPU memory out to even petabytes of remote storage can exceed the achievable performance of paging it back to the 1 TB of memory in the CPU. This is a remarkable reversal of history.
Endpoint
DGX-2 (Gen3), GB/s
DGX A100 (Gen4), GB/s
CPU
50, peak
100, peak
Switch/GPU
100, peak
200*, peak
Endpoint
Capacity
Measured
CPU sysmem
O(1TB)
48-50 @ 4 PCIe
96-100 @ 4 PCIe
Local storage
O(100TB)
53+ @ 16 drives
53+ @ 8 drives
RAID cards
O(100TB)
112 (MicroChip) @ 8
N/A
NICs
O(1PB)
90+ @ 8 NICs
185+ @ 8 NICs
Table 1. Access to petabytes of data is possible at bandwidths that exceed those to only 1 TB of CPU memory.
* Performance numbers shown here with NVIDIA GPUDirect Storage on NVIDIA DGX A100 slots 0-3 and 6-9 are not the officially supported network configuration and are for experimental use only. Sharing the same network adapters for both compute and storage may impact the performance of standard or other benchmarks previously published by NVIDIA on DGX A100 systems.
How GDS works
NVIDIA seeks to embrace existing standards wherever possible, and to judiciously extend them where necessary. The POSIX standard’s pread and pwrite provide copies between storage and CPU buffers, but do not yet enable copies to GPU buffers. This shortcoming of not supporting GPU buffers in the Linux kernel will be addressed over time.
A solution, called dma_buf, that enables copies among devices like a NIC or NVMe and GPU, which are peers on the PCIe bus, is in progress to address that gap. In the meantime, the performance upside from GDS is too large to wait for an upstreamed solution to propagate to all users. Alternate GDS-enabled solutions have been provided by a variety of vendors, including MLNX_OFED (Table 2). The GDS solution involves new APIs, cuFileRead or cuFileWrite, that are similar to POSIX pread and pwrite.
Optimizations like dynamic routing, use of NVLink, and async APIs for use in CUDA streams that are only available from GDS makes the cuFile APIs an enduring feature of the CUDA programming model, even after gaps in the Linux file system are addressed.
Here’s what the GDS implementation does. First, the fundamental problem with the current Linux implementation is passing a GPU buffer address as a DMA target down through the virtual file system (VFS) so that the DMA engine in a local NVMe or a network adapter can perform a transfer to or from GPU memory. This leads to an error condition. We have a way around this problem for now: Pass down an address for a buffer in CPU memory instead.
When the cuFile APIs like cuFileRead or cuFileWrite are used, the libcufile.so user-level library captures the GPU buffer address and substitutes a proxy CPU buffer address that’s passed to VFS. Just before the buffer address is used for a DMA, a call from a GDS-enabled driver to nvidia-fs.ko identifies the CPU buffer address and provides a substitute GPU buffer address again so that the DMA can proceed correctly.
The logic in libcufile.so performs the various optimizations described earlier, like dynamic routing, use of prepinned buffers, and alignment. Figure 2 shows the stack used for this optimization. The cuFile APIs are an example of the Magnum IO architectural principles of flexible abstraction that enable platform-specific innovation and optimization, like selective buffering and use of NVLink.
Figure 2. GDS software stack, where the applications use cuFile APIs, and the GDS-enabled storage drivers call out to the nvidia-fs.ko kernel driver to obtain the correct DMA address.
Software ate the world, now new silicon is taking a seat at the table. Ten years ago venture capitalist Marc Andreessen proclaimed that “software is eating the world.” His once-radical concept — now a truism — is that innovation and corporate value creation lie in software. That led some to believe that hardware matters less. Read article >
Using the 100% open-source Pure SONiC, NVIDIA excelled in all the tests at the 2021 SONiC PlugFest.
The SONiC community came together for a unique virtual event to help define test requirements and evaluate the performance of Software for Open Networking in the Cloud (SONiC).
As an open-source network OS, SONiC runs on many different switches from multiple vendors. One of the problems with many open-source projects is that not all vendors are as committed to those projects as others. It can be difficult, and time-consuming to figure out the functionality and scale each vendor provides, as data sheets cannot be trusted.
To address this issue, AVIZ Networks and Keysight Technologies created the first annual SONiC PlugFest, where an independent group tests the interoperability, functionality, and scale of the many vendors. The goal of the SONiC PlugFest was to test and confirm whether the currently available feature set of community SONiC is production-ready.
PlugFest testing
The PlugFest had a suite of test modules, the results of which fell into three general areas of feature, scale, and operations. Results were divided in the categories of platform, management, layer 2 and 3, and system/ops.
NVIDIA is committed to open source at all layers of the stack. Keeping SONiC, SAI and SDK APIs public, removes potential vendor lock-in. In other words, NVIDIA Pure SONiC ensures the freedom to choose the best ASIC/switch platform/applications remains in the hands of the users.
Accelerate software evolution
NVIDIA is home to a team of professionals fluent in SONiC, who are able to craft a unique Pure SONiC release, which is 100% based on upstream open-source code. NVIDIA is the only vendor that provides a production hardened GitHub hash, from which users can build and own their SONiC image.
Drive adoption via a strong ecosystem
At this point of the SONiC project, NVIDIA believes that open source has the power to accelerate innovation and PlugFests like these enable customers to test these solutions in real-world scenarios. NVIDIA will continue with its mission to enhance SONiC features supporting the next generation of networking and to enable the ecosystem based on 100% upstream open-source code.
NVIDIA has qualified and deployed 100% open source SONiC in many of the biggest data centers in the world. Now that the SONiC PlugFest confirmed Pure SONiC delivers everything promised, why consider going a path other than Pure SONiC?
Considering deploying Pure SONiC in 2022? Feel free to leave comments in the forum for discussion or feedback.



 Apply for the Sept. 22-24 MONAI virtual bootcamp featuring presentations, hands-on labs, and a mini-challenge day.
Apply for the Sept. 22-24 MONAI virtual bootcamp featuring presentations, hands-on labs, and a mini-challenge day. NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server with Google Kubernetes Engine(GKE).
NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server with Google Kubernetes Engine(GKE).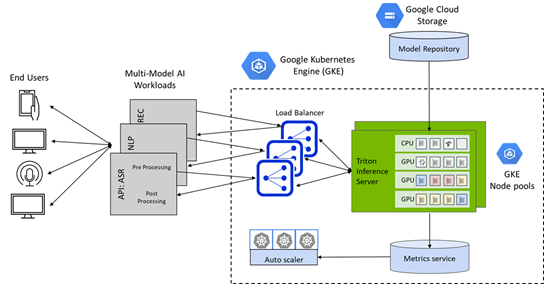
 This is the fourth post in the Accelerating IO series. It addresses storage issues and shares recent results and directions with our partners. We cover the new GPUDirect Storage release, benefits, and implementation. Accelerated computing needs accelerated IO. Otherwise, computing resources get starved for data. Given that the fraction of all workflows for which data …
This is the fourth post in the Accelerating IO series. It addresses storage issues and shares recent results and directions with our partners. We cover the new GPUDirect Storage release, benefits, and implementation. Accelerated computing needs accelerated IO. Otherwise, computing resources get starved for data. Given that the fraction of all workflows for which data … 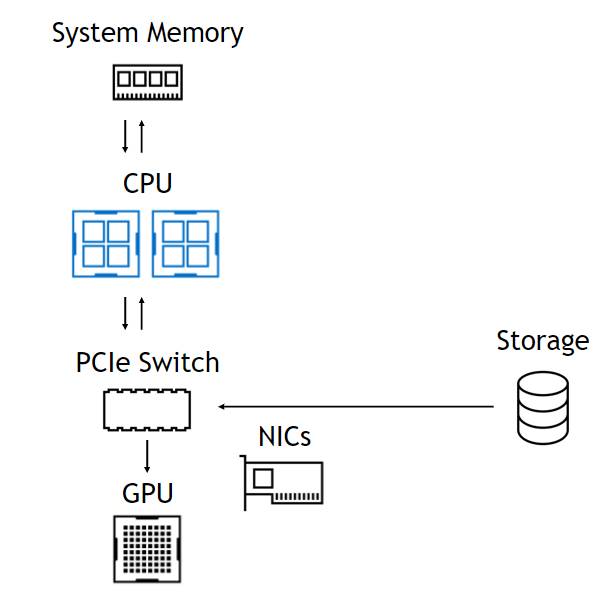
 Using the 100% open-source Pure SONiC, NVIDIA excelled in all the tests at the 2021 SONiC PlugFest.
Using the 100% open-source Pure SONiC, NVIDIA excelled in all the tests at the 2021 SONiC PlugFest.{kind=link}