
 NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server with Google Kubernetes Engine(GKE).
NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server with Google Kubernetes Engine(GKE).
The rapid growth in artificial intelligence is driving up the size of data sets, as well as the size and complexity of networks. AI-enabled applications like e-commerce product recommendations, voice-based assistants, and contact center automation require tens to hundreds of trained AI models. Inference serving helps infrastructure managers deploy, manage and scale these models with a guaranteed real-time quality-of-service (QoS) in production. Additionally, infrastructure managers look to provision and manage the right compute infrastructure on which to deploy these AI models, with maximum utilization of compute resources and flexibility to scale up or down to optimize operational costs of deployment. Taking AI to production is both an inference serving and infrastructure management challenge.
NVIDIA and Google Cloud have collaborated to make it easier for enterprises to take AI to production by combining the power of NVIDIA Triton Inference Server, a universal inference serving platform for CPUs and GPUs with Google Kubernetes Engine(GKE), a managed environment to deploy, scale and manage containerized AI applications in a secure Google infrastructure.
Inference Serving on CPUs and GPUs on Google Cloud with NVIDIA Triton Inference Server
Operationalizing AI models within enterprise applications poses a number of challenges – serving models trained in multiple frameworks, handling different types of inference query types and building a serving solution that can optimize across multiple deployment platforms like CPUs and GPUs.
Triton Inference Server addresses these challenges by providing a single standardized inference platform that can deploy trained AI models from any framework (TensorFlow, TensorRT, PyTorch, ONNX Runtime, OpenVINO or a custom C++/Python framework), from local storage or Google Cloud’s managed storage on any GPU- or CPU-based infrastructure.
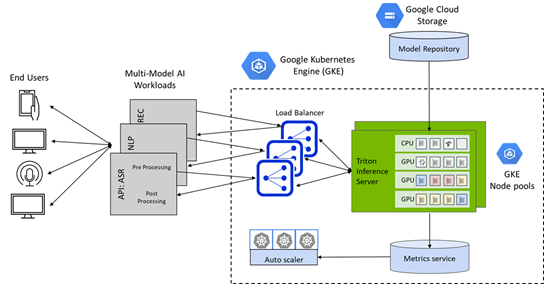
One-Click Deployment of NVIDIA Triton Inference Server on GKE Clusters
Triton on Google Kubernetes Engine (GKE) delivers the benefit of a universal inference serving platform for AI models deployed on both CPUs and GPUs combined with the ease of Kubernetes cluster management, load balancing, and auto scaling compute based on demand.
Triton can be seamlessly deployed as a containerized microservice on a Google Kubernetes Engine (GKE) managed cluster using the new One-Click Triton Inference Server App for GKE on Google Marketplace.
The Triton Inference Server App for GKE is a helm chart deployer that automatically installs and configures Triton for use on a GKE cluster with NVIDIA GPU node pools, including the NVIDIA A100 Tensor Core GPUs and NVIDIA T4 Tensor Core GPUs, and leverages Istio on Google Cloud for traffic ingress and load balancing. It also includes a horizontal pod autoscaler (HPA) which relies on stack driver custom metrics adapter to monitor GPU duty cycle and auto scale the GPU nodes in the GKE cluster based on inference queries and SLA requirements.
To learn more about the One-Click Triton Inference Server in Google Kubernetes Engine (GKE), check out this in-depth blog by Google Cloud and NVIDIA and see how the solution scales to meet stringent latency budgets, and optimize operational costs for your AI deployments.
You can also register for “Building a Computer Vision Service Using NVIDIA NGC and Google Cloud” webinar on August 25 to learn how to build an end-to-end computer vision service on Google Cloud by combining NVIDIA GPU-optimized pretrained models and Transfer Learning Toolkit (TLT) from NGC Catalog and the Triton Inference Server App for GKE.