Supercomputing centers around the world looking for a flexible, energy-efficient alternative to diversify their systems are beginning to turn to Arm for their exascale supercomputers. Arm is the world’s most popular CPU architecture, but the x86 architecture has more than 97 percent of the data center market, thanks to its ecosystem of partners, software and Read article >
Quantum computing promises scientific leaps — simulating molecules of atoms for drug discovery, for instance — in the near future. Handling exponentially more information than today’s computers, quantum computers harness the physics that govern subatomic particles to make parallel calculations. Teams worldwide in academia, industry and national labs are researching quantum computers and algorithms. Many Read article >
Scientists and healthcare researchers — once limited by the number of samples that could be studied in a wet lab, or the quality of microscopes to peer into cells — are harnessing powerful computational tools to draw insights from an ever-growing trove of biological data. Backing this digital biology revolution is a combination of high Read article >
ISC—NVIDIA today announced it is turbocharging the NVIDIA HGX™ AI supercomputing platform with new technologies that fuse AI with high performance computing, making supercomputing more useful to a growing number of industries.
High-performance computing (HPC) and AI have driven supercomputers into wide commercial use as the primary data processing engines enabling research, scientific discoveries, and product development. These systems can carry complex simulations and unlock the new era of AI, where software writes software. Supercomputing leadership means scientific and innovation leadership, which explains the investments made by … Continued
High-performance computing (HPC) and AI have driven supercomputers into wide commercial use as the primary data processing engines enabling research, scientific discoveries, and product development. These systems can carry complex simulations and unlock the new era of AI, where software writes software.
Supercomputing leadership means scientific and innovation leadership, which explains the investments made by many governments, research institutes, and enterprises to build faster and more powerful supercomputing platforms. Extracting the highest possible performance from supercomputing systems while achieving efficient utilization has traditionally been incompatible with the secured, multitenant architecture of modern cloud computing.
A cloud-native supercomputing platform provides the best of both worlds for the first time, combining peak performance and cluster efficiency with a modern zero-trust model for security isolation and multitenancy. The key element enabling this architecture transition is the NVIDIA BlueField data processing unit (DPU). The DPU is a fully integrated data-center-on-a-chip platform that imbues each supercomputing node with two new capabilities:
Infrastructure control plane processor—Secures user access, storage access, networking, and lifecycle orchestration for the computing node, offloading the main compute processor and enabling bare-metal multitenancy.
Isolated line-rate datapath with hardware acceleration—Enables bare-metal performance.
HPC and AI communication frameworks and libraries are latency– and bandwidth-sensitive, and they play a critical role in determining application performance. Offloading the libraries from the host CPU or GPU to the BlueField DPU creates the highest degree of overlap for parallel progression of communication and computation. It also reduces the negative effects of OS jitter and dramatically increases application performance.
The development of the cloud-native supercomputer architecture is based on open community development, including commercial companies, academic organizations, and government agencies. This growing community is essential to developing the next generation of supercomputing.
One example that we share in this post is the MVAPICH2-DPU library, designed and developed byX-ScaleSolutions. The MVAPICH2-DPU library has incorporated offloading for nonblocking collectives of the Message Passing Interface (MPI) standard. This post outlines the basic concepts behind such offloading and how an end user can use the MVAPICH2-DPU MPI library to accelerate the execution of scientific applications, especially with dense nonblocking all-to-all operations.
BlueField DPU
Figure 1 shows an overview of the BlueField DPU architecture and its connectivity with a host computing platform. The DPU has InfiniBand network connectivity through the ConnectX-6 adapter. In addition, it has a set of Arm cores. The Bluefield-2 DPU has a set of eight Arm cores operating at 2.0 GHz each. The Arm cores also have 16 GBytes of shared memory.
MVAPICH2-DPU MPI library
The MVAPICH2-DPU MPI library is a derivative of theMVAPICH2 MPI library. This library is optimized to harness the full potential of BlueField DPUs with InfiniBand networking.
Figure 1. Architecture of the BlueField DPU and its connectivity with a host platform
The latest MVAPICH2-DPU 2021.06 release has the following features:
Based on MVAPICH2 2.3.6, conforming to the MPI 3.1 standard
For more information, see the MVAPICH2-DPU product page.
Sample execution with the OSU Micro-Benchmarks
A copy of the OSU MPI Micro-Benchmarks comes integrated with the MVAPICH2-DPU MPI package. The OMB benchmark suite consists of benchmarks for nonblocking collective operations. These benchmarks are designed to evaluate overlap capabilities between computation and communication used with nonblocking MPI collectives.
Section 6 of the user guide provides step-by-step instructions for running any MPI program with the offloading capabilities of the MVAPICH2-DPU MPI library.
The nonblocking collective benchmarks in the OMB package can be executed to evaluate the following metrics:
Overlap capabilities
Overall execution time when computation steps are incorporated immediately after initiating nonblocking collectives
A set of OMB experiments were run on the HPC-AI Advisory Council cluster with 32 nodes connected with 32 BlueField DPUs supporting HDR 200-Gb/s InfiniBand connectivity. Each host node has dual-socket Intel Xeon 16-core CPUs E5-2697A V4 @2.60 GHz. Each Bluefield-2 DPU has eight Arm cores @2.0 Ghz and 16 GB of memory.
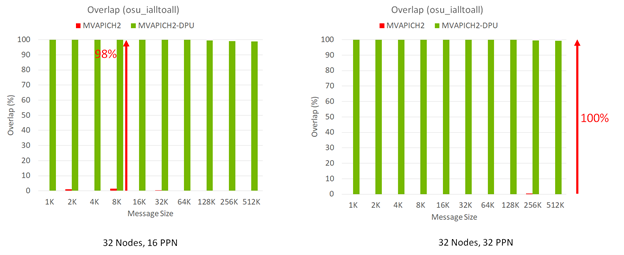
Figure 2 shows the performance results of the MPI_Ialltoall nonblocking collective benchmark running with 512 (32 nodes with 16 processes per node (PPN) each) and 1,024 (32 nodes with 32 PPN each) MPI processes, respectively. As message size increases, the MVAPICH2-DPU library can demonstrate the peak (100%) overlap between computation and the MPI_Ialltoall nonblocking collective. In contrast, the MVAPICH2 default library without such DPU offloading capability can provide little overlap between computation and MPI_Ialltoall non_blocking collective.
Figure 2. Capability of the MVAPICH2-DPU library to extract peak overlap between computation happening at the host and MPI_Ialltoall communication
When computation steps in an MPI application are used with the MPI_Ialltoall nonblocking collective operation in an overlapped manner, the MVAPICH2-DPU MPI library provides significant performance benefits in the overall program execution time. This is possible because the Arm cores in the DPUs can implement the nonblocking all-to-all operations while the Xeon cores on the host are performing computation with peak overlap (Figure 2).
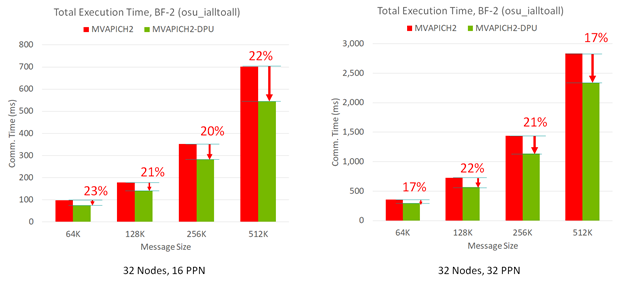
Figure 3 shows that the MVAPICH2-DPU MPI library can deliver up to 23% performance benefits compared to the basic MVAPICH2 MPI library. This was across message sizes and PPNs on a 32-node experiment with the OMB MPI_Iall benchmark.
Figure 3. Capability of the MVAPICH2-DPU library to reduce overall execution time of an MPI application when computation steps are used with the MPI_Ialltoall nonblocking collective operation in an overlapped manner
Accelerating the P3DFFT application kernel
The P3DFFT is a common MPI kernel used in many end-applications using a fast Fourier transform (FFT). A version of this MPI kernel has been designed by the P3DFFT developer to use nonblocking all-to-all collective operations with computational steps to harness maximum overlap.
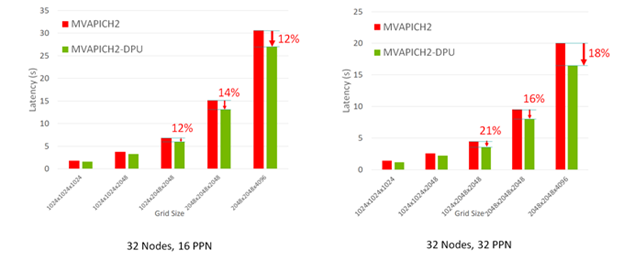
The enhanced version of the P3DFFT MPI kernel was evaluated on the 32-node HPC-AI cluster with the MVAPICH2-DPU MPI library. Figure 4 shows that the MVAPICH2-DPU MPI library reduces the overall execution time of the P3DFFT application kernel up to 21% for various grid sizes and PPNs.
Figure 4. Capability of the MVAPICH2-DPU library to reduce overall execution time of the P3DFFT application.
Summary
The NVIDIA DPU architecture provides novel capabilities to offload functionalities of any middleware to the programmable Arm cores on the DPU. MPI libraries must be redesigned to take advantage of such capabilities to accelerate scientific applications.
The MVAPICH2-DPU MPI library is a leading library to harness such DPU capability. The initial release of the MVAPICH2-DPU library with offloading support for MPI_Ialltoall nonblocking collectives demonstrates 100% overlap between computation and nonblocking alltoall collective. It can accelerate the P3DFFT application kernel execution time by 21% on a 1,024 MPI process run.
This study demonstrates a strong ROI for the DPU architecture with the MVAPICH2-DPU MPI library. Additional offloading capabilities in the upcoming releases for other MPI functions, with advances in the DPU architectures, will accelerate scientific applications on cloud-native supercomputing systems in a significant manner.
For more information about the MVAPICH2-DPU MPI library and its roadmap, send email to [email protected] or fill out the contact form.
NVIDIA CloudXR provides a powerful edge computing platform for extended reality. Built on NVIDIA RTX technology, CloudXR is an advanced streaming technology that delivers VR and AR across 5G and Wi-Fi networks.
The NVIDIA CloudXR 3.0 release provides bidirectional audio support to enhance collaboration in immersive environments.
Previously, XR users had limited freedom of movement because they were tethered by a cable to a workstation, which made it difficult to collaborate with stakeholders in other locations. CloudXR now makes it possible to stream high-quality XR experiences to untethered headsets, so users can be virtually anywhere.
NVIDIA CloudXR provides a powerful edge computing platform for extended reality. Built on NVIDIA RTX technology, CloudXR is an advanced streaming technology that delivers VR and AR across 5G and Wi-Fi networks.
With CloudXR users no longer need to be physically tethered to a high-performance computer to experience rich, immersive environments. Using CloudXR means design changes can be made on the spot using a tablet or mobile device.
The latest CloudXR release adds bidirectional audio support to streamed XR, enabling users to improve collaboration within any immersive experience. Bidirectional audio delivers real-time communication capability for any XR environment, including immersive automotive design reviews, collaborative AEC approvals and interactive training. Even from a mobile device, users can discuss design options with colleagues while immersed in virtual or augmented environments.
Key features of CloudXR 3.0 include:
Bidirectional audio for collaboration is now available for sending client input audio to server
iOS client improvements including world origin updates
Asynchronous connection support, so clients are kept responsive during connection establishment
In the Wave VR client, improving color and gamma handling
Updated Windows SDK from 8.1 to 10
Multiple API changes — see CloudXR SDK API for additional details
Various bug fixes and optimizations
Autodesk and Accenture are two of the early testers of CloudXR 3.0, experiencing the latest bidirectional audio features for their design and training workflows.
“NVIDIA CloudXR is opening new ways for VRED to bring even more people together in collaborative experiences by reducing dependency on hardware and location,” said Lukas Faeth, senior product manager of Automotive Visualization at Autodesk. “We can’t wait to see where this technology will take automotive design and review workflows for Autodesk VRED users.”
“We tested CloudXR 3.0 and experienced great performance with complex training apps originally built of tethered XR. The addition of bidirectional audio for collaboration will take cloud rendered collaborative XR experiences to the next level,” said Nicola Rosa, extended reality lead at Accenture in Europe. “With the latest CloudXR 3.0 release, we can finally start designing XR apps for the cloud without any limitation.”
Learn more about CloudXR 3.0 by watching Ronnie Vasishta, senior vice president of telecommunications at NVIDIA, present his special address at Mobile World Congress. His talk, “AI-on-5G: Bringing Connected Intelligence to Every Industry,” will be live on July 1 at 8:00 a.m. CET (June 30 at 11:00 p.m. PT).
Vasishta will share how the fusion of enterprise AI-on-5G at the edge opens the doors to multi-trillion dollar industry transformation and new capabilities for smart cities, security systems, retail intelligence, industrial automation and optimization of network capacity utilization.
The NVIDIA UFM Cyber-AI platform helps to minimize downtime in InfiniBand data centers by harnessing AI-powered analytics to detect security threats and operational issues, as well as predict network failures. This post outlines the advanced features that system administrators can use to quickly detect and respond to potential security threats and upcoming failures, saving costs and ensuring consistent customer service.
Today’s data centers host many users and a wide variety of applications. They have even become the key element of competitive advantage for research, technology, and global industries. With the increased complexity of scientific computing, data center operational costs also continue to rise. In addition to the operational disruption of security threats, keeping a data center intact and running smoothly is critical.
What’s more, malicious users may exploit data center access to misuse compute resources by running prohibited applications resulting in unexpected downtimes and higher operating costs. More than ever, data center management tools that quickly identify issues while improving efficiency are a priority for today’s IT managers and the developers who support them.
NVIDIA may be best known for stunning graphics capabilities and unmatched GPU compute performance used in nearly every area of research. However, for many years, it has also been the leader in secure and scalable data center technologies, including flexible libraries and tools to maximize world-class infrastructures.
NVIDIA recognizes that providing a full-stack solution for what might be the most critical component of today’s research and business includes more than world-class server platforms, GPUs, and the broadest software portfolio deployed throughout the data center. NVIDIA also knows that security and manageability are key pillars on which datacenter infrastructure is built.
NVIDIA UFM Cyber-AI revolutionizes the InfiniBand data center
The NVIDIA Unified Fabric Manager (UFM) Cyber-AI platform offers enhanced and real-time network telemetry, combined with AI-powered intelligence and advanced analytics. It enables IT managers to discover operational anomalies and even predict network failures. This improves both security and data center uptime while decreasing overall operating expenses.
The unique advantage of UFM Cyber-AI is its ability to capture rich telemetry information and employ AI techniques to identify hidden correlations between events. This enables it to detect abnormal system and application behavior, and even identify performance degradations before they lead to component or system failure. UFM Cyber-AI can even take corrective actionsin real time. The platform learns the typical operational modes of the data center and detects abnormal use based on network telemetry data, including traffic patterns, temperature, and more.
Fundamentals of UFM Cyber-AI
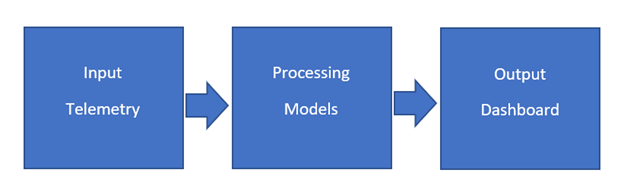
UFM Cyber-AI contains three different layers, as shown in Figure 1.
Figure 1. UFM Cyber-AI layers
Input telemetry: Collects information and learns from the network in various ways:
Telemetry of all elements in the network
Network topology (connectivity and resource allocation for tenants or applications)
Features and capabilities of network equipment
Processing models: Contains several models, such as an extraction, transformation, and loading (ETL) processing engine for data preparation. It also contains aggregation, data storage, and analytical models for comparison. UFM Cyber-AI uses machine learning (ML) techniques and AI models for anomaly detection and prediction to learn the lifecycle patterns of data center network components (cable, switch, port, InfiniBand adapter).
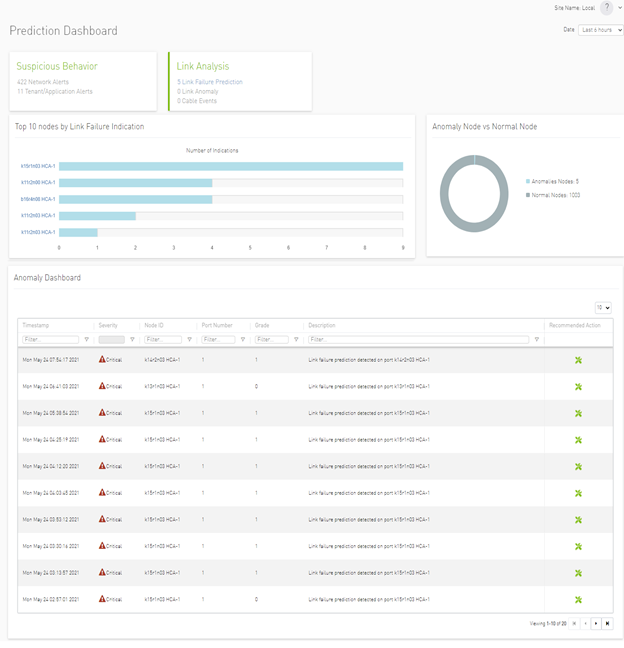
Output dashboard: A visualization layer that exposes a central dashboard for network administrators and cloud orchestrators to see alerts and recommendations for improving network utilization and efficiency, and solving network health issues. The dashboard offers two main categories: Suspicious Behavior and Link Analysis, each including sections for alerts and predictions (Figure 2).
Figure 2. UFM Cyber-AI Prediction dashboard
A feature-rich, intuitive, and customizable fabric manager
UFM Cyber-AI also supports customizable network alerts or viewing triggered anomalies over time and in different time dimensions. By using aggregated network statistics based on hour or day-of-the-week parameters, you can set thresholds and configure notifications based on measurements that might deviate from typical operational use. For example, you could use predefined thresholds to identify problematic cables.
Built-in analytics compares current telemetry information against time-based aggregated information to detect any suspicious increase or decrease in use or traffic patterns and immediately notify the system administrator. UFM Cyber-AI also provides data center tenant or application alerts through link or port telemetry information to identify low-level partition key (PKEY) associated statistics along with their associated nodes.
Only UFM Cyber-AI offers features like link failure prediction, whichsupports predictive maintenance. By detecting performance degradation cases in the early stages, UFM Cyber-AI can predict potential link or port failures. This enables administrators to perform maintenance and eliminate data center downtime.
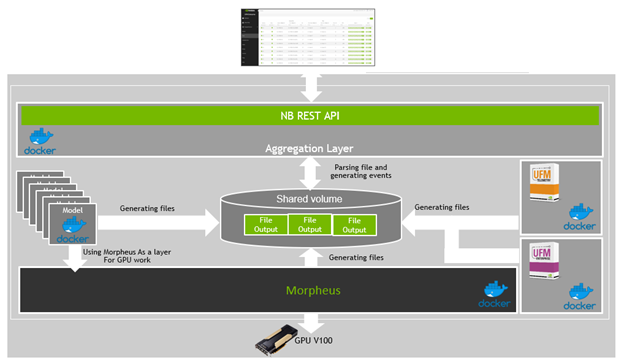
Future enhancements with NVIDIA Morpheus
Bringing the most robust fabric management solution for InfiniBand requires constant innovation to keep pace with the complexities of managing today’s complex data center. We plan to integrate NVIDIA Morpheus with UFM Cyber-AI (Figure 3), bringing more telemetry information from other data center elements, such as server or rack-based component-based telemetry or DPU, GPU, and application counters.
We could even provide an additional layer that can interface directly with other APIs such as Kafka, an open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, and data integration. You could use that integration for specific detection of developer-defined operational system exceptions, such as crypto-mining detection on a system dedicated for life-science research.
Figure 3. Integration example of UFM Cyber-AI with the Morpheus framework
Morpheus is an open AI application framework that provides cybersecurity developers with a highly optimized AI pipeline and pretrained AI capabilities. These capabilities enable you to inspect all network traffic instantaneously across your data center fabric. Morpheus brings a new level of security to data centers by providing the following:
Dynamic protection
Real-time telemetry
Adaptive policies
Cyber defenses for detecting and remediating cybersecurity threats
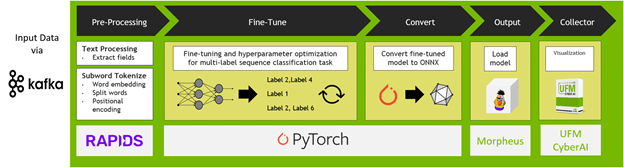
Figure 4. Example for UFM Cyber-AI as a flexible and extendable platform
As Morpheus integrates into the UFM Cyber-AI appliance, we can offer the best and most complete solution that is also flexible and extendable for mission-critical data centers and supporting developers. With customizable anomaly detection and interfaces to other standardized APIs, UFM Cyber-AI is a flexible asset for any data center or cloud-native infrastructure supporting multitenancy.
I have GTX 1080 and RTX 3070Ti and for reason they show about the same performance on my model, about 60 seconds per epoch of 3k samples.
The model is 27 layers (as per summary), mostly conv1d, has about 270k parameters and input sample is about 450 values.
I wonder why is this so? GTX is way older chip and RTX is supposed to have faster tensor cores, 1080 has 2560 cores vs 6144 cores and faster memory on 3070Ti. It’s supposed to be at least 2 times faster before cores efficiency.
Is this some kind of hardware limiter like the one against mining?
I am using TF 2.5 and latest cudnn/cuda 11/studio drivers.
Also I wonder if 3080Ti/3090 would show similar performance since they are not A models.
So I have been working on a project, the model was trained on the screenshots that were taken on a laptop. When Images that are captured on a phone are fed to the model for testing the predictions are wrong, but when the same images are taken as screenshot[on a laptop] and fed to the model the predictions are correct. What is the issue here?

 High-performance computing (HPC) and AI have driven supercomputers into wide commercial use as the primary data processing engines enabling research, scientific discoveries, and product development. These systems can carry complex simulations and unlock the new era of AI, where software writes software. Supercomputing leadership means scientific and innovation leadership, which explains the investments made by …
High-performance computing (HPC) and AI have driven supercomputers into wide commercial use as the primary data processing engines enabling research, scientific discoveries, and product development. These systems can carry complex simulations and unlock the new era of AI, where software writes software. Supercomputing leadership means scientific and innovation leadership, which explains the investments made by … 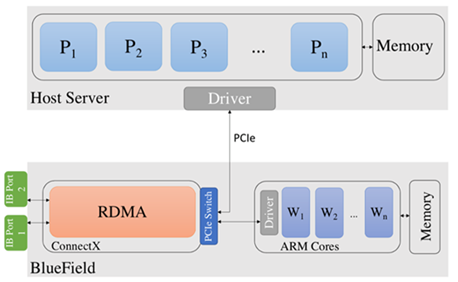
 NVIDIA CloudXR provides a powerful edge computing platform for extended reality. Built on NVIDIA RTX technology, CloudXR is an advanced streaming technology that delivers VR and AR across 5G and Wi-Fi networks.
NVIDIA CloudXR provides a powerful edge computing platform for extended reality. Built on NVIDIA RTX technology, CloudXR is an advanced streaming technology that delivers VR and AR across 5G and Wi-Fi networks.  VR client, improving color and gamma handling
VR client, improving color and gamma handling
 The NVIDIA UFM Cyber-AI platform helps to minimize downtime in InfiniBand data centers by harnessing AI-powered analytics to detect security threats and operational issues, as well as predict network failures. This post outlines the advanced features that system administrators can use to quickly detect and respond to potential security threats and upcoming failures, saving costs and ensuring consistent customer service.
The NVIDIA UFM Cyber-AI platform helps to minimize downtime in InfiniBand data centers by harnessing AI-powered analytics to detect security threats and operational issues, as well as predict network failures. This post outlines the advanced features that system administrators can use to quickly detect and respond to potential security threats and upcoming failures, saving costs and ensuring consistent customer service.