Posted by Xuan Yang, Software Engineer, Google Research
For the 285 million people around the world living with blindness or low vision, exercising independently can be challenging. Earlier this year, we announced Project Guideline, an early-stage research project, developed in partnership with Guiding Eyes for the Blind, that uses machine learning to guide runners through a variety of environments that have been marked with a painted line. Using only a phone running Guideline technology and a pair of headphones, Guiding Eyes for the Blind CEO Thomas Panek was able to run independently for the first time in decades and complete an unassisted 5K in New York City’s Central Park.
Safely and reliably guiding a blind runner in unpredictable environments requires addressing a number of challenges. Here, we will walk through the technology behind Guideline and the process by which we were able to create an on-device machine learning model that could guide Thomas on an independent outdoor run. The project is still very much under development, but we’re hopeful it can help explore how on-device technology delivered by a mobile phone can provide reliable, enhanced mobility and orientation experiences for those who are blind or low vision.
 |
| Thomas Panek using Guideline technology to run independently outdoors. |
Project Guideline
The Guideline system consists of a mobile device worn around the user’s waist with a custom belt and harness, a guideline on the running path marked with paint or tape, and bone conduction headphones. Core to the Guideline technology is an on-device segmentation model that takes frames from a mobile device’s camera as input and classifies every pixel in the frame into two classes, “guideline” and “not guideline”. This simple confidence mask, applied to every frame, allows the Guideline app to predict where runners are with respect to a line on the path, without using location data. Based on this prediction and the proceeding smoothing/filtering function, the app sends audio signals to the runners to help them orient and stay on the line, or audio alerts to tell runners to stop if they veer too far away.
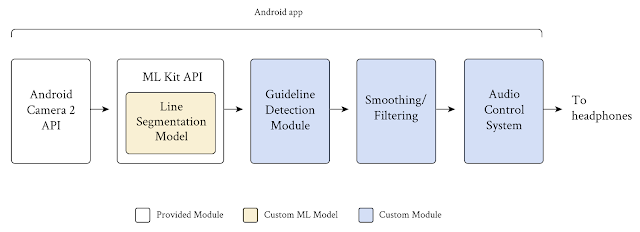 |
| Project Guideline uses Android’s built-in Camera 2 and MLKit APIs and adds custom modules to segment the guideline, detect its position and orientation, filter false signals, and send a stereo audio signal to the user in real-time. |
We faced a number of important challenges in building the preliminary Guideline system:
- System accuracy: Mobility for the blind and low vision community is a challenge in which user safety is of paramount importance. It demands a machine learning model that is capable of generating accurate and generalized segmentation results to ensure the safety of the runner in different locations and under various environmental conditions.
- System performance: In addition to addressing user safety, the system needs to be performative, efficient, and reliable. It must process at least 15 frames per second (FPS) in order to provide real-time feedback for the runner. It must also be able to run for at least 3 hours without draining the phone battery, and must work offline, without the need for internet connection should the walking/running path be in an area without data service.
- Lack of in-domain data: In order to train the segmentation model, we needed a large volume of video consisting of roads and running paths that have a yellow line on them. To generalize the model, data variety is equally as critical as data quantity, requiring video frames taken at different times of day, with different lighting conditions, under different weather conditions, at different locations, etc.
Below, we introduce solutions for each of these challenges.
Network Architecture
To meet the latency and power requirements, we built the line segmentation model on the DeepLabv3 framework, utilizing MobilenetV3-Small as the backbone, while simplifying the outputs to two classes – guideline and background.
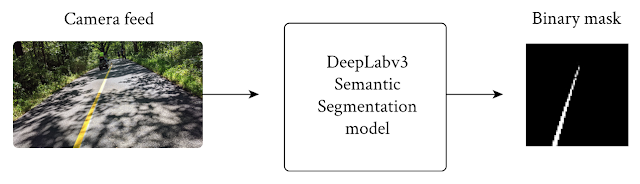 |
| The model takes an RGB frame and generates an output grayscale mask, representing the confidence of each pixel’s prediction. |
To increase throughput speed, we downsize the camera feed from 1920 x 1080 pixels to 513 x 513 pixels as input to the DeepLab segmentation model. To further speed-up the DeepLab model for use on mobile devices, we skipped the last up-sample layer, and directly output the 65 x 65 pixel predicted masks. These 65 x 65 pixel predicted masks are provided as input to the post processing. By minimizing the input resolution in both stages, we’re able to improve the runtime of the segmentation model and speed up post-processing.
Data Collection
To train the model, we required a large set of training images in the target domain that exhibited a variety of path conditions. Not surprisingly, the publicly available datasets were for autonomous driving use cases, with roof mounted cameras and cars driving between the lines, and were not in the target domain. We found that training models on these datasets delivered unsatisfying results due to the large domain gap. Instead, the Guideline model needed data collected with cameras worn around a person’s waist, running on top of the line, without the adversarial objects found on highways and crowded city streets.
 |
| The large domain gap between autonomous driving datasets and the target domain. Images on the left courtesy of the Berkeley DeepDrive dataset. |
With preexisting open-source datasets proving unhelpful for our use case, we created our own training dataset composed of the following:
- Hand-collected data: Team members temporarily placed guidelines on paved pathways using duct tape in bright colors and recorded themselves running on and around the lines at different times of the day and in different weather conditions.
- Synthetic data: The data capture efforts were complicated and severely limited due to COVID-19 restrictions. This led us to build a custom rendering pipeline to synthesize tens of thousands of images, varying the environment, weather, lighting, shadows, and adversarial objects. When the model struggled with certain conditions in real-world testing, we were able to generate specific synthetic datasets to address the situation. For example, the model originally struggled with segmenting the guideline amidst piles of fallen autumn leaves. With additional synthetic training data, we were able to correct for that in subsequent model releases.
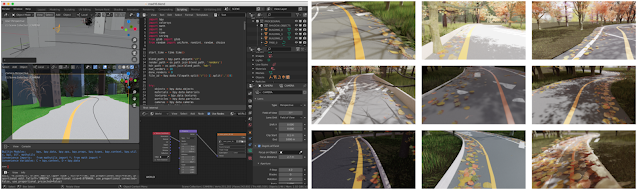 |
| Rendering pipeline generates synthetic images to capture a broad spectrum of environments. |
We also created a small regression dataset, which consisted of annotated samples of the most frequently seen scenarios combined with the most challenging scenarios, including tree and human shadows, fallen leaves, adversarial road markings, sunlight reflecting off the guideline, sharp turns, steep slopes, etc. We used this dataset to compare new models to previous ones and to make sure that an overall improvement in accuracy of the new model did not hide a reduction in accuracy in particularly important or challenging scenarios.
Training Procedure
We designed a three-stage training procedure and used transfer learning to overcome the limited in-domain training dataset problem. We started with a model that was pre-trained on Cityscape, and then trained the model using the synthetic images, as this dataset is larger but of lower quality. Finally, we fine-tuned the model using the limited in-domain data we collected.
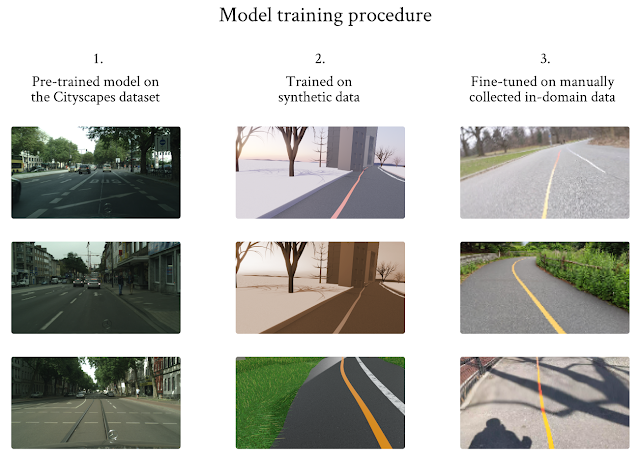 |
| Three-stage training procedure to overcome the limited data issue. Images in the left column courtesy of Cityscapes. |
Early in development, it became clear that the segmentation model’s performance suffered at the top of the image frame. As the guidelines travel further away from the camera’s point of view at the top of the frame, the lines themselves start to vanish. This causes the predicted masks to be less accurate at the top parts of the frame. To address this problem, we computed a loss value that was based on the top k pixel rows in every frame. We used this value to select those frames that included the vanishing guidelines with which the model struggled, and trained the model repeatedly on those frames. This process proved to be very helpful not only in addressing the vanishing line problem, but also for solving other problems we encountered, such as blurry frames, curved lines and line occlusion by adversarial objects.
 |
| The segmentation model’s accuracy and robustness continuously improved even in challenging cases. |
System Performance
Together with Tensorflow Lite and ML Kit, the end-to-end system runs remarkably fast on Pixel devices, achieving 29+ FPS on Pixel 4 XL and 20+ FPS on Pixel 5. We deployed the segmentation model entirely on DSP, running at 6 ms on Pixel 4 XL and 12 ms on Pixel 5 with high accuracy. The end-to-end system achieves 99.5% frame success rate, 93% mIoU on our evaluation dataset, and passes our regression test. These model performance metrics are incredibly important and enable the system to provide real-time feedback to the user.
What’s Next
We’re still at the beginning of our exploration, but we’re excited about our progress and what’s to come. We’re starting to collaborate with additional leading non-profit organizations that serve the blind and low vision communities to put more Guidelines in parks, schools, and public places. By painting more lines, getting direct feedback from users, and collecting more data under a wider variety of conditions, we hope to further generalize our segmentation model and improve the existing feature-set. At the same time, we are investigating new research and techniques, as well as new features and capabilities that would improve the overall system robustness and reliability.
To learn more about the project and how it came to be, read Thomas Panek’s story. If you want to help us put more Guidelines in the world, please visit goo.gle/ProjectGuideline.
Acknowledgements
Project Guideline is a collaboration across Google Research, Google Creative Lab, and the Accessibility Team. We especially would like to thank our team members: Mikhail Sirotenko, Sagar Waghmare, Lucian Lonita, Tomer Meron, Hartwig Adam, Ryan Burke, Dror Ayalon, Amit Pitaru, Matt Hall, John Watkinson, Phil Bayer, John Mernacaj, Cliff Lungaretti, Dorian Douglass, Kyndra LoCoco. We also thank Fangting Xia, Jack Sim and our other colleagues and friends from the Mobile Vision team and Guiding Eyes for the Blind.


 Researchers from the Netherlands’ University of Groningen have used AI to reveal that the Great Isaiah Scroll — the only entirely preserved volume from the original Dead Sea Scrolls — was likely copied by two scribes who wrote in a similar style.
Researchers from the Netherlands’ University of Groningen have used AI to reveal that the Great Isaiah Scroll — the only entirely preserved volume from the original Dead Sea Scrolls — was likely copied by two scribes who wrote in a similar style. 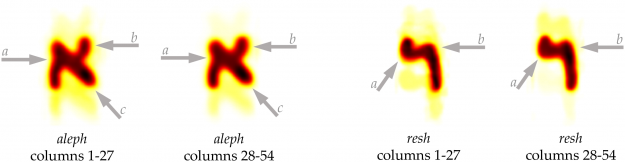



 Game developers around the world attended GTC to experience how the latest NVIDIA technologies are creating realistic graphics and interactive experiences in gaming. Catch up on the top sessions available on NVIDIA On-Demand now.
Game developers around the world attended GTC to experience how the latest NVIDIA technologies are creating realistic graphics and interactive experiences in gaming. Catch up on the top sessions available on NVIDIA On-Demand now. 













