IDC analysts Brad Casemore and Harsh Singh interviewed IT organizations with real world experience deploying and managing Cumulus Linux and NVIDIA Spectrum switches in mission critical data centers over a significant time period.
NVIDIA recently commissioned IDC to conduct research into the business value and technical benefits of the NVIDIA Ethernet switch solution. IDC analysts Brad Casemore and Harsh Singh interviewed IT organizations with real world experience deploying and managing Cumulus Linux and NVIDIA Spectrum switches in mission critical data centers over a significant time period. The research included interviews with organizations that were using the combined solution set and had first-hand knowledge about the costs and benefits of this solution.
During the interviews, companies were asked a variety of quantitative and qualitative questions about NVIDIA’s impact on their IT and network operations. The results highlighted several key benefits that NVIDIA customers are realizing, including:
Higher efficiency: Helping network operations and management staff be more efficient while allowing them to spend more time on innovation and business-related projects
Better performance and security: Improving overall network performance including increasing the efficiency of network security and reducing application latency
Improved cost/performance: Leveraging improved network and application performance while lowering costs to bolster business operations and results
Increased reliability and productivity: Reducing the occurrences and rate of unplanned downtime, thereby lowering business risk and increasing productivity
“The biggest benefit is operational efficiencies — it’s easier to deploy and manage from an IT standpoint. Any time we need to make changes to the infrastructure, for whatever reason, we can do it more simply and quicker. And the raw IT budget has been reduced,” NVIDIA Ethernet Switching Solutions Customer
In this paper, IDC concluded that a modern data center can be a significant contributor to business value when the datacenter network combines all the traditional attributes of switch hardware — such as scalability, reliability, performance, and low latency — with a commensurate degree of software-based network automation, programmability, flexibility, and actionable analytics and insights.
In the IDC Business Value White Paper, IDC has documented the business value of NVIDIA Spectrum Ethernet Switches in conjunction with Cumulus Linux through the ease of overall network management and operations. Interviewees also reported they were able to support their business with a more cost-effective and better performing network by reducing the costs of the network itself but still providing enough bandwidth for their organization’s business users.
Join guests IDC analysts, Brad Casemore and Harsh Singh on May 27th at 10 am PT for a full readout on the details of their findings in a special webinar. Please register here.
All webinar attendees will get exclusive early access to the full IDC Business Value White Paper*, entitled “The Business Value of NVIDIA Ethernet Switch Solutions for Managing and Optimizing Network Performance”. You’ll also receive the IDC Executive Overview and IDC Snapshot/Infographic.
*IDC Business Value Whitepaper, Sponsored by NVIDIA, The Business Value of NVIDIA Ethernet Switch Solutions for Managing and Optimizing Network Performance, IDC Doc. #US47556921, April 2021
Posted by Siamak Shakeri, Staff Software Engineer and Oshin Agarwal, Research Intern, Google Research
Large pre-trained natural language processing (NLP) models, such as BERT, RoBERTa, GPT-3, T5 and REALM, leverage natural language corpora that are derived from the Web and fine-tuned on task specific data, and have made significant advances in various NLP tasks. However, natural language text alone represents a limited coverage of knowledge, and facts may be contained in wordy sentences in many different ways. Furthermore, existence of non-factual information and toxic content in text can eventually cause biases in the resulting models.
Alternate sources of information are knowledge graphs (KGs), which consist of structured data. KGs are factual in nature because the information is usually extracted from more trusted sources, and post-processing filters and human editors ensure inappropriate and incorrect content are removed. Therefore, models that can incorporate them carry the advantages of improved factual accuracy and reduced toxicity. However, their different structural format makes it difficult to integrate them with the existing pre-training corpora in language models.
In “Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training” (KELM), accepted at NAACL 2021, we explore converting KGs to synthetic natural language sentences to augment existing pre-training corpora, enabling their integration into the pre-training of language models without architectural changes. To that end, we leverage the publicly available English Wikidata KG and convert it into natural language text in order to create a synthetic corpus. We then augment REALM, a retrieval-based language model, with the synthetic corpus as a method of integrating natural language corpora and KGs in pre-training. We have released this corpus publicly for the broader research community.
Converting KG to Natural Language Text KGs consist of factual information represented explicitly in a structured format, generally in the form of [subject entity, relation, object entity] triples, e.g., [10×10 photobooks, inception, 2012]. A group of related triples is called an entity subgraph. An example of an entity subgraph that builds on the previous example of a triple is { [10×10 photobooks, instance of, Nonprofit Organization], [10×10 photobooks, inception, 2012] }, which is illustrated in the figure below. A KG can be viewed as interconnected entity subgraphs.
Converting subgraphs into natural language text is a standard task in NLP known as data-to-text generation. Although there have been significant advances on data-to-text-generation on benchmark datasets such as WebNLG, converting an entire KG into natural text has additional challenges. The entities and relations in large KGs are more vast and diverse than small benchmark datasets. Moreover, benchmark datasets consist of predefined subgraphs that can form fluent meaningful sentences. With an entire KG, such a segmentation into entity subgraphs needs to be created as well.
An example illustration of how the pipeline converts an entity subgraph (in bubbles) into synthetic natural sentences (far right).
In order to convert the Wikidata KG into synthetic natural sentences, we developed a verbalization pipeline named “Text from KG Generator” (TEKGEN), which is made up of the following components: a large training corpus of heuristically aligned Wikipedia text and Wikidata KG triples, a text-to-text generator (T5) to convert the KG triples to text, an entity subgraph creator for generating groups of triples to be verbalized together, and finally, a post-processing filter to remove low quality outputs. The result is a corpus containing the entire Wikidata KG as natural text, which we call the Knowledge-Enhanced Language Model (KELM) corpus. It consists of ~18M sentences spanning ~45M triples and ~1500 relations.
Converting a KG to natural language, which is then used for language model augmentation
Integrating Knowledge Graph and Natural Text for Language Model Pre-training Our evaluation shows that KG verbalization is an effective method of integrating KGs with natural language text. We demonstrate this by augmenting the retrieval corpus of REALM, which includes only Wikipedia text.
To assess the effectiveness of verbalization, we augment the REALM retrieval corpus with the KELM corpus (i.e., “verbalized triples”) and compare its performance against augmentation with concatenated triples without verbalization. We measure the accuracy with each data augmentation technique on two popular open-domain question answering datasets: Natural Questions and Web Questions.
Augmenting REALM with even the concatenated triples improves accuracy, potentially adding information not expressed in text explicitly or at all. However, augmentation with verbalized triples allows for a smoother integration of the KG with the natural language text corpus, as demonstrated by the higher accuracy. We also observed the same trend on a knowledge probe called LAMA that queries the model using fill-in-the-blank questions.
Conclusion With KELM, we provide a publicly-available corpus of a KG as natural text. We show that KG verbalization can be used to integrate KGs with natural text corpora to overcome their structural differences. This has real-world applications for knowledge-intensive tasks, such as question answering, where providing factual knowledge is essential. Moreover, such corpora can be applied in pre-training of large language models, and can potentially reduce toxicity and improve factuality. We hope that this work encourages further advances in integrating structured knowledge sources into pre-training of large language models.
Acknowledgements This work has been a collaborative effort involving Oshin Agarwal, Heming Ge, Siamak Shakeri and Rami Al-Rfou. We thank William Woods, Jonni Kanerva, Tania Rojas-Esponda, Jianmo Ni, Aaron Cohen and Itai Rolnick for rating a sample of the synthetic corpus to evaluate its quality. We also thank Kelvin Guu for his valuable feedback on the paper.
GFN Thursday returns with a brand new adventure, exploring the unknown in Phantom Abyss, announced just moments ago by Devolver Digital and Team WIBY. The game launches on PC this summer, and when it does, it’ll be streaming instantly to GeForce NOW members. No GFN Thursday would be complete without new games. And this week Read article >
Learn how to compact the acceleration structure in DXR and what to know before you start implementing.
In ray tracing, more geometries can reside in the GPU memory than with the rasterization approach because rays may hit the geometries out of the view frustum. You can let the GPU compact acceleration structures to save memory usage. For some games, compaction reduces the memory footprint for a bottom-level acceleration structure (BLAS) by at least 50%. BLASes usually take more GPU memory than top-level acceleration structures (TLAS), but this post is also valid for TLAS.
In this post, I discuss how to compact the acceleration structure in DXR and what to know before you start implementing. Do you have your acceleration structure already working but you want to keep the video memory usage as small as possible? Read Managing Memory for Acceleration Structures in DirectX Raytracing first and then come back.
I assume that you already have your acceleration structures suballocated by larger resources and want to save more video memory by compacting them. I use DXR API in this post but it’s similar in Vulkan too.
How does compaction work?
BLAS compaction is not as trivial as adding a new flag to the acceleration structure build input. For your implementation, you can consider this process as a kind of state machine that runs over a few frames (Figure 1). The compaction memory size isn’t known until after the initial build is completed. Wait until the compaction process is completed on the GPU. Here is the brief process to compact BLAS.
Figure 1. Compaction workflow.
Add the compaction flag when building the acceleration structure. For BuildRaytracingAccelerationStructure, you must specify the _ALLOW_COMPACTION build flag for the source BLAS from which to compact.
Read the compaction sizes:
Call EmitRaytracingAccelerationStructurePostbuildInfo with the compaction size buffer, _POSTBUILD_INFO_COMPACTED_SIZE flag and the source BLASes that are built with the _ALLOW_COMPACTION flag. This computes the compaction buffer size on the GPU, which is then used to allocate the compaction buffer. The compaction size buffer is a buffer that holds the size values when it’s ready.
You can pass the post build info structure in your source BuildRaytracingAccelerationStructure instead of calling EmitRaytracingAccelerationStructurePostbuildInfo.
The API doesn’t directly return the size that you want to use, as it’s calculated from the GPU.
Use appropriate synchronization (for example, fence/signal) to make sure that you’re OK to read back the compaction size buffer.
You can use CopyResource and Map to read back the content of the compaction size buffer from GPU to CPU. There could be a couple of frames of delay for reading the size if you execute the command buffer and submit the queue one time per frame.
If the compaction size buffer isn’t ready to be read, then you can keep using the original BLAS for the rest of your rendering pipeline. In the next frames, you keep checking the readiness and continue the following steps.
Create a new target BLAS resource with the known compaction size. Now you know the size and you can make your target BLAS resource ready.
Compact it with Copy:
Copy from the source BLAS to the target BLAS using CopyRayTracingAccelerationStructure with the _COPY_MODE_COMPACT flag. Your target BLAS has the compacted content when it’s finished in GPU.
Make sure that your source BLAS has been built in the GPU already before running CopyRayTracingAccelerationStructure.
Wait for compaction to be finished using fence/signal.
You can also run compactions in parallel with other compactions and with other builds and refits.
(Optional) Build a TLAS that points to the new compacted BLAS.
Use it with DispatchRays. You are now OK to call DispatchRays or use inline ray tracing that uses the compacted BLAS.
Tips
Here are a few tips to help you deal with crashes, corruption, and performance issues.
Compaction count
You don’t need to compact all the BLASes in one frame because you can still call DispatchRays with the source BLASes while they’re being compacted. Limit your per-frame BLAS compaction count based on your frame budget.
Animating BLAS
It’s possible to compact animating BLASes, like for characters or particles. However, you pay the compaction cost and the delay of updates. I don’t recommend using compaction on particles and exploding meshes.
Your compacted BLAS could be outdated when it’s ready. In this case, you can refit on the compacted BLAS, if you can.
Don’t add _ALLOW_COMPACTION flag to BLASes that won’t be compacted because adding this flag isn’t free even though the cost is small.
Crashes or corruptions
If you have crashes or corruptions after your compaction-related changes, then try replacing the _COPY_MODE_COMPACT mode in your CopyRaytracingAccelerationStructure with _COPY_MODE_CLONE instead.
Specify the initial acceleration structure size instead of the compacted size. It’ll make sure that your corrupted data is not from the result of the actual compaction if you still have the same issues. It could be from using the wrong/invalid resources or being out of sync due to missing barriers or fence waiting.
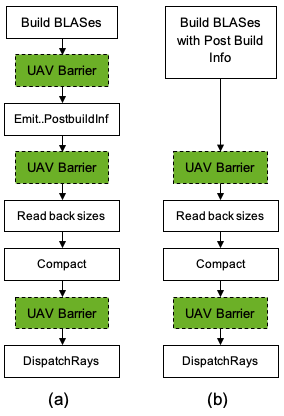
Null UAV barriers
Use null UAV barriers to find why GPU crash issues happen. Keep in mind that using null UAV barriers is suboptimal and try to use more specific options. If you do use null UAV barriers, add them as follows:
Before the Emit..PostbuildInfo call
Before reading back the sizes
After calling CopyRaytracingAccelerationStructure for compaction
A null UAV barrier is just the easiest way to make sure that you got all the resources covered, like if you accidentally use the same scratch resource for multiple BLAS builds. The null barrier should prevent those from clobbering each other. Or if you have a preceding skinning shader, you’ll be sure that the vertex positions are updated.
Figure 2 shows two usage patterns that explain where to add barriers. Those barriers are all necessary but you can try replacing them with null barriers to make sure that you didn’t miss anything.
Figure 2. Two barrier usage patterns: (a) is for BLASes built without post build info, (b) is with post build info.
Destroy the source BLAS
Do not destroy the source BLAS while it’s still being used. GPU memory savings can be achieved after you delete the source BLAS. Until then, you are keeping two versions of BLASes in the GPU. Destroy the resource as soon as possible after compacting it. Keep in mind that you can’t destroy them even after CopyAccelerationStructure is completed if you still have previous DispatchRays that uses the source BLAS in GPU.
Max compaction
If you don’t use the PREFER_FAST_BUILD or ALLOW_UPDATE flags, then you should get max compaction.
PREFER_FAST_BUILD uses its own compaction method and results can differ from ALLOW_COMPACTION.
ALLOW_UPDATE must leave room for updated triangles.
Conclusion
It might be more complicated than you thought, but it’s worth doing. I hope you are pleased with the compression rate and the total savings of the GPU memory. I recommend adding debug features that visualize the memory savings and the compression rate from your app to track how it goes per content.
In this post, we showcase our support for open-source robotics frameworks including ROS and ROS 2 on NVIDIA Jetson developer kits.
NVIDIA Jetson developer kits serve as a go-to platform for roboticists because of its ease of use, system support, and its comprehensive support for accelerating AI workloads. In this post, we showcase our support for open-source robotics frameworks including ROS and ROS 2 on NVIDIA Jetson developer kits.
Figure 1. ROS and ROS 2 with AI acceleration on NVIDIA Jetson platform.
This post includes the following helpful resources:
We offer different Docker images for ROS and ROS 2 with machine learning libraries. We also provide Dockerfiles for you to build your own Docker images according to your custom requirements.
ROS and ROS 2 Docker images
We provide support for ROS 2 Foxy Fitzroy, ROS 2 Eloquent Elusor, and ROS Noetic with AI frameworks such as PyTorch, NVIDIA TensorRT, and the DeepStream SDK. We include machine learning (ML) libraries including scikit-learn, numpy, and pillow. The containers are packaged with ROS 2 AI packages accelerated with TensorRT.
ROS 2 Foxy, ROS 2 Eloquent, and ROS Noetic with PyTorch and TensorRT Docker image:
To enable you to easily run different versions of ROS 2 on Jetson, we released various Dockerfiles and build scripts for ROS 2 Eloquent, ROS 2 Foxy, ROS Melodic, and ROS Noetic. These containers provide an automated and reliable way to install ROS and ROS 2 on Jetson and build your own ROS-based applications.
Because Eloquent and Melodic already provide prebuilt packages for Ubuntu 18.04, the Dockerfiles, install these versions of ROS into the containers. In contrast, Foxy and Noetic are built from the source inside the container, as those versions only come prebuilt for Ubuntu 20.04. With the containers, using these versions of ROS and ROS 2 is the same, regardless of the underlying OS distribution.
To build the containers, clone the repo on your Jetson device running NVIDIA JetPack 4.4 or newer, and run the ROS build script:
$ git clone https://github.com/dusty-nv/jetson-containers
$ cd jetson-containers
$ ./scripts/docker_build_ros.sh all # build all: melodic, noetic, eloquent, foxy
$ ./scripts/docker_build_ros.sh melodic # build only melodic
$ ./scripts/docker_build_ros.sh noetic # build only noetic
$ ./scripts/docker_build_ros.sh eloquent # build only eloquent
$ ./scripts/docker_build_ros.sh foxy # build only foxy
We’ve put together bundled packages with all the materials needed to run various GPU-accelerated AI applications with ROS and ROS 2 packages. There are applications for object detection, human pose estimation, gesture classification, semantics segmentation, and NVApril Tags.
The repository provides four different packages for classification and object detection using PyTorch and TensorRT. This repository serves as a starting point for AI integration with ROS 2. The main features of the packages are as follows:
For classification, select from various ImageNet pretrained models, including Resnet18, AlexNet, SqueezeNet, and Resnet50.
For detection, MobileNetV1-based SSD is currently supported, trained on the COCO dataset.
The TensorRT packages provide a significant speedup in carrying out inference relative to the PyTorch models performing inference directly on the GPU.
The inference results are published in the form of vision_msgs.
On running the node, a window is also shown with the inference results visualized.
A Jetson-based Docker image and launch file is provided for ease of use.
This repo contains deep learning inference nodes and camera/video streaming nodes for ROS and ROS 2 with support for Jetson Nano, TX1, TX2, Xavier NX, NVIDIA AGX Xavier, and TensorRT.
The nodes use the image recognition, object detection, and semantic segmentation DNNs from the jetson-inference library and NVIDIA Hello AI World tutorial. Both come with several built-in pretrained networks for classification, detection, and segmentation and the ability to load customized user-trained models.
The camera/video streaming nodes support the following I/O interfaces:
MIPI CSI cameras
V4L2 cameras
RTP / RTSP
Videos and images
Image sequences
OpenGL windows
ROS Melodic and ROS 2 Eloquent are supported. We recommend the latest version of NVIDIA JetPack.
In this repository, we accelerate human-pose estimation using TensorRT. We use the widely adopted NVIDIA-AI-IOT/trt_pose repository. To understand human pose, pretrained models infer 17 body parts based on the categories from the COCO dataset. Here are the key features of the ros2_trt_pose package:
Publishes pose_msgs, such as count of person and person_id. For each person_id, it publishes 17 body parts.
Provides a launch file for easy usage and visualizations on Rviz2:
Image messages
Visual markers: body_joints, body_skeleton
Contains a Jetson-based Docker image for easy install and usage.
This ROS 2 node uses the NVIDIA GPU-accelerated AprilTags library to detect AprilTags in images and publish the poses, IDs, and additional metadata. This has been tested on ROS 2 (Foxy) and should run on x86_64 and aarch64 (Jetson hardware). It is modeled after and comparable to the ROS 2 node for CPU AprilTags detection.
For more information about the NVIDIA Isaac GEM on which this node is based, see April Tags in the NVIDIA Isaac SDK 2020.2 documentation. For more information, see AprilTags Visual Fiducial System.
ROS 2 package for hand pose estimation and gesture classification
The ROS 2 package takes advantage of the recently released NVIDIA-AI-IOT/trt_pose_hand repo: Real-time hand pose estimation and gesture classification using TensorRT. It provides following key features:
Hand pose message with 21 key points
Hand pose detection image message
std_msgs for gesture classification with six classes:
fist
pan
stop
fine
peace
no hand
Visualization markers
Launch file for RViz2
ROS 2 package for text detection and monocular depth estimation
The jetson-stats package is for monitoring and controlling your NVIDIA Jetson [Xavier NX, Nano, NVIDIA AGX Xavier, TX1, or TX2]. In this repository, we provide a ROS 2 package for jetson_stats such that you can monitor different system status in deployment. The ROS package developed by Jetson Champion Raffaello Bonghi, PhD can be found at rbonghi/ros_jetson_stats.
The ros2_jetson_stats package features the following ROS 2 diagnostic messages:
GPU/CPU usage percentage
EMC/SWAP/Memory status (% usage)
Power and temperature of SoC
You can now control the following through the ROS 2 command line:
Fan (mode and speed)
Power model (nvpmodel)
Jetson_clocks
ROS 2 packages for the DeepStream SDK
The DeepStream SDK delivers a complete streaming analytics toolkit to build full AI-based solutions using multisensor processing, video, and image understanding. It offers supportfor popular object detection and segmentation models such as state-of-the-art SSD, YOLO, FasterRCNN, and MaskRCNN.
In this repository, we provide ROS 2 nodes based on the NVIDIA-AI-IOT/deepstream_python_apps repo to perform two inference object detection and attribute classification tasks:
Object detection: Four classes of objects are detected: Vehicle, Person, RoadSign, and TwoWheeler.
Attribute classification: Three types of attributes are classified for objects of class Vehicle: Color, Make, and Type.
We also provide sample ROS 2 subscriber nodes that subscribe to these topics and display results in the vision_msgs format. Each inference task also spawns a visualization window with bounding boxes and labels around detected objects.
This promising work looks at the potential to use the power of robotics and deep learning together. We use FCN-AlexNet, a segmentation network, to perform several real-world applications such as detecting stairs, potholes, or other hazards to robots in unstructured environments.
Many Jetson users choose lidars as their major sensors for localization and perception in autonomous solutions. CUDA-PCL 1.0 includes three CUDA-accelerated PCL libraries:
Here are sample projects to leverage the NVIDIA Jetson platform for both the open-source developer community, such as building an autonomous model-scale car, and enterprises, such as implementing human pose estimation for robot arm solutions. All are enabled by ROS, ROS 2 and NVIDIA Jetson.
ROS 2-based NanoSaur
NanoSaur is an open-source project designed and made by Raffaello Bonghi. It’s a fully 3D printable robot, made to work on your desk, and uses a simple camera with two OLED-like eyes. The size is 10x12x6cm in only 500g. With a simple power-bank, it can wander your desktop autonomously. It’s a little robot for robotics and AI education.
ROS and ROS 2 integration with Comau North America
This package demonstrates using a ROS 2 package to control the e.DO by bridging messages to ROS1, where the e.DO core package resides.
Video 1. Using NVIDIA Jetson and GPU accelerated gesture classification AI package with the Comau e.DO robot arm.
To test the Human Hand Pose Estimation package, the team used a Gazebo simulation of the Comau e.DO from Stefan Profanter’s open source repository. This enabled control of the e.DO in simulation with the help of MoveIt Motion Planning software. A ROS 2 node in the hand pose package publishes the hand pose classification message.
Because MoveIt 1.0 works only with ROS1, a software bridge was used to subscribe to the message from ROS1. Based on the hand pose detected and classified, a message with robot pose data is published to a listener, which sends the movement command to MoveIt. The resulting change in the e.DO robot pose can be seen in Gazebo.
ROS-based Yahboom DOFBOT
DOFBOT is the best partner for AI beginners, programming enthusiasts, and Jetson Nano fans. It is designed based on Jetson Nano and contains six HQ servos, an HD camera, and a multifunction expansion board. The whole body is made of green oxidized aluminum alloy, which is beautiful and durable. Through the ROS robot system, we simplify the motion control of serial bus servo.
With over 1600 sessions on the latest in AI, data center, accelerated computing, healthcare, intelligent networking, game development, and more – there is something for everyone.
With over 1600 sessions on the latest in AI, data center, accelerated computing, healthcare, intelligent networking, game development, and more – there is something for everyone
Lets say for object detection of a video feed, would there be any value in using Google Coral Edge USB TPUs or processing Tensorflow on a Jetson device if the alterantive is something like an Intel NUC 10 i7 ( Core i7-10710U Passmark score: 10.1k) with NVME storage?
SIGGRAPH 2021 is the premier conference and exhibition in computer graphics and interactive techniques. This year, participants can join a series of exciting pre-conference webinars called SIGGRAPH Frontiers Interactions.
Add SIGGRAPH Frontiers to Your Calendar – Courses Begin May 24th
SIGGRAPH 2021 is the premier conference and exhibition in computer graphics and interactive techniques. This year, participants can join a series of exciting pre-conference webinars called SIGGRAPH Frontiers Interactions. Starting on May 24, you can take part in industry-leading discussions around ray tracing, machine learning and neural networks.
These pre-conference webinars are ongoing educational events that will take place through June 18, and feature several NVIDIA guest speakers. Both courses are free. Simply add the events to your calendar of choice here and show up to experience the research deep dive and industry-leading discourse.
Introduction to Ray Tracing Course
The first of seven ray tracing webinars starts on May 25, and features Peter Shirley, author of the popular book, Ray Tracing in One Weekend. This is a great introductory level course to gain a strong understanding of the basic principles of ray tracing. Other interactive lectures feature experts from Disney Animation and NVIDIA.
Machine Learning and Neural Networks Course
The first of seven machine learning and neural network webinars starts on May 24. Several ML and NN experts from Google, Disney, Apple and NVIDIA will be featured. These are intermediate level courses intended to gain a strong understanding of the basic principles of ML and NN, and how it can be applied to your engineering solutions.
Make sure to stay up-to-date with all things SIGGRAPH and register for the virtual event, taking place August 9-13.
For a particle physicist, the world’s biggest questions — how did the universe originate and what’s beyond it — can only be answered with help from the world’s smallest building blocks. James Kahn, a consultant with German research platform Helmholtz AI and a collaborator on the global Belle II particle physics experiment, uses AI and Read article >

 IDC analysts Brad Casemore and Harsh Singh interviewed IT organizations with real world experience deploying and managing Cumulus Linux and NVIDIA Spectrum switches in mission critical data centers over a significant time period.
IDC analysts Brad Casemore and Harsh Singh interviewed IT organizations with real world experience deploying and managing Cumulus Linux and NVIDIA Spectrum switches in mission critical data centers over a significant time period. 




 Learn how to compact the acceleration structure in DXR and what to know before you start implementing.
Learn how to compact the acceleration structure in DXR and what to know before you start implementing.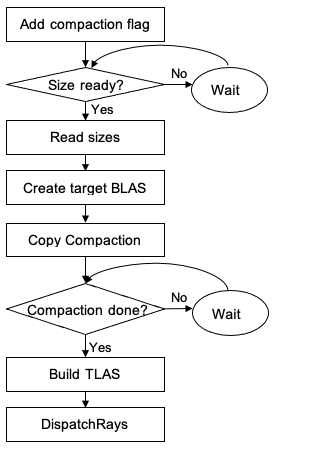
 In this post, we showcase our support for open-source robotics frameworks including ROS and ROS 2 on NVIDIA Jetson developer kits.
In this post, we showcase our support for open-source robotics frameworks including ROS and ROS 2 on NVIDIA Jetson developer kits.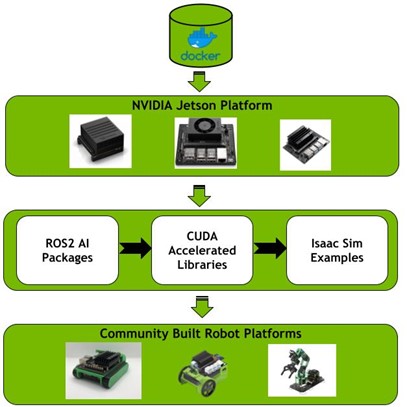




 With over 1600 sessions on the latest in AI, data center, accelerated computing, healthcare, intelligent networking, game development, and more – there is something for everyone.
With over 1600 sessions on the latest in AI, data center, accelerated computing, healthcare, intelligent networking, game development, and more – there is something for everyone.

 SIGGRAPH 2021 is the premier conference and exhibition in computer graphics and interactive techniques. This year, participants can join a series of exciting pre-conference webinars called SIGGRAPH Frontiers Interactions.
SIGGRAPH 2021 is the premier conference and exhibition in computer graphics and interactive techniques. This year, participants can join a series of exciting pre-conference webinars called SIGGRAPH Frontiers Interactions. 
