NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing … Continued
NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice
In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing short of stunning with local 8K DLSS support and global illumination through RTXGI.
Recently, NetEase introduced Mesh Shader support to Justice. Not only are the updated environments breathtaking, the game supports 1.8 billion triangles running over 60 FPS in 4K on an NVIDIA 3060Ti.
To learn more about the implementation and results, we sat down with Yuheng Zou, game engine developer at NetEase. His work focuses on the rendering engine in Justice, specifically GPU features enabled by DirectX 12.
Q: What are you trying to achieve by adding mesh shading to Justice?
Our first thought is to render some highly detailed models which may need insane number of triangles. Soon we found we can combine Mesh Shaders with auto-generated LODs to achieve almost only-resolution-relevant rendering complexity, instead of polygon number. And we decided to try it out. With so much potential of Mesh Shader, we conceive that it would be the main stream of future games.
Q: What is not currently working with regular compute / draw indirect / traditional methods?
The simple draw call just doesn’t work for this. It lacks the ability to process mesh in a coarser grain than triangle, like meshlet culling.
Compute or draw indirect may be fine, but we do need to make a huge change on the rendering pipeline. The underlying idea of the algorithm is, in the first place, to do culling, then draw the effective parts of mesh. While it can be achieved by culling and compacting with compute shader and then drawing indirect, the data exchange between the two-step process can sometimes be fatal to GPU under highpoly rendering context. Mesh shader solves this problem from the hardware level.
Q: How do Mesh Shaders solve this?
Mesh shader can extend the scalability of geometry stage, and is very easy to integrate to engine runtime. It has the ability to encapsulate the culling procedure in a single API call, which omits tedious state and resource set up procedure as draw indirect requires. With MeshShaders, the culling algorithms we use can be of great flexibility. For example, in the shadow pass, we don’t have the depth information so occlusion culling is simply ignored in the shader.
Q: Is the end result of adding Mesh Shaders something your players will quickly notice, or is the effect more subtle?
Our technology customizes a highpoly mesh pipeline, including production, processing, serialization, streaming and rendering, aiming to provide our players with a refreshed experience with such high-fidelity contents. Actually, it works. Soon after “Wan Fo Ku” released, our players found the models presented were much more elaborate than the traditional one, with many close-up screenshots posted on the forums. While adding Mesh Shaders under customized highpoly scene do boost the rendering effectiveness, how to optimize our traditional scene remains subtle and needs more engineering efforts.
Q: What kinds of environments benefited most from the technology?
Our technology enables the ability of rendering parallax and silhouette of models in an incredible fidelity. For scenes like caves, these details can produce a visually better image. It also provides Chinese ancient buildings, furniture and ornaments with “meticulous” rendering result, which enables the culture carried by them to be expressed in Justice to the finest extent.
Q: What is the one thing you wish you knew before you added mesh shading? What would you do differently based on your learnings?
With such detailed models, large texture resolution is a must. We will pay more attention to texture loading or streaming. This also makes further requirements to our mesh/texture compression algorithms.
Q: Any other tips for developers looking to work with Mesh Shaders for the first time?
Mesh shader has the possibility of boosting geometry stage drastically. However, careful profiling and optimization is required. We highly recommend NSight for debugging and profiling Mesh Shaders.
Doing GPU culling with Mesh Shaders will sometimes require a change on mesh representation data format. A clever data format design will enable your trial and error, making a lot faster progress.
Since 2016, Justice has been closely engaged with NVIDIA in China on video game graphics technology innovation. As one of the best PC MMO games in China market, Justice has attracted thirty millions of players in the past three years with its excellent technologies and beautiful graphics.
Learn more about NVIDIA’s technical resources for Game Developers here.
Every day, vast amounts of geospatial imagery are being collected, and yet, until recently, one of the biggest potential users of that trove — property insurers — had made surprisingly little use of it. Now, CAPE Analytics, a computer vision startup and NVIDIA Inception member, seeks to turn that trove of geospatial imagery into better Read article >
A team of NVIDIA artists released never-before-seen imagery and behind-the-scenes videos from the Omniverse RTX Racer playable sample project. The clips and imagery are the result of 3 weeks of progress, showcasing the Omniverse platform’s power in multi-GPU rendering, dynamic lighting, and real-time rendering.
A team of NVIDIA artists released never-before-seen imagery and behind-the-scenes videos from the Omniverse RTX Racer playable sample project. The clips and imagery are the result of 3 weeks of progress, showcasing the Omniverse platform’s power in multi-GPU rendering, dynamic lighting, and real-time rendering.
The racing demo consists of a loop level, where a player controls a dune buggy vehicle, with the ability to steer, accelerate, decelerate, and brake.
With no difference between editing and “play” mode within NVIDIA Omniverse, users can move the camera and control the vehicle, or change the lighting, simultaneously, in real time.
Creative and Collaborative Workflows in Omniverse
The photorealistic scenes, characters, and props were created using a variety of creative applications such as Pixologic ZBrush, Autodesk 3ds Max, Autodesk Maya and Blender, textured in Substance Painter, and rendered with Omniverse RTX Renderer. Using Omniverse Create, two artists worked collaboratively on the rocky, desert environment, leveraging the platform’s live sync abilities to adjust environment art, layout and lighting simultaneously. The Omniverse platform’s simulation suite, including NVIDIA PhysX 5, delivered physically accurate simulation, providing players with a true-to-reality experience as they raced their buggy across the rugged terrain.
The cheeky alien main character was sculpted entirely in ZBrush, refined in Autodesk Maya and textured in Substance Painter.
Alien driver. Substance Painter. Rendered in NVIDIA Iray.
The dune buggy, a custom vehicle designed to race around desert dunes, was modeled in Autodesk Fusion 360 and textured in Substance Painter. The vehicle is physically based, and went through various iterations in size and dimensions to find the optimal racing balance in the physically accurate environment.
Dune buggy. Autodesk Fusion 360 viewport.
One Renderer, Dual Personalities
Omniverse RTX Renderer works in two different modes: real-time ray-traced mode and referenced path-traced mode. The demo is able to run in both modes without a significant difference in graphics quality — the materials and visual output are very similar.
At a high level, both modes implement the same rendering algorithm for path tracing, but with different optimization and approximations choices. The real-time ray-traced mode is typically used in real-time simulation applications such as games, while the reference path-traced mode is used for projects requiring ultra-high fidelity, final-frame quality results as it accumulates many samples over many frames, often requiring multiple GPUs.
Leveraging the power of four NVIDIA RTX 8000 GPUs, the NVIDIA team experimented with referenced path-traced mode, ultimately achieving offline film quality rendering at near real-time speeds.
Bringing it to Life with Omniverse Physics
The Omniverse RTX Racer project also showcases NVIDIA Omniverse’s advanced physics simulation suite including PhysX 5, exclusively available to the public as part of the platform, NVIDIA Flow, and Blast.
PhysX provides the powerful vehicle authoring technology that made the dune buggy come to life. The same vehicle authoring technology is used as part of the new NVIDIA DRIVE Sim platform for training and validating self-driving cars, now built entirely on Omniverse. With accurate steering, suspension, wheel collision, and tire friction behavior, users can easily create multiple instances of different styles of vehicles.
The team of artists and developers used this project to experiment with Flow, a sparse grid-based fluids simulation package for real-time applications that was recently integrated into the Omniverse platform. Flow was used to simulate the buggy’s blazing rocket engine and cloudy dust trail. This effect is written in Slang, the NVIDIA cross-platform shading language, and simulated entirely on NVIDIA GPUs.
The Omniverse RTX Racer sample is a living project with future iterations to come. Learn more about NVIDIA Omniverse and download the open beta today.
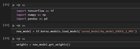
I have a question about TFRecords and how to train tf.keras models with them. For this I built a toy example, loading the iris dataset, writing the the data to a TFRecord, reading it back in and trying to train a simple MLP I found in a tutorial.
For encoding/writing/reading/decoding the TFRecords I followed mostly the official [Tutorial](https://www.tensorflow.org/tutorials/load_data/tfrecord). As far as I am able to see I can recover the original data, so I thought I plug the dataset into the MLP as the [fit method](https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit) should be able to work with tf.data datasets. In an example notebook with the MNIST dataset it worked fine, but in my case fit throws the following error:
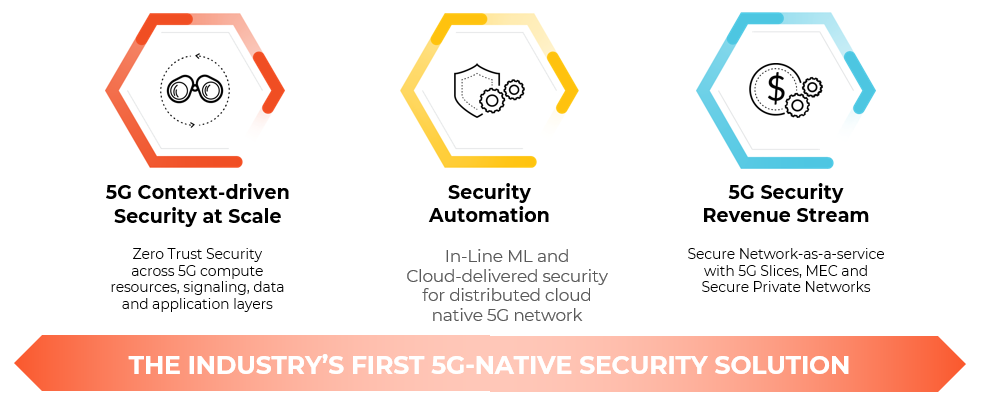
Watch the replay of this joint session at GTC 21 to learn about achieving near-line rate speed of a next-generation firewall through the use of DPUs for a highly efficient 5G native security solution.
5G is unlike earlier generations of wireless networks. 5G offers many new capabilities such as lower latency, higher reliability and throughput, agile service deployment through cloud-native architectures, greater device density, and more. The adoption of 5G and its expanded capabilities drives the bandwidth requirements of mobile networks to 100Gbps and beyond.
With 5G and the increasingly frequent implementations of cloud computing, a new direction in cyber-security is required to maintain adequate protection. Today’s cyber-attack methods are demonstrating increased sophistication and going after larger attack surfaces. Coupling this with modern cloud environments – which are more vulnerable than on-premises deployments – makes proper security enforcement difficult. With 5G, a new approach to security is needed to achieve adequate protection.
Figure 1. Properly securing 5G networks is becoming increasingly challenging
Next-generation 5G Firewall
Palo Alto Networks and NVIDIA have collaborated to create a scalable, adaptive security solution that combines the Palo Alto Next-Generation Firewall with the NVIDIA BlueField-2 Data Processing Unit (DPU). Integrating these two raises the bar for high-performance security in virtualized software-defined networks. The NVIDIA BlueField-2 DPU provides a rich set of network offload engines designed to address evolving security needs within demanding markets such as 5G and the cloud. Palo Alto Networks has taken its expertise in securing enterprise and mobile networks and applied it to 5G. They used this knowledge to implement a 5G-native security initiative that includes a virtual firewall. The virtual firewall is designed to meet the stringent security needs of 5G cloud-native environments, offering scale, operational simplicity, and automation, enabling customers to gain unparalleled security protection.
For data centers looking to modernize their security infrastructure within 5G and cloud environments, the power of a software-defined, hardware-accelerated security architecture from NVIDIA and Palo Alto Networks provides increased infrastructure efficiency, granular zero-trust security across the entire solution stack, and streamlined security and management operations.
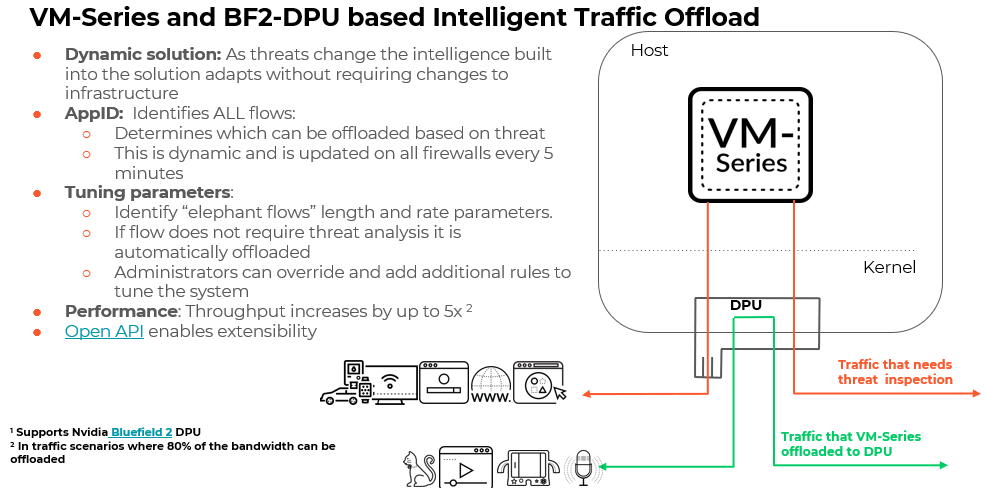
Figure 3. Intelligent traffic offload provided by BlueField-2 DPU
The dynamic nature of this solution has intelligent traffic offloads built in so that it adapts to real-time threats without requiring changes to the network infrastructure. The NVIDIA ASAP2 VNF offload technology filters or steers traffic for elephant flows identified based on AppID. Further, this AppID is used to inspect the first few packets to detect if it contains a threat or if it can offload the flow. If the packet is not suitable for offload, it is sent to the firewall for inspection. If the firewall determines the session is of no threat, it is sent to the PAN gRPCd process that calls the DPU daemon to add the session to the DPU session table for future offloading. The DPU will handle all subsequent packets in the flow without consuming any server CPU cycles for firewall processing. The solution provides up to 100Gb/s throughput with 80% of traffic offloaded to the DPU and ensures the highest performance without utilizing the CPU. This results in an throughput increase of 5X compared to host-based traditional firewall security solutions.
At GTC21, NVIDIA and Palo Alto Networks jointly presented the intelligent traffic offload use-case for 5G native security. Watch the replay of this joint session to learn about achieving near-line rate speed of a next-generation firewall through the use of DPUs for a highly efficient 5G native security solution. Don’t miss the demonstration showcasing the flexibility, programmability, and agility of the Palo Alto Networks and NVIDIA joint cyber-security solution. The GA of this solution is targeted for May 2021. Please connect with your NVIDIA or Palo Alto Networks sales representatives to learn more.
Click here to watch the recorded session from GTC.
As computing power moves to edge computing, NVIDIA announces the EGX platform and ecosystem, including server-vendor certifications, hybrid cloud partners, and new GPU Operator software.
Demand for edge computing is growing rapidly because people increasingly need to analyze and use data where it’s created instead of trying to send it back to a data center. New applications cannot wait for the data to travel all the way to a centralized server, wait for it to be analyzed, then wait for the results to make the return trip. They need the data analyzed RIGHT HERE, RIGHT NOW!
To meet this need, NVIDIA just announced an expansion of the NVIDIA EGX platform and ecosystem, which includes server vendor certifications, hybrid cloud partners, and new GPU Operator software that enables a cloud-native deployment for GPU servers. As computing power moves to the edge, we find that smarter edge computing needs smarter networking, and so the EGX ecosystem includes NVIDIA networking solutions.
IoT drives the need for edge computing
The growth of the Internet of Things (IoT), 5G wireless, and AI are all driving the move of compute to the edge. IoT means more—and smarter—devices are generating and consuming more data but in the field, far from traditional data centers. Autonomous vehicles, digital video cameras, kiosks, medical equipment, building sensors, smart cash registers, location tags, and of course phones will soon generate data from billions of end points. This data must be collected, filtered, and analyzed. Often, the distilled results are transferred to another data center or endpoint somewhere else. Sending all the data back to the data center without any edge processing not only adds much latency, it’s often too much data to transmit over WAN connections. Data centers often don’t even have enough room to store all the unfiltered, uncompressed data coming from the edge.
5G brings higher bandwidth and lower latency to the edge, enabling faster data acquisition and new applications for IoT devices. Data that previously wasn’t collected or which couldn’t be shared is now available over the air. The faster wireless connectivity enables new applications that use and respond to data at the edge, in real time. That’s instead of waiting for it to be stored centrally then analyzed later, if it’s analyzed at all.
AI means more useful information can be derived from all the new data, driving quick decisions. The flood of IoT data is too voluminous to be analyzed by humans. It requires AI technology to separate the wheat from the chaff (the signal from the noise). The decision and insights from AI then feed applications both at the edge and back in the central data center.
Figure 1. IoT and 5G wireless drive increased deployment of AI computing at the edge.
NVIDIA EGX delivers AI at the edge
Many edge AI workloads—such as image recognition, video processing, and robotics—require massive parallel processing power, an area where NVIDIA GPUs are unmatched. To meet the need for more advanced AI processing at the edge, NVIDIA introduced the EGX platform. The EGX platform supports a hyper-scalable range of GPU servers, from a single NVIDIA Jetson Nano system up to a full rack of NVIDIA T4 or V100 Tensor Core servers. The Jetson Nano delivers up to half a trillion operations per second (1/2 TOPS), while a full rack of T4 servers can handle ten thousand trillion operations per second (10,000 TOPS).
NVIDIA EGX also includes container-based tools, drivers, and NVIDIA CUDA-X libraries to support AI applications at the edge. EGX is supported by major server vendors and includes integration with Red Hat OpenShift to provide enterprise-class container orchestration based on Kubernetes. This is all critical because so many of the edge computing locations—retail stores, hospitals, self-driving cars, homes, factories, cell phones, and so on— are supported by enterprises, local government, and telcos, not by hyperscalers.
Recently, NVIDIA announced new EGX features and customer implementations, along with strong support for hybrid cloud solutions. The NGC-Ready server certification program has been expanded to include tests for edge security and remote management, and the new NVIDIA GPU Operator simplifies management and operation of AI across widely distributed edge devices.
Figure 2. NVIDIA EGX platform includes GPU, CUDA-X interfaces, container management, and certified hardware partners.
Smarter edge needs smarter networking
But there is another class of technology and partners needed to make EGX—and AI at the edge—as smart and efficient as it can be: networking. As the amount of GPU-processing power at the edge and the number of containers increases, the amount of network traffic can also increase exponentially.
Before AI, the analyzable edge data traffic, not counting streamed graphics, videos and music going out to phones, probably flowed 95% inbound. For example, data might flow from cameras to digital video recorders, from cars to servers, or from retail stores to a central data center. Any analysis or insight would often be human-driven, as people can only concentrate and observe a single stream of video. The data might be stored for a later date, removing the ability to make instant decisions.
Now, with AI solutions like EGX deployed at the edge, applications must talk with IoT devices, back to servers in the data center, and with each other. AI applications trade data and results with standard CPUs, data from the edge is synthesized with data from the corporate data center or public cloud, and the results get pushed back to the kiosks, cars, appliances, MRI scanners, and phones.
The result is a massive amount of N-way data traffic between containers, IoT devices, GPU servers, the cloud, and traditional centralized servers. Software-defined networking (SDN) and network virtualization play a larger role. This expanded networking brings new security concerns, as the potential attack surface for hackers and malware is much larger than before and cannot be contained inside a firewall.
As networking becomes more complex, the network must become smarter in many ways. Some examples of this are:
Packets must be routed efficiently between containers, VMs, and bare metal servers.
Network function virtualization (NFV) and SDN demand accelerated packet switching, which could be in user space or kernel space.
The use of RDMA requires hardware offloads on the NICs and intelligent traffic management on the switches.
Security requires that data be encrypted at rest or in flight, or both. Whatever is encrypted must also be decrypted at some point.
The growth in IoT data combined with the switch from spinning disk to flash call for compression and deduplication of data to control storage costs.
These increased network complexity and security concerns impose a growing burden on the edge servers as well as on the corporate and cloud servers that interface with them. With more AI power and faster network speeds, handling the network virtualization, SDN rules, and security filtering sucks up an expensive share of CPU cycles, unless you have the right kind of smart network. As the network connections get faster, that network’s smarts must be accelerated in hardware instead of running in software.
SmartNICs save edge compute cycles
Smarter edge computing requires smarter networking. If this networking is handled by the CPUs or GPUs, then valuable cycles are consumed by moving the data instead of analyzing and transforming it. Someone must encode and decode overlay network headers, determine which packet goes to which container, and ensure that SDN rules are followed. Software-defined firewalls and routers impose additional CPU burdens as packets must be filtered based on source, destination, headers, or even on the internal content of the packets. Then, the packets are forwarded, mirrored, rerouted, or even dropped, depending on the network rules.
Fortunately, there is a class of affordable SmartNICs, such as the NVIDIA ConnectX family, which offload all this work from the CPU. These adapters have hardware-accelerated functions to handle overlay networks, Remote Direct Memory Access, container networking, virtual switching, storage networking, and video streaming. They also accelerate the adapter side of network congestion management and QoS.
The newest adapters, such as the ConnectX-6 Dx, can perform in-line encryption and decryption in hardware at high speeds, supporting IPsec and TLS. With these important but repetitive network tasks safely accelerated by the NIC, the CPUs and GPUs at the edge connect quickly and efficiently with each other and the IoT, all the while focusing their core cycles on what they do best—running applications and parallelized processing of complex data.
BlueField DPU adds extra protection against malware and overwork
An even more advanced network option for edge compute efficiency is a DPU or data processing unit, such as the NVIDIA BlueField DPU. A DPU combines all the high-speed networking and offloads of a SmartNIC with programmable cores that can handle additional functions around networking, storage, or security.
It can offload both SDN data plane and control plane functions.
It can virtualize flash storage for CPUs or GPUs.
It can implement security in a separate domain to provide very high levels of protection against malware.
On the security side, DPUs such as BlueField provide security domain isolation. Without isolation, any security software is running in the same domain as the OS, container management, and application. If an attacker compromises any of those, the security software is at risk of being bypassed, removed, or corrupted. With BlueField, the security software continues running on the DPU where it can continue to detect, isolate, and report malware or breaches on the server. By running in a separate domain—protected by a hardware root of trust—the security features can sound the alarm to intrusion detection and prevention mechanisms and also prevent malware on the infected server from spreading.
The newest BlueField-2 DPU also adds regular expression (RegEx) matching that can quickly detect patterns in network traffic or server memory, so it can be used for threat identification. It also adds hardware offloads for data efficiency using deduplication through a SHA-2 hash and compression/decompression.
Smarter networkingat the edge
With the increasing use of AI solutions at the edge, like the NVIDIA EGX platform, the edge becomes infinitely smarter. However, networking and security also get more complex and threaten to slow down servers, just when the growth of the IoT and 5G wireless requires more compute power. This can be solved with the deployment of SmartNICs and DPUs, such as the ConnectX and BlueField product families. These network solutions offload important network and security tasks, such as SDN, network virtualization, and software-defined firewall functions. This allows AI at the edge to run more efficiently and securely.

 NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing … Continued
NetEase Thunder Fire Games Uses Mesh Shading To Create Beautiful Game Environments for Justice In December, we interviewed Haiyong Qian, NetEase Game Engine Development Researcher and Manager of NetEase Thunder Fire Games Technical Center, to see what he’s learned as the Justice team added NVIDIA ray-tracing solutions to their development pipeline. Their results were nothing … Continued

 A team of NVIDIA artists released never-before-seen imagery and behind-the-scenes videos from the Omniverse RTX Racer playable sample project. The clips and imagery are the result of 3 weeks of progress, showcasing the Omniverse platform’s power in multi-GPU rendering, dynamic lighting, and real-time rendering.
A team of NVIDIA artists released never-before-seen imagery and behind-the-scenes videos from the Omniverse RTX Racer playable sample project. The clips and imagery are the result of 3 weeks of progress, showcasing the Omniverse platform’s power in multi-GPU rendering, dynamic lighting, and real-time rendering.



 Watch the replay of this joint session at GTC 21 to learn about achieving near-line rate speed of a next-generation firewall through the use of DPUs for a highly efficient 5G native security solution.
Watch the replay of this joint session at GTC 21 to learn about achieving near-line rate speed of a next-generation firewall through the use of DPUs for a highly efficient 5G native security solution.
 As computing power moves to edge computing, NVIDIA announces the EGX platform and ecosystem, including server-vendor certifications, hybrid cloud partners, and new GPU Operator software.
As computing power moves to edge computing, NVIDIA announces the EGX platform and ecosystem, including server-vendor certifications, hybrid cloud partners, and new GPU Operator software.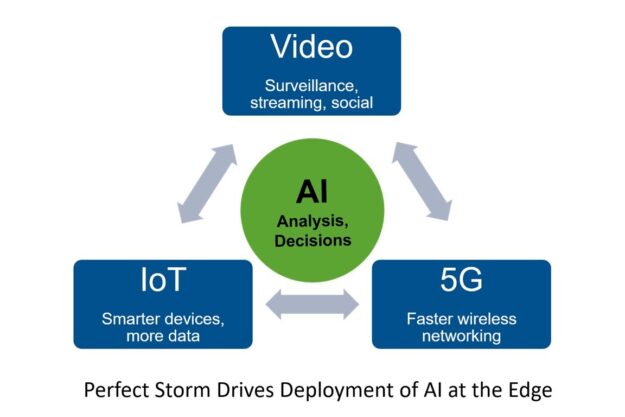

{kind=link}