I’m trying to use Tensorflow to predict the outcome of a sport contest. What I have for every sample is the context of the competition (weather, type of stadium, …) and the competition history for every competing team.
Here is an overview of the data of every sample:
Context
Teams History
CompetitionData
[[CompetitionData], [CompetitionData]] (for every team, the past competition data and their result (win/lose/ranking)
I’m going to try to develop a Learning to Rank System, where given the context and every team history, predict the final ranking.
I think that feature columns are useful in this case, as they can ease the processing of the Competition Data. However, I can’t find a way to reuse the feature column code across all Competition data dimensions. The ideal would be to reuse the DenseFeatures layers across all competition data, but it doesn’t seems to work as tf requires the data to be of dict type to be fed to the Densefeature layers, which needs to be passed one by one trough an input layer to be correctly inputted.
statics_hist = {
‘rapport’: Input((1,), dtype=tf.dtypes.int32, name=”rapport”),
‘weight’: Input((1,), dtype=tf.dtypes.int32, name=”weight”),
‘age’: Input((1,), name=”age”),
‘first’: Input((1,), dtype=tf.dtypes.int32, name=”first”),
‘stadium’: Input((1,), name=”stadiul”, dtype=tf.dtypes.string)
}
test = [stack([history_input(statics_hist) for _ in range(NB_RACE_HISTORY)], axis=1) for __ in range(MAX_NUMBER_PLAYERS)]
test = stack(test, axis=1)
But as I have 15 players with each 10 competition history of several columns, this gives me 750+ input layers, which can’t be the right way to go.
I have thought about flattening the data beforehand, but then I would lose the ability to run an LSTM trough a player history, which is important to modelize his current performance.
I’m not really sure of the right way to go, could anyone point me in the right direction ?
The rollout of 5G for edge AI services promises to fuel a magic carpet ride into the future for everything from autonomous vehicles, to supply chains and education. That was a key takeaway from a panel of five 5G experts speaking at NVIDIA’s GPU Technology Conference this week. With speed boosts up to 10x that Read article >
University of Pennsylvania researchers have used convolutional neural networks to catalog the morphology of 27 million galaxies, giving astronomers a massive dataset for studying the evolution of the universe.
University of Pennsylvania researchers have used convolutional neural networks to catalog the morphology of 27 million galaxies, giving astronomers a massive dataset for studying the evolution of the universe.
“Galaxy morphology is one of the key aspects of galaxy evolution,” said study author Helena Domínguez Sánchez, former postdoc at Penn. “The shape and structure of galaxies has a lot of information about the way they were formed, and knowing their morphologies gives us clues as to the likely pathways for the formation of the galaxies.”
While past research projects have focused on classifying images of bright, nearby galaxies, the team focused their neural network on fainter, further galaxies captured by the Dark Energy Survey, an international project to image an eighth of the sky.
The further away a galaxy is from the Milky Way, the longer it takes for light to reach our corner of the universe. So images from the Dark Energy Survey, which contains more images of distant galaxies than previous studies, “show us what galaxies looked like more than 6 billion years ago,” said Mariangela Bernardi, professor in the Department of Physics and Astronomy at Penn.
While the researchers already had a CNN that could categorize galaxies as spiral or elliptical, the model had been trained on nearby galaxies captured in the Sloan Digital Sky Survey. To teach the neural network to process further, more pixelated images from the Dark Energy Survey, the team collected a labeled dataset of 20,000 galaxies from both astronomical surveys, where the morphological classifications were already known.
They then created a synthetic dataset that simulated how the images would look if they depicted galaxies that were further away.
Simulated spiral and elliptical galaxy images illustrate how fainter and more distant galaxies would look in the Dark Energy Survey dataset.
Once trained on a combination of simulated and real galaxy images, the CNN was applied to the massive Dark Energy Survey dataset, cataloging 27 million galaxies as either early-type or late-type galaxies, and as face-on or edge-on images.
The team used NVIDIA GPUs on Amazon Web Services for training and inference of their neural network. They found the model was 97 percent accurate at classifying the morphology of even faint galaxies too difficult to categorize by eye.
The resulting collection is the largest multi-band catalog of automated galaxy morphologies to date.
“We pushed the limits by three orders of magnitude, to objects that are 1,000 times fainter than the original ones,” said lead author Jesús Vega-Ferrero. “That is why we were able to include so many more galaxies in the catalog.”
The researchers are next combining the morphological classification predictions with additional factors including the age, mass, distance, star-formation rate, and chemical composition of the galaxies to enable a better understanding of the relationship between galaxy morphology and star formation.
I often get a ton of questions from programmers and data scientists about audio data preprocessing:
– How can I extract spectrograms?
– How can I normalise the signal?
– What if I have files of different lengths?
To answer these questions and more, I published a tutorial where you can learn how to build an audio preprocessing pipeline for AI applications. The pipeline batch preprocesses audio files applying Short-Time Fourier Transform, zero-padding, normalisation all in one go!
This video is a new installment of the series “Generating sound with neural nets”, where you can learn to generate sound using Variational AutoEncoders.
Mercedes-Benz is calling on its long heritage of luxury to accelerate electric vehicle technology with the new EQS sedan. The premium automaker lifted the wraps off the long-awaited flagship EV during a digital event today. The focal point of the revolutionary vehicle is the MBUX Hyperscreen, a truly intuitive and personalized AI cockpit, powered by Read article >
Fasten your seatbelts. NVIDIA Research is revving up a new deep learning engine that creates 3D object models from standard 2D images — and can bring iconic cars like the Knight Rider’s AI-powered KITT to life — in NVIDIA Omniverse. Developed by the NVIDIA AI Research Lab in Toronto, the GANverse3D application inflates flat images Read article >
The CUDA 11.3 release of the CUDA C++ compiler toolchain incorporates new features aimed at improving developer productivity and code performance. NVIDIA is introducing cu++flt, a standalone demangler tool that allows you to decode mangled function names to aid source code correlation. Starting with this release, the NVRTC shared library versioning scheme is relaxed to … Continued
The CUDA 11.3 release of the CUDA C++ compiler toolchain incorporates new features aimed at improving developer productivity and code performance. NVIDIA is introducing cu++flt, a standalone demangler tool that allows you to decode mangled function names to aid source code correlation.
Starting with this release, the NVRTC shared library versioning scheme is relaxed to facilitate compatible upgrades of the library within a CUDA major release sequence. The alloca built-in function that can be used to allocate dynamic memory out of the stack frame is now available for use in device code as a preview feature.
With the CUDA 11.3 release, the CUDA C++ language is extended to enable the use of the constexpr and auto keywords in broader contexts. The CUDA device linker has also been extended with options that can be used to dump the call graph for device code along with register usage information to facilitate performance analysis and tuning.
We are again proud to help enhance the developer experience on the CUDA platform.
Standalone demangler tool: cu++filt
To facilitate function overloading in CUDA C++, the NVCC compiler frontend mangles (or encodes) function identifiers to include information about their return types and arguments. The compiler follows the Itanium C++ (IA-64) mangling scheme, with some added CUDA specific extensions.
When disassembling or debugging CUDA programs, it is hard to trace the mangled identifier back to its original function name as the encoded names are not human readable. To simplify debugging and to improve readability of PTX assembly, we introduced a new CUDA SDK tool in the CUDA SDK: cu++filt.
The cu++filt tool demangles or decodes these mangled function names back to their original identifiers for readability. You can use the demangled names for precisely tracing the call flow. We modelled this tool after the GNU C++ demangler: c++filt with a similar user interface. This tool can be found in the bin directory of the CUDA SDK and is available on the Linux and Windows operating systems.
Starting with the CUDA 11.3 release, the NVRTC shared library versioning scheme and the library naming convention is relaxed to allow you to use newer NVRTC libraries on older toolkits, but only within a major CUDA release series.
Typically, an NVRTC library’s SONAME value (Linux), or the DLL file name (Windows), always encoded both the major and minor number of the CUDA toolkit version to which it belonged. As a result, developers were unable to upgrade to the latest NVRTC library without upgrading the entire CUDA toolkit.
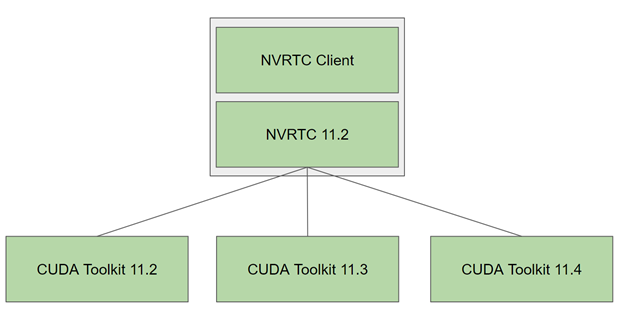
Figure 1. NVRTC shared library relaxed versioning scheme allows newer NVRTC to be a drop-in replacement for the NVRTC shared library in a CUDA toolkit from within a major release having a matching SONAME or DLL filename.
In CUDA toolkits prior to CUDA 11.3, the SONAME value was in the form MAJOR.MINOR and the DLL filename was in the form nvrtc64_XY_0.dll, where X=MAJOR, Y=MINOR. Starting from CUDA 11.3, and for all future CUDA 11.x toolkit releases, the NVRTC shared library version will not change and will be frozen at 11.2. The SONAME in the Linux version of the library is 11.2 and the corresponding DLL filename in Windows is nvrtc64_112_0.dll.
From the next major CUDA release onwards, X (which will be greater than 11), the NVRTC shared library’s SONAME and its DLL filename equivalent will only encode the CUDA major version. On Linux, the SONAME will be X and on Windows the DLL filename will be nvrtc64_X0_0.dll, where X is the major version.
Figure 1 shows that this relaxed versioning scheme enables you to easily upgrade to a newer NVRTC library within the same major release stream and take advantage of bug fixes and performance improvements. The current version of the NVRTC library in use can be found by using the nvrtcVersion API:
nvrtcResult nvrtcVersion(int *major, int *minor);
However, there is a caveat. A more recent NVRTC library may generate PTX with a version that is not accepted by the CUDA Driver API functions of an older CUDA driver. In the event of such an incompatibility between the CUDA Driver and the newer NVRTC library, you have two options:
Install a more recent CUDA driver that is compatible with the CUDA toolkit containing the NVRTC library being used.
Compile device code directly to SASS instead of PTX with NVRTC, using the nvrtcGetCUBIN API introduced in 11.2.
This versioning scheme allows applications developed using different toolkits to coexist and NVRTC to be redistributed along with it without a dependency on the toolkit versions. It also allows applications to take advantage of the latest compiler enhancements by updating the library transparently.
However, those updates could impact performance in some cases, especially for highly tuned code that depends on compiler heuristics that may change across CUDA versions. Expert users who would like to optimize for a specific version of NVRTC and want to maintain that dependency can do so using the dlopen (Linux) or LoadLibrary (Windows) API functions to use a specific library version at run time on an existing installation from a compatible minor release.
Preview support for alloca
CUDA C++ supports dynamic memory allocation using either the built-in function malloc or using the operator new. However, allocations by malloc and new contribute to significant runtime performance overhead due to dynamic allocation on the heap.
In CUDA 11.3, CUDA C++ introduces support for using the memory allocator alloca in device code as a preview feature. Unlike malloc and new, the built-in function alloca allocates memory on the current thread’s stack, offering a faster and more convenient way to allocate small chunks of memory dynamically. This is especially useful when the size of an allocation is not known in advance at compile time.
When memory is allocated using alloca, the stack pointer of the thread’s stack is moved based on the requested memory allocation size to reserve or otherwise allocate the memory. The memory allocated is aligned at a 16-byte boundary, making possible accesses using all basic types, including vector types, without alignment constraints.
There are some caveats that you should pay attention to when using alloca, so that you don’t risk introducing memory corruptions or undefined behaviors during program execution. Consider the following code sample of allocate.cu:
$ cat allocate.cu
...
#ifdef USE_MALLOC
#define ALLOC(sz) malloc((sz))
#define FREE(ptr) free((ptr))
#else
#define ALLOC(sz) alloca((sz))
#define FREE(ptr)
#endif
__device__ int out;
__device__ int foo(int *ptr1, int *ptr2, int len)
{
int ret = 0;
for (int i=0; i
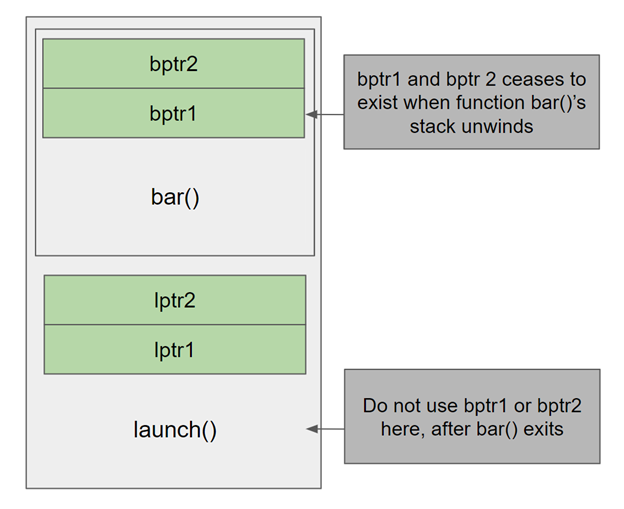
Figure 2. Thread stack frame of launch that in turn invokes bar.
Unlike memory allocated using malloc or new that must be explicitly freed, memory allocated by bar using allocais part of the stack, so it should not be freed or accessed after the stack unwinds.
Thread stack space is a limited resource. Be wary of a possible stack overflow when using alloca. Currently, you can’t determine ahead of time whether the stack is going to overflow. To aid you, a ptax warning is shown when compiling a code using alloca, reminding you that the stack size cannot be determined at compile time.
$ nvcc.exe -arch=sm_80 allocate.cu -o allocate.exe
ptxas warning : Stack size for entry function '_Z6launchi' cannot be statically determined
Creating library alloc.lib and object alloc.exp
As the CUDA driver cannot set the correct stack size for the program, the default stack size is used. Set stack size according to the actual stack memory usage in the program.
Despite the caveats, the potential performance benefits of using alloca combined with the automatic memory management makes alloca an attractive alternative to dynamic memory allocation on the heap.
Comparing alloca and malloc usage and performance
The performance benefits of allocating memory on the thread stack using allocais significant.
The earlier allocate.cu example showed the difference in usage and performance between stack based alloca and heap-based, per-thread malloc. Before launching the kernel, you must set device limits properly, with cudaDeviceSetLimit (cudaLimitStackSize, bytesPerThread) for stack size, or cudaDeviceSetLimit (cudaLimitMallocHeapSize, heapSize) for heap size. The FREE(ptr) is defined as free(ptr) only when USE_MALLOC is defined; otherwise, it is empty.
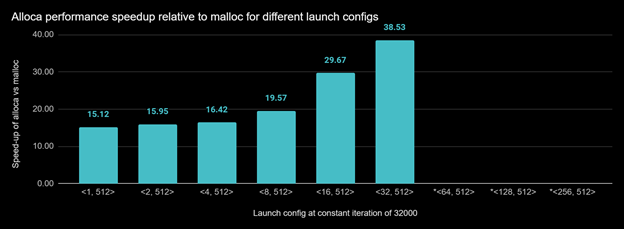
In the first performance measurement, we executed alloca.exe and malloc.exe with different launch configurations. When launch config is (block size is 512 and grid size is 64) and up, the malloc.exe ran out of memory for the heap size limit 500000000.
Figure 3. Execution time speedup of allocate.cu when using alloca vs. malloc for different launch configs. *malloc OOMed in these configurations.
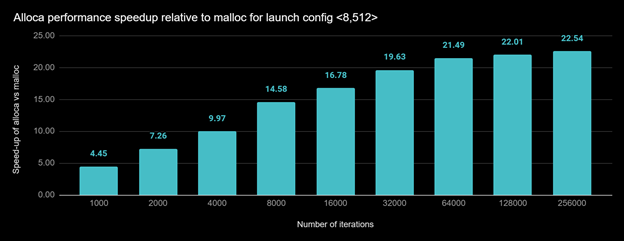
In the next measurement, we used fixed launch configuration , but doubled the number of iterations of bar for, which is invoked for each run. Figure 5 shows the results.
Figure 4. Execution time speedup of allocate.cu when using alloca vs. malloc for a given launch config .
In CUDA 11.3, the cuda-gdb/classic backend debugger returns a truncated stack. You can see the first device function that invokes alloca. Full support for alloca by CUDA tools may be available in the next release.
CUDA C++ support for new keywords
CUDA 11.3 has added device code support for new C++ keywords: constexpr and auto.
Support for constexpr
In CUDA C++, __device__ and __constant__ variables can now be declared constexpr. The constexpr variables can be used in constant expressions, where they are evaluated at compile time, or as normal variables in contexts where constant expressions are not required. While CUDA C++ allowed some uses of host constexpr variables from device code in constant expressions in 11.2 and earlier, using them in other contexts would result in errors. For this case, constexpr device variables now be used instead.
Example:
constexpr int host_var = 10;
__device__ constexpr int dev_var = 10;
__device__ void foo(int idx) {
constexpr int vx = host_var; // ok
constexpr int vy = dev_var; // also ok
const int& rx = host_var; // error, host_var is not defined in device code.
const int& ry = dev_var; // ok
}
Support for auto
In CUDA C++, we are introducing support for the auto type for namespace scope device variables. A placeholder type uses the initializer to deduce the type of the variable being declared. This can be useful as a shorthand if the type of the variable has a long name. It enables the declaration of namespace scope variable templates where the type of the initializer is not known until instantiation.
Example:
namespace N1 { namespace N2 { struct longStructName { int x; }; } }
constexpr __device__ N1::N2::longStructName foo() { return N1::N2::longStructName{10}; }
__device__ auto x = foo; // x has 'int' type
template constexpr __device__
auto foo() -> decltype(+T{}) { return {}; }
template __device__ auto y = foo();
__global__ void test() {
auto i = y; // i has type int
auto f = y; // f has type float
}
NVLINK call graph and register usage support
Optimizing for register usage can improve the performance of device code. To get the best performance in device code, it is important to consider the usage of limited GPU resources like registers, as using fewer registers can increase occupancy and parallelism. When using separate compilation, the linker builds a call graph and then propagates the register usage of the called device functions, up to the kernel function representing the root node of the call graph.
However, if there are indirect calls through function pointers, then the call graph conservatively adds an edge for every potential target. The targets are where the prototype (function signature) of potential target functions match the prototype of the function pointer call, and where the function target has their address taken somewhere. This can result in the call graph reaching functions that you know are not real targets. If these false targets increase the register usage, that can in turn affect occupancy, as we show later in this section.
In large CUDA C++ applications with complex call graphs or precompiled device libraries, it can be difficult to know what the device linker infers to be potential indirect function call targets. So, we’ve added an option to dump the call graph information. The option is specific to the device linker nvlink, which is invoked as follows:
nvcc -Xnvlink -dump-callgraph
By default, this dumps demangled names. To avoid demangled names, use the following:
nvcc -Xnvlink -dump-callgraph-no-demangle
The format of the -dump-callgraph output is as follows:
# A: s -> B // Function s is given a number #A, and s potentially calls the function number B".
# s [N] // s uses N registers
# ^s // s is entry point
# &s // s has address taken
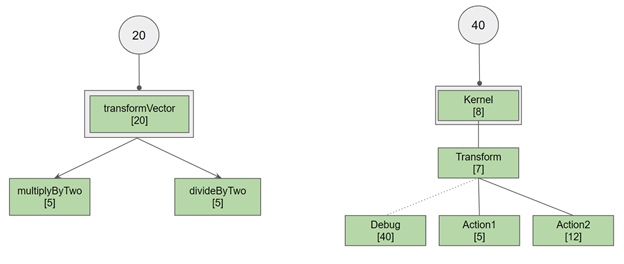
For the CUDA sample in 0_Simple/simpleSeparateCompilation, the following code is in one file:
__device__ float multiplyByTwo(float number)
{
return number * 2.0f;
}
__device__ float divideByTwo(float number)
{
return number * 0.5f;
}
Then another file has the following:
__device__ deviceFunc dMultiplyByTwoPtr = multiplyByTwo;
__device__ deviceFunc dDivideByTwoPtr = divideByTwo;
//! Applies the __device__ function "f" to each element of the vector "v".
__global__ void transformVector(float *v, deviceFunc f, uint size)
{
uint tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid
According to the call graph, the transformVector kernel calls two functions, divideByTwo (#4) and multiplyByTwo (#3). The called functions all use fewer registers (five) than transformVector[20], so the final register count stays at 20.
Figure 5. Call graph and corresponding register reservations for transformVector and Kernel.
Consider a more interesting case, where a Transform function calls either Action1 or Action2, but also potentially matches a Debug function:
In this case, Kernel calls Transform (function #4) which potentially calls Action2 (#3), Action1 (#2), and Debug (#1). The max register count for Action2, Action1, and Debug is 40 (for Debug), so a register usage of 40 ends up being propagated into Kernel. But if you know that Debug is not called by Transform, you could restructure your code to remove Debug from the call graph. Either modify the prototype for Debug or don’t have the address taken for Debug. The result would be that Transform would only call Action1 or Action2, which would then have a max register count of 12.
The resulting reduced register reservation increases the availability of the unused register for other kernels, increasing the throughput of kernel execution.
Try out the CUDA 11.3 compiler features
Whether it is the cu++flt demangler tool, redistributable NVRTC versioning scheme, or NVLINK call graph option, the compiler features and tools in CUDA 11.3 are aimed at improving your development experience on the CUDA platform. There is preview support for alloca in this release as well. Download today!
As always, please share any feedback or questions that you may have in the CUDA Forum or leave a comment here.
CUDA is the software development platform for building GPU-accelerated applications, providing all the components you need to develop applications that use NVIDIA GPUs. CUDA is ideal for diverse workloads from high performance computing, data science analytics, and AI applications. The latest release, CUDA 11.3, and its features are focused on enhancing the programming model and … Continued
CUDA is the software development platform for building GPU-accelerated applications, providing all the components you need to develop applications that use NVIDIA GPUs. CUDA is ideal for diverse workloads from high performance computing, data science analytics, and AI applications. The latest release, CUDA 11.3, and its features are focused on enhancing the programming model and performance of your CUDA applications.
CUDA 11.3 has several important features. In this post, I offer an overview of the key capabilities:
With every CUDA release, NVIDIA continues to enhance the CUDA programming model to enable you to get the most out of NVIDIA GPUs, while maintaining the programming flexibility of the higher-level APIs. In this release, we extended several of the CUDA APIs to improve the ease-of-use for CUDA graphs and enhance the stream-ordered memory allocator feature introduced in 11.2 among other update features.
CUDA Graphs
A graph is a series of operations, such as kernel launches, connected by dependencies, which is defined separately from its execution. This allows a graph to be defined once and then launched repeatedly, thus reducing overhead. CUDA graphs were introduced in CUDA 10.0 to allow work to be defined as graphs rather than single operations. For more information, see CUDA Graphs and Getting Started with CUDA Graphs.
Subsequent CUDA releases have seen a steady progression of new features. CUDA 11.3 introduces new features to improve the flexibility and the experience of using CUDA Graphs, such as:
Stream capture composability
User objects
Debug API
There are two ways to create CUDA graphs: construct the graph from scratch using graph APIs or use stream capture, which wraps a section of the application code and records the launched work from CUDA streams into a CUDA graph.
The new enhancements provide mutable access to the graph and to the set of dependencies of a capturing stream while capture is in progress, enabling new use patterns. You can intermix native graph node creation with stream capture more easily in the same graph. You can also pipeline tasks in new ways with the event-based dependency mechanics. Such access to the graph handle is required for the next feature, user objects.
User objects
Dynamic resources referenced by a graph must persist for the lifetime of the graph and until all executions have completed. This can be particularly challenging with stream capture, when the code responsible for the resource, such as a library, is not the same code managing the graph, such as the application code calling a library inside stream capture. User objects is a new feature to assist with the lifetime management of such resources in graphs by assisting with reference-counting the resource.
The following pseudo-code example shows how you can use the CUDA user object and the corresponding APIs to address this. The cudaUserObjectCreate API provides the mechanism to associate a user-specified, destructor callback with an internal refcount for managing a dynamic resource.
Object *object = new Object;
// Arbitrary C++ object
cudaUserObject_t cuObject;
// Template to wrap a delete statement in an extern "C" callback for CUDA:
cudaUserObjectCreate(&cuObject, object);
// Transfer our one reference (from calling create) to a graph:
cudaGraphRetainUserObject(graph, cuObject, cudaGraphUserObjectMove);
// No more references owned by this thread; no need to call release.
cudaGraphInstantiate(&graphExec, graph);
// Retains an additional reference
cudaGraphDestroy(graph);
// graphExec still owns a reference
cudaGraphLaunch(graphExec, stream);
// graphExec has access while executing
// The execution is not synchronized yet, so the release may be deferred past the destroy call:
cudaGraphExecDestroy(graphExec);
cudaStreamSynchronize(0);
// The final release, and the call to the destructor, are now queued if they have not already executed. This completes asynchronously.
The new graph debug API provides a fast and convenient way to gain high-level understanding of a given graph by creating a comprehensive overview of the entire graph, without you calling individual API actions like the following to compose the graph:
cudaGraphGetNodes
cudaGraphGetEdges
cudaGraphHostNodeGetParams
cudaGraphKernelNodeGetParams
The single cudaGraphDebugDotPrint API can construct a detailed view of any uninstantiated graph, demonstrating the topology, node geometry, attribute configurations, and parameter values. Given a CUDA graph, it outputs a DOT graph, where DOT is a graph description language. This detailed view of the graph makes it easier for you to identify obvious configuration issues and enables you to create easy-to-understand bug reports that can be used by others to analyze and debug the issue. Combining this API with a debugger increases the usefulness, by isolating issues to specific nodes.
cudaGraphDebugDotPrint(CUgraph hGraph, const char *path, unsigned int flags);
Stream-ordered memory allocator
One of the highlights of CUDA 11.2 was the stream-ordered CUDA memory allocator feature that enables applications to order memory allocation and deallocation with other work launched into a CUDA stream. It also enables sharing memory pools across entities within an application. For more information, see Enhancing Memory Allocation with New NVIDIA CUDA 11.2 Features.
In CUDA 11.3, we added new APIs to enhance this feature:
A pointer query to obtain the handle to the memory pool for those pointers obtained from an async allocator. cuPointerGetAttribute has the CU_POINTER_ATTRIBUTE_MEMPOOL_HANDLE attribute to retrieve the mempool corresponding to an allocation.
Device query to check if mempool-based inter-process communication (IPC) is supported for a particular mempool handle type. cuDeviceGetAttribute has an CU_DEVICE_ATTRIBUTE_MEMPOOL_SUPPORTED_HANDLE_TYPES attribute
Query mempool usage statistics that provide a way to obtain allocated memory details. cuMemPool has attributes such as the amount of physical memory currently allocated to the pool. The sum of sizes of allocations that have not been freed can be queried using the cudaMemPoolGetAttribute API.
CUDA 11.3 formally supports virtual aliasing, a process where an application accesses two different virtual addresses, but they end up referencing the same physical allocation, creating a synonym in the memory address space. The CUDA programming model has been updated to provide guidelines and guarantees for this previously undefined behavior. The Virtual Memory Management APIs provide a way to create multiple virtual memory mappings to the same allocation using multiple calls to cuMemMap with different virtual addresses, that is, virtual aliasing.
CUDA 11.3 also introduces a new driver and runtime API to query memory addresses for driver API functions. Previously, there was no direct way to obtain function pointers to the CUDA driver symbols. To do so, you had to call into dlopen, dlsym, or GetProcAddress. This feature implements a new driver API, cuGetProcAddress, and the corresponding new runtime API cudaGetDriverEntryPoint.
This enables you to use the runtime API to call into driver APIs like cuCtxCreate and cuModuleLoad that do not have a runtime wrapper. It also enables access to new CUDA features with the newer driver on older toolkits or requesting for a per-thread default stream version of a CUDA driver function. For more information, see CUDA Driver API andDriver Entry Point Access.
Language extensions: CUDA
We continue to enrich and extend the CUDA software environment through extensions to industry-standard programming languages. More recently, we’ve added enhancements to C++ and CUDA Python to help simplify the developer experience.
C++ support enhancements
NVIDIA C++ Standard Library (libcu++) is the C++ Standard Library for your entire system that is shipped with the CUDA toolkit. It provides a heterogeneous implementation of the C++ Standard Library that can be used in and between CPU and GPU code. It is an open-source project available on GitHub. A new version of libcu++ 1.4.1 is being released with the CUDA 11.3 toolkit release.
The CUDA 11.3 toolkit release also includes CUB 1.11.0 and Thrust 1.11.0, which are major releases providing bug fixes and performance enhancements. CUB 1.11.0 includes a new DeviceRadixSort backend that improves performance by up to 2x on supported keys and hardware. Thrust 1.11.0 includes a new sort algorithm that provides up to 2x more performance from thrust::sort when used with certain key types and hardware. The new thrust::shuffle algorithm has been tweaked to improve the randomness of the output. For more information, see CUB and Thrust.
Python support (preview release on GitHub)
NVIDIA is excited by the vast developer community demand for support of the Python programming language. Python plays a key role within the science, engineering, data analytics, and deep learning application ecosystem. We’ve long been committed to helping the Python ecosystem use the accelerated computing performance of GPUs to deliver standardized libraries, tools, and applications. This is another step towards improved Python code portability and compatibility.
Our goal is to help unify the Python CUDA ecosystem with a single standard set of low-level interfaces, providing full coverage of and access to the CUDA host APIs from Python. We want to provide a foundation for the ecosystem to build on in unison, to allow interoperability amongst different accelerated libraries. Most importantly, we want to make it easy for you to use NVIDIA GPUs with Python:
Cython/Python wrappers for CUDA driver and Runtime APIs.
CUDA Python is a preview release on GitHub aligned with the CUDA 11.3 release.
The CUDA 11.3 release of the CUDA C++ compiler toolchain incorporates new features aimed at improving productivity and code performance:
cu++flt—A standalone demangler tool that allows you to decode mangled function names to aid source code correlation.
NVRTC shared library versioning scheme—Relaxed to facilitate compatible upgrades of the library within a CUDA major release sequence.
Built-in function alloca —Used to dynamically allocate dynamic memory out of the stack frame and now available for use in device code as a preview feature.
CUDA C++ language—Extended to enable the use of the constexpr and auto keywords in broader contexts.
CUDA device linker— Also extended, with options that can be used to dump the call graph for device code along with register usage information to facilitate performance analysis and tuning.
The NVIDIA Nsight toolset contains Nsight Systems, Nsight Compute, and Nsight Graphics to for better GPU profiling and performance optimizations. NVIDIA Nsight developer tools are seamlessly integrated into the software development environments for ease in execution and testing, with IDEs such as Microsoft Visual Studio and Eclipse.
Nsight VS Code is our latest addition to the series of toolsets. It is an extension to Visual Studio Code for CUDA-based applications. As VS Code is widely adopted by the developer community, Nsight VS Code supports the latest features.
Nsight Systems 2021.2 introduces support for GPU metrics sampling. These metrics chart an overview of GPU efficiency over time within compute, graphics, and IO activities:
IO throughputs: PCIe, NVLink, and memory bandwidth
SM utilization: SMs active, Tensor Core activity, instructions issued, warp occupancy, and unassigned warp slots
This expands Nsight Systems existing ability to profile system-wide activity to help you in the investigative work of tracking GPU workloads back to their CPU origins. It provides a deeper understanding of the GPU utilization levels and the combined effect of multiple processes.
Nsight Compute 2021.1 adds a new NVLink topology and properties, OptiX 7 API stepping, MacOS 11 Big Sur host support, and improved resource tracking capabilities for user objects, stream capture, and asynchronous sub allocations. These new features give you increased visibility into the dynamic performance behavior of your workloads and how you are using hardware and software resources.
For more information, see the following resources:

 University of Pennsylvania researchers have used convolutional neural networks to catalog the morphology of 27 million galaxies, giving astronomers a massive dataset for studying the evolution of the universe.
University of Pennsylvania researchers have used convolutional neural networks to catalog the morphology of 27 million galaxies, giving astronomers a massive dataset for studying the evolution of the universe. 


 CUDA is the software development platform for building GPU-accelerated applications, providing all the components you need to develop applications that use NVIDIA GPUs. CUDA is ideal for diverse workloads from high performance computing, data science analytics, and AI applications. The latest release, CUDA 11.3, and its features are focused on enhancing the programming model and …
CUDA is the software development platform for building GPU-accelerated applications, providing all the components you need to develop applications that use NVIDIA GPUs. CUDA is ideal for diverse workloads from high performance computing, data science analytics, and AI applications. The latest release, CUDA 11.3, and its features are focused on enhancing the programming model and …