GFN Thursday is our ongoing commitment to bringing great PC games and service updates to our members each week. Every Thursday, we share updates on what’s new in the cloud — games, exclusive features, and news on GeForce NOW. This week, it includes the latest updates for two popular games: Fatshark’s free expansion Warhammer: Vermintide Read article >
When a community embraces sustainability, it can reap multiple benefits: gainful employment for vulnerable populations, more resilient local ecosystems and a cleaner environment. This Earth Day, we’re announcing our four latest corporate social responsibility investments in India, home to more than 2,700 NVIDIANs. These initiatives are part of our multi-year efforts in the country, which Read article >
In this course I will teach you 8 agents including:
· Space Invaders Agent using Keras-RL
· Autonomous Taxi using Q-Learning built from scratch
· Flappy Bird Agent using Deep Q Network that we build from scratch
· Mario Agent using Deep Q Network that we build from scratch
· A reinforcement Learning S&P 500 stock trading agent that is rewarded with making money off the stock market!
· Another Reinforcement Learning Stock Trading Agent using 89 different Technical indicators (you can pair these to make a lot of money off the stock market 😉)
· 3 Car agents that learn to maneuver roundabouts, parking lots, & merge onto a highway
The only thing you need to know is Python! If you are interested in cutting edge technology, then this is the course for you! Check it out!
NVIDIA today announced that its AI inference platform, newly expanded with NVIDIA® A30 and A10 GPUs for mainstream servers, has achieved record-setting performance across every category on the latest release of MLPerf.
NVIDIA DRIVE-powered cars electrified the atmosphere this week at Auto Shanghai. The global auto show is the oldest in China and has become the stage to debut the latest vehicles. And this year, automakers, suppliers and startups developing on NVIDIA DRIVE brought a new energy to the event with a wave of intelligent electric vehicles Read article >
Inference is where we interact with AI. Chat bots, digital assistants, recommendation engines, fraud protection services, and other applications that you use every day—all are powered by AI. Those deployed applications use inference to get you the information that you need. Given the wide array of usages for AI inference, evaluating performance poses numerous challenges … Continued
Inference is where we interact with AI. Chat bots, digital assistants, recommendation engines, fraud protection services, and other applications that you use every day—all are powered by AI. Those deployed applications use inference to get you the information that you need.
Given the wide array of usages for AI inference, evaluating performance poses numerous challenges for developers and infrastructure managers. Industry-standard benchmarks have long played a critical role in that evaluation process. For AI inference on data center, edge, and mobile platforms, MLPerf Inference 1.0 measures performance across computer vision, medical imaging, natural language, and recommender systems. These benchmarks were developed by a consortium of AI industry leaders. They provide the most comprehensive set of performance data available today, both for AI training and inference.
Version 1.0 of MLPerf Inference introduces some incremental but important new features. These include tests to measure power and energy efficiency and increasing test runtimes from 1 minute to 10 to better exercise the unit under test.
To perform well on the wide test array in this benchmark, it takes a full-stack platform with great ecosystem support, both for frameworks and networks. NVIDIA was the only company to make submissions for all data center and edge tests and deliver the best performance on all. One of the great byproducts of this work is that many of these optimizations found their way into inference developer tools like TensorRT and Triton.
In this post, we step through some of these optimizations, including the use of Triton Inference Server and the A100 Multi-Instance GPU (MIG) feature.
MLPerf 1.0 results
This round of MLPerf Inference saw the debut of two new GPUs from NVIDIA: A10 and A30. These mainstream GPUs join the flagship NVIDIA A100 GPU, and each has a particular role to play in the portfolio. A10 is designed for AI and visual computing and A30 is designed for AI and compute workloads. The following chart shows the Data Center scenario submissions:
Figure 1. MLPerf Inference 1.0 Data Center scenario performance.
In the Edge scenario, NVIDIA again delivered leadership performance across the board.
AI training generally requires precisions like FP32, TF32, or mixed precision (FP16/FP32). However, inference can often use reduced precision to achieve better performance and lower latency while preserving required accuracy. Nearly all NVIDIA submissions used INT8 accuracy. In the case of the RNN-T speech-to-text model, we converted the encoder LSTM cell to INT8. Previously, in v0.7, we used FP16. We also made several other optimizations to make best use of the IMMA (INT8 using Tensor Cores) instructions across different workloads.
Layer fusion is another optimization technique where the math operations from multiple network layers are combined to reduce computational load to achieve the same or better result. We used layer fusion to improve performance on the 3D-UNet medical imaging workload, combining deconvolution and concatenation operations into a single kernel.
Triton
As with the previous round, we made many submissions using Triton Inference Server, which simplifies deployment of AI models at scale in production. This open-source inference serving software lets you deploy trained AI models from any framework on any GPU– or CPU-based infrastructure: cloud, data center, or edge. You can use a variety of possible inference backends, including TensorRT for NVIDIA GPU and OpenVINO for Intel CPU.
In this round, the team made several optimizations that are available from the triton-inference-server GitHub repo. These include a multithreaded gather kernel to prepare the input for inference as well as using pinned CPU memory for I/O buffers to speed data movement to the GPU. Using the Triton integrated auto-batching support, the Triton-based GPU submissions achieved an average of 95% of the performance of the server scenario submissions, using custom auto-batching code.
Another great Triton feature is that it can run CPU-based inference. To demonstrate those capabilities, we made several CPU-only submissions using Triton. On data center submissions in the offline and server scenarios, Triton’s CPU submissions achieved an average of 99% of the performance of the comparable CPU submission. You can use the same inference serving software to host both GPU– and CPU-based applications. When you transition applications from CPU to GPU, you can stay on the same software platform, with only a few changes to a config file to complete the change.
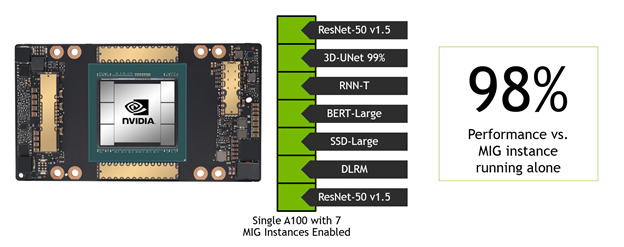
MIG goes big
For this round, the team made two novel submissions to demonstrate MIG performance and versatility. A key metric for infrastructure management is overall server utilization, which includes its accelerators. A typical target value is around 80%, which gets the most out of every server while allowing some headroom to handle compute demand spikes. A100 GPUs often have much more compute capacity than a single inference workload requires. Having the MIG feature to partition the GPU into right-sized instances allows you to host multiple networks on a single GPU.
Figure 3. Single A100 with MIG runs all MLPerf tests at the same time, with 98% performance of a single MIG instance.
The team built a MIG submission where one network’s performance was measured in a single MIG instance. Simultaneously, the other MLPerf Data Center workloads were running in the other six MIG instances. In other words, a single A100 was running the entire Data Center benchmark suite at the same time. The team repeated this for all six Data Center networks. For the network being measured, the submission showed that, on average, the network under test achieved 98% of the performance of that single MIG instance if the other six instances were idle.
MLPerf Inference drives innovation
Many of the optimizations used to achieve the winning results are available today in TensorRT, Triton Inference Server, and the MLPerf Inference GitHub repo. This round of testing debuted two new GPUs: the NVIDIA A10 and A30. It further demonstrated the great capabilities of Triton and the MIG feature. These allow you to deploy trained networks on GPUs and CPUs easily. At the same time, you’re provisioning the right-sized amount of AI acceleration for a given application and maximizing the utility of every data center processor.
In addition to the direct submissions by NVIDIA, eight partners—including Alibaba, Dell EMC, Fujitsu, Gigabyte, HPE, Inspur, Lenovo, Supermicro—also submitted using NVIDIA GPU-accelerated platforms, for over half of the total submissions. All software used for NVIDIA submissions is available from the MLPerf repo, NVIDIA GitHub repo, and NGC, the NVIDIA hub for GPU-optimized software for deep learning, machine learning, and high-performance computing.
These MLPerf Inference 1.0 results bring up to 46% more performance than the previous MLPerf 0.7 submission six months ago. They further reinforce the NVIDIA AI platform as not only the clear performance leader, but also the most versatile platform for running every kind of network: on-premises, in the cloud, or at the edge. As networks and data sets continue to grow rapidly and as real-time services continue to use AI, inference acceleration has become a must-have for applications to realize their full potential.
Posted by Huiyu Wang, Student Researcher and Liang-Chieh Chen, Research Scientist, Google Research
Panoptic segmentation is a computer vision task that unifies semantic segmentation (assigning a class label to each pixel) and instance segmentation (detecting and segmenting each object instance). A core task for real-world applications, panoptic segmentation predicts a set of non-overlapping masks along with their corresponding class labels (i.e., category of object, like “car”, “traffic light”, “road”, etc.) and is generally accomplished using multiple surrogate sub-tasks that approximate (e.g., by using box detection methods) the goals of panoptic segmentation.
An example image and its panoptic segmentation masks from the Cityscapes dataset.
Previous methods approximate panoptic segmentation with a tree of surrogate sub-tasks.
Each surrogate sub-task in this proxy tree introduces extra manually-designed modules, such as anchor design rules, box assignment rules, non-maximum suppression (NMS), thing-stuff merging, etc. Although there are good solutions to individual surrogate sub-tasks and modules, undesired artifacts are introduced when these sub-tasks come together in a pipeline for panoptic segmentation, especially in challenging conditions (e.g., two people with similar bounding boxes will trigger NMS, resulting in a missing mask).
Previous efforts, such as DETR, attempted to solve some of these issues by simplifying the box detection sub-task into an end-to-end operation, which is more computationally efficient and results in fewer undesired artifacts. However, the training process still relies heavily on box detection, which does not align with the mask-based definition of panoptic segmentation. Another line of work completely removes boxes from the pipeline, which has the benefit of removing an entire surrogate sub-task along with its associated modules and artifacts. For example, Axial-DeepLab predicts pixel-wise offsets to predefined instance centers, but the surrogate sub-task it uses encounters challenges with highly deformable objects, which have a large variety of shapes (e.g., a cat), or nearby objects with close centers in the image plane, e.g. the image below of a dog seated in a chair.
When the centers of the dog and the chair are close to each other, Axial-DeepLab merges them into one object.
In “MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers”, to be presented at CVPR 2021, we propose the first fully end-to-end approach for the panoptic segmentation pipeline, directly predicting class-labeled masks by extending the Transformer architecture to this computer vision task. Dubbed MaX-DeepLab for extending Axial-DeepLab with a Mask Xformer, our method employs a dual-path architecture that introduces a global memory path, allowing for direct communication with any convolution layers. As a result, MaX-DeepLab shows a significant 7.1% panoptic quality (PQ) gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. MaX-DeepLab achieves the state-of-the-art 51.3% PQ on COCO test-dev set, without test time augmentation.
MaX-DeepLab is fully end-to-end: It predicts panoptic segmentation masks directly from images.
End-to-End Panoptic Segmentation Inspired by DETR, our model directly predicts a set of non-overlapping masks and their corresponding semantic labels, with output masks and classes that are optimized with a PQ-style objective. Specifically, inspired by the evaluation metric, PQ, which is defined as the recognition quality (whether or not the predicted class is correct) times the segmentation quality (whether the predicted mask is correct), we define a similarity metric between two class-labeled masks in the exact same way. The model is directly trained by maximizing this similarity between ground truth masks and predicted masks via one-to-one matching. This direct modeling of panoptic segmentation enables end-to-end training and inference, removing the hand-coded priors that are necessary in existing box-based and box-free methods.
MaX-DeepLab directly predicts N masks and N classes with a CNN and a mask transformer.
Dual-Path Transformer Instead of stacking a traditional transformer on top of a convolutional neural network (CNN), we propose a dual-path framework for combining CNNs with transformers. Specifically, we enable any CNN layer to read and write to global memory by using a dual-path transformer block. This proposed block adopts all four types of attention between the CNN-path and the memory-path, and can be inserted anywhere in a CNN, enabling communication with the global memory at any layer. MaX-DeepLab also employs a stacked-hourglass-style decoder that aggregates multi-scale features into a high resolution output. The output is then multiplied with the global memory feature, to form the mask set prediction. The classes for the masks are predicted with another branch of the mask transformer.
An overview of the dual-path transformer architecture.
Results We evaluate MaX-DeepLab on one of the most challenging panoptic segmentation datasets, COCO, against both of the state-of-the-art box-free (Axial-DeepLab) and box-based (DetectoRS) methods. MaX-DeepLab, without test time augmentation, achieves the state-of-the-art result of 51.3% PQ on the test-dev set.
Comparison on COCO test-dev set.
This result surpasses Axial-DeepLab by 7.1% PQ in the box-free regime and DetectoRS by 1.7% PQ, bridging the gap between box-based and box-free methods for the first time. For a consistent comparison with DETR, we also evaluated a lightweight version of MaX-DeepLab that matches the number of parameters and computations of DETR. The lightweight MaX-DeepLab outperforms DETR by 3.3% PQ on the val set and 3.0% PQ on the test-dev set. In addition, we performed extensive ablation studies and analyses on our end-to-end formulation, model scaling, dual-path architectures, and loss functions. Also the extra-long training schedule of DETR is not necessary for MaX-DeepLab.
As an example in the figure below, MaX-DeepLab correctly segments a dog sitting on a chair. Axial-DeepLab relies on a surrogate sub-task of regressing object center offsets. It fails because the centers of the dog and the chair are close to each other. DetectoRS classifies object bounding boxes, instead of masks, as a surrogate sub-task. It filters out the chair mask because the chair bounding box has a low confidence.
A case study for MaX-DeepLab and state-of-the-art box-free and box-based methods.
Another example shows how MaX-DeepLab correctly segments images with challenging conditions.
MaX-DeepLab correctly segments the overlapping zebras. This case is also challenging for other methods since the zebras have similar bounding boxes and nearby object centers. (credit & license)
Conclusion We have shown for the first time that panoptic segmentation can be trained end-to-end. MaX-DeepLab directly predicts masks and classes with a mask transformer, removing the need for many hand-designed priors such as object bounding boxes, thing-stuff merging, etc. Equipped with a PQ-style loss and a dual-path transformer, MaX-DeepLab achieves the state-of-the-art result on the challenging COCO dataset, closing the gap between box-based and box-free methods.
Acknowledgements We are thankful to our co-authors, Yukun Zhu, Hartwig Adam, and Alan Yuille. We also thank Maxwell Collins, Sergey Ioffe, Jiquan Ngiam, Siyuan Qiao, Chen Wei, Jieneng Chen, and the Mobile Vision team for the support and valuable discussions.
As AI is increasingly established as a world-changing field, the U.S. has an opportunity not only to demonstrate global leadership, but to establish a solid economic foundation for the future of the technology. A panel of experts convened last week at GTC to shed light on this topic, with the co-chairs of the Congressional AI Read article >
Overview cuCIM is a new RAPIDS library for accelerated n-dimensional image processing and image I/O. The project is now publicly available under a permissive license (Apache 2.0) and welcomes community contributions. In this post, we will cover the overall motivation behind the library and some initial benchmark results. In a complementary post on the Quansight … Continued
Overview
cuCIM is a new RAPIDS library for accelerated n-dimensional image processing and image I/O. The project is now publicly available under a permissive license (Apache 2.0) and welcomes community contributions. In this post, we will cover the overall motivation behind the library and some initial benchmark results. In a complementary post on the Quansight blog, we provide guidelines on how existing CPU-based scikit-image code can be ported to the GPU. The library’s initial release was a collaboration between Quansight and the RAPIDS and Clara teams at NVIDIA.
Motivation
A primary objective of cuCIM is to provide open-source implementations of a wide range of CUDA-accelerated n-dimensional image processing operations that closely mirror the scikit-image API. Volumetric or general n-dimensional data is encountered in scientific fields such as bioimaging (microscopy), medical imaging (CT/PET/MRI), materials science, and remote sensing. This familiar, Pythonic API provides an accessible interface allowing researchers and data scientists to rapidly port existing CPU-based codes to the GPU.
Although a number of proprietary and open-source libraries provide GPU-accelerated 2D image processing operations (e.g. OpenCV, CUVI, VPI, NPP, DALI), these either lack 3D support or focus on a narrower range of operations than cuCIM. Popular n-dimensional image processing tools like scikit-image, SciPy’s ndimage module, and the Image Processing Toolkit (ITK and SimpleITK) have either no or minimal GPU support. The CLIJ library is an OpenCL-based 2D and 3D image processing library with some overlap in functionality with cuCIM. Although CLIJ is a Java-based project being developed among the ImageJ/Fiji community, the effort is underway to provide interfaces from Python and other languages (clEsperanto).
Aside from providing image processing functions, we also provide image/data readers designed to address the I/O bottlenecks commonly encountered in Deep Learning training scenarios. Both C++ and Python APIs for reading TIFF files with an API matching the OpenSlide library are provided, with support for additional image formats planned for future releases (e.g. DICOM, NIFTI, and the Zarr-based Next Generation File Format being developed by the Open Microscopy Environment (OME).
cuCIM Architecture
C++ Architecture and plugins
cuCIM consists of I/O, file system, and operation modules at its core layers. Image formats and operations on images supported by cuCIM can be extended through plugins. cuCIM’s plug-in architecture is based on NVIDIA Carbonite SDK which is a core engine of NVIDIA Omniverse applications.
The CuImage C++ class represents an image and its metadata. This CuImage class and functions in core modules such as TIFF loader and filesystem I/O using NVIDIA GPUDirect Storage (GDS — also known as cuFile) are also available from Python via the cucim.clara package
Pythonic image processing utilizing CuPy
The GPU-based implementation of the scikit-image API is provided in the cucim.skimage module. These functions have been implemented using the CuPy library. CuPy was chosen because it provides a GPU equivalent for most of NumPy and a substantial subset of SciPy (FFTs, sparse matrices, n-dimensional image processing primitives). By using technologies such as Thrust and CUB, efficient, templated sorting and reduction routines are available as well. For cases where custom CUDA kernels are needed, it also contains ElementwiseKernel and RawKernel classes that can be used to simplify the generation of the necessary kernels at run-time for the provided input data types.
Interoperability
Finally, CuPy supports both DLPack and the __cuda_array_interface__ protocols, making it possible to easily interoperate with other Python libraries with GPU support as Numba, PyCUDA, PyTorch, Tensorflow, JAX, and Dask. Other libraries in the RAPIDS ecosystem provide complementary functions covering areas such as machine learning (cuML), signal processing (cuSignal), or graph algorithms (cuGraph) that can be combined with cuCIM in applications. Additionally properties of ROIs (regions of interest) identified by an algorithm fit naturally in cuDF data-frames.
An example of using Dask to perform blockwise image processing was given in the following Dask deconvolution blog post, which illustrates distributed processing across multiple GPUs. Although the blog post was written prior to the release of cuCIM, the same approach of using Dask’s map_overlap function can be employed for many of the image processing operations in cuCIM. Blockwise processing (using map_blocks) can also be useful even with a single GPU in order to reduce peak GPU memory requirements.
Figure 1: Interoperability with Other Libraries/Frameworks.
Benchmarks
TIFF Image I/O
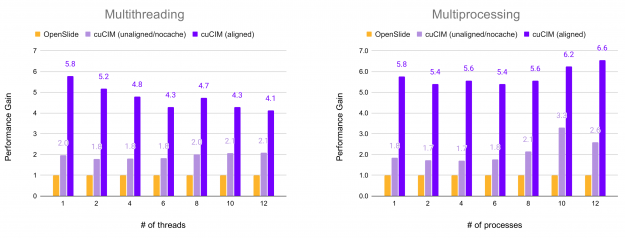
In the following figure, the relative performance for reading all non-overlapping (256, 256) patches from an RGB TIFF image of shape (81017, 92344, 3) on an SSD drive is shown. Performance is plotted in terms of acceleration factor relative to the OpenSlide library.
Figure 2: Performance – TIFF File Loading.
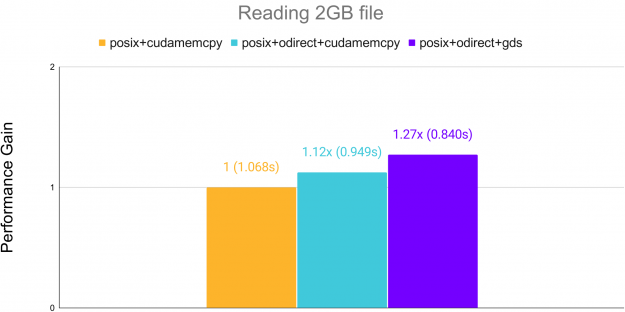
Additionally, reading raw binary data can see acceleration over standard cudaMemcpy when using GPUDirect Storage (GDS) on systems supporting it. GDS allows transfer directly from memory to the GPU, bypassing the CPU.
Figure 3: Performance – Reading File with GPUDirect Storage (GDS).
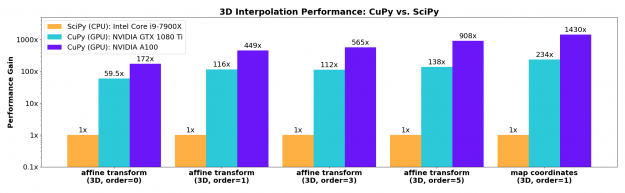
n-dimensional B-spline image interpolation
The necessary n-dimensional image interpolation routines needed to enable resizing, rotation, affine transforms, and warping were contributed upstream to CuPy’s cupyx.scipy.ndimage module. These implementations match the improved spline interpolation functions developed for SciPy 1.6 and support spline orders from 0-5 with a range of boundary conditions. These functions show excellent acceleration on the GPU, even for older generation gaming-class cards such as the NVIDIA GTX 1080-Ti.
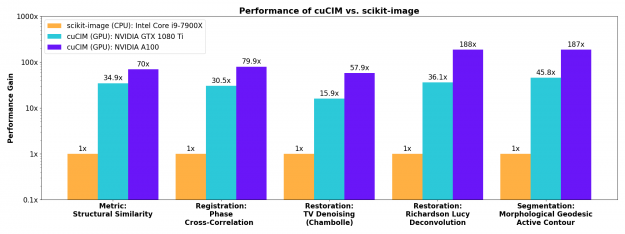
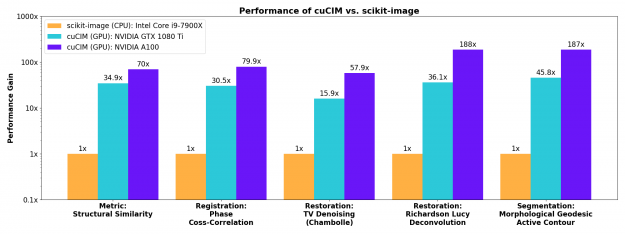
Image processing primitives such as filtering, morphology, color conversions, and labeling of connected components in binary images see substantial acceleration on the GPU. Performance numbers are in terms of acceleration factors relative to scikit-image 0.18.1 on the CPU.
The results shown here are for relatively large images (2D images at 4K resolution). For smaller images such as (512, 512), acceleration factors will be smaller but still substantial. For tiny images (e.g. (32, 32)), processing on the CPU will be faster as there is some overhead involved in launching CUDA kernels on the GPU and there will not be enough work to keep all GPU cores busy.
Higher-level operations
More involved image restoration, registration, and segmentation algorithms also see substantial acceleration on the GPU.
Please visit Quansight’s blog to learn more about converting your CPU-based code to the GPU with cuCIM, and some areas on our roadmap where we would love to hear your feedback.


 by Aurélien Géron. Is anybody else studying this book and interested in being part of a remote study group to complete it?")
 Inference is where we interact with AI. Chat bots, digital assistants, recommendation engines, fraud protection services, and other applications that you use every day—all are powered by AI. Those deployed applications use inference to get you the information that you need. Given the wide array of usages for AI inference, evaluating performance poses numerous challenges …
Inference is where we interact with AI. Chat bots, digital assistants, recommendation engines, fraud protection services, and other applications that you use every day—all are powered by AI. Those deployed applications use inference to get you the information that you need. Given the wide array of usages for AI inference, evaluating performance poses numerous challenges … 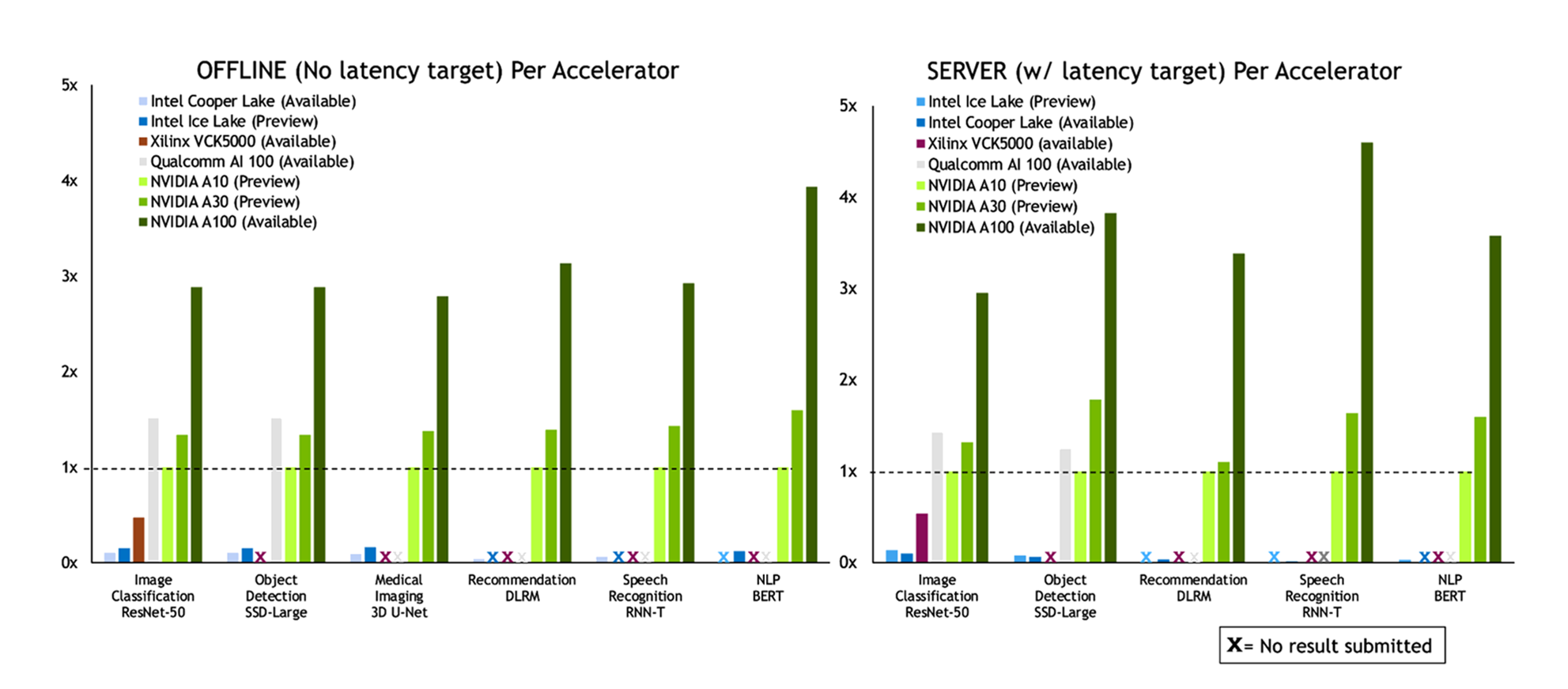










 Overview cuCIM is a new RAPIDS library for accelerated n-dimensional image processing and image I/O. The project is now publicly available under a permissive license (Apache 2.0) and welcomes community contributions. In this post, we will cover the overall motivation behind the library and some initial benchmark results. In a complementary post on the Quansight …
Overview cuCIM is a new RAPIDS library for accelerated n-dimensional image processing and image I/O. The project is now publicly available under a permissive license (Apache 2.0) and welcomes community contributions. In this post, we will cover the overall motivation behind the library and some initial benchmark results. In a complementary post on the Quansight … 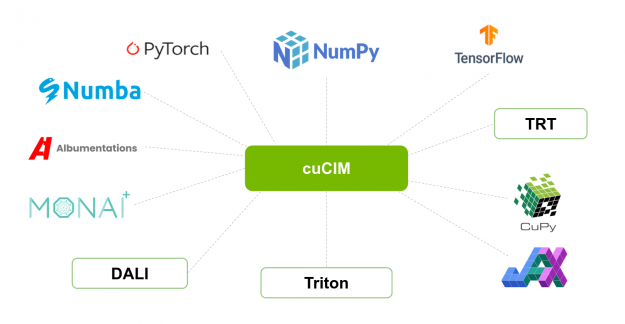
{kind=link}