NVIDIA announced the availability of cuSPARSELt version 0.1.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
Today, NVIDIA is announcing the availability of cuSPARSELt version 0.1.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
NVIDIA cuSPARSELt is a high-performance CUDA library dedicated to general matrix-matrix operations in which at least one operand is a sparse matrix:
In this formula, and refer to in-place operations such as transpose/non-transpose.
The cuSPARSELt APIs allow flexibility in the algorithm/operation selection, epilogue, and matrix characteristics, including memory layout, alignment, and data types.
There is a wide range of graph applications and algorithms that I hope to discuss through this series of blog posts, all with a bias toward what is in RAPIDS cuGraph. I am assuming that the reader has a basic understanding of graph theory and graph analytics. If there is interest in a graph analytic … Continued
This post was originally published on the RAPIDS AI Blog.
There is a wide range of graph applications and algorithms that I hope to discuss through this series of blog posts, all with a bias toward what is in RAPIDS cuGraph. I am assuming that the reader has a basic understanding of graph theory and graph analytics. If there is interest in a graph analytic primer, please leave me a comment below. It should also be noted that I approach graph analysis from a social network perspective and tend to use the social science theory and terms, but I have been trying to use ‘vertex’ rather than ‘node.’
Every RAPIDS cuGraph 0.7 release adds new features. Of interest to this discussion is the expansion of the Jaccard Similaritymetric to allow for comparisons of any pair of vertices, and the addition of the Overlap Coefficient algorithm. Those two algorithms fall into the category of similarity metrics and lead to the topic of this blog, which is to discuss the difference between the two algorithms and why I think one is better than the other. Let’s start with a quick introduction to the similarity metrics (warning math ahead).
The Jaccard Similarity, also called the Jaccard Index or Jaccard Similarity Coefficient, is a classic measure of similarity between two sets that was introduced by Paul Jaccard in 1901. Given two sets, A and B, the Jaccard Similarity is defined as the size of the intersection of set A and set B (i.e. the number of common elements) over the size of the union of set A and set B (i.e. the number of unique elements).
Figure 1. The Jaccard Similarity Metric.
The Overlap Coefficient, also known as the Szymkiewicz–Simpson coefficient, is defined as the size of the union of set A and set B over the size of the smaller set between A and B.
Figure 2. The Overlap Coefficient Metric.
When applying either of the similarity metrics in a graph setting, the sets are typically comprised of the neighbors of the vertex pair being compared. The neighbors of a vertex v, in a graph (V,E) is defined as the set, U, of vertices connected by way of an edge to vertex v, or N(v) = {U} where v ∈V and ∀ u ∈ U ∃ edge(v,u) ∈ E. Computing the size of the union, | A U B |, can be computationally inexpensive since we only want the size and not the actual elements. The size of the union| A U B | can be computed with |A| + |B| — | A intersect B |.
Figure 3. Efficient Jaccard Computation.
There is a wide range of applications for similarity scoring and it is important to cover a few of them before getting into comparing the two algorithms. Let’s start with something that I’m sure a lot of the reader are familiar with, and that is recommending people to connect with on social media. What I am going to present is a very simplistic approach to the problem — most social networking sites use a much more advanced version that usually includes some type of community detection. But first, even more background …
Figure 4: Triadic Closure.
Within the field of social network analysis, there is the concept of Triadic Closure, which was first introduced by sociologists Georg Simmel in 1908. Given three people, A, B, and C, see Figure 1; if A and C are friends (connected), and B and C are friends, then there is a high probability that A and B will connect. That probability is so high that Granovetter, in his 1973 work on weak-ties, deemed the missing link as the “forbidden triad”, which meant that for Granovetter’s application that you could infer a connection between A and B. For our recommendation application, this means that we need to find those unconnected A — B pairs since there is a high change that those users will become friends — it is always good to recommend something that the user will accept.
Now back to the application: the basic process starts by first computing the similarity metric (Jaccard or Overlap Coefficient) for all vertex pairs connected by an edge. Then for a given vertex (example, vertex A) find their neighbors with the highest similar score and recommend neighbors of B that are missing from A. As mentioned, this is a very simple view since there is a range of options for applying additional weights, like only looking within community clusters, that could be added to better select recommendations that will be accepted. The application of triadic closure and similarity should be apparent to anyone that uses social media since those tools remind you constantly that you should connect to a friend of friends. Note that this approach does not work for vertices with a single connection, also called a satellite, since their similarity score will be zero. But for satellites it is easy to just recommend all connections from their sole neighbor.
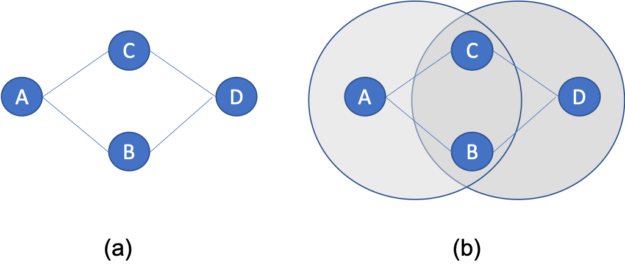
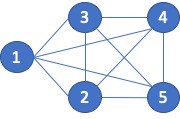
The problem with the previous approach is that not all recommendations can come from solely looking at directly connected vertex pairs. Therefore, being able to compute similarity scores between any pair of vertices is important. This was a limitation of the initial cuGraph Jaccard implementation and what has been addressed in cuGraph release 0.7. Consider figure 2 below. Looking at the Jaccard similarity score between connected vertices A and B, the neighbors of A are {B, C}, and for B are {A, D}. Hence the Jaccard score is js(A, B) = 0 / 4 = 0.0. Even the Overlap Coefficient yields a similarity of zero since the size of the intersection is zero. Now looking at the similarity between A and D, where both share the exact same set of neighbors. The Jaccard Similarity between A and D is 2/2 or 1.0 (100%), likewise the Overlap Coefficient is 1.0 size in this case the union size is the same as the minimal set size.
Figure 5: Non-connected Vertex Pair Similarity.
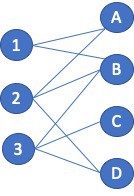
Figure 6: Bipartite Graph.
Continuing with the social network recommender example, the application should recommend that vertices A and D connect since they share the same set of neighbors. But non-connected vertex pair similarity is used in other applications as well. Consider a product recommendation system that is using a bipartite graph. One vertex type is Users and the other type is Product. The goal is to not find similarities between Users and Products as that is a different analytic but to find similarities between Users and other Users so that additional products can be recommended. The process is similar to that mentioned above; the vertices being compared are just not directly connected. Looking at the example figure (Figure 3) and focusing on User 1. User 1 neighbors are {A, B}, User 2 are {A, B, D} , and User 3 is {B. D}. The Jaccard Similarity in this case is 1-to-2 = 2 / 3 = 0.66, and between 1 and 3 = 1 / 3 = 0.33. Since User 1 and 2 both purchased products A and B, the application should recommend to User 1 that they also purchase product D.
Why I prefer the overlap coefficient
If the Jaccard similarity score is so useful, why introduce the Overlap Coefficient in cuGraph? Let’s look at the same example but using the Overlap Coefficient. Comparing User 1 to User 2 = 2 /2 = 1.0. And comparing User 1 to User 3 = 1 /2 = 0.5. The similarity between User 1 and User 2 is still the highest, but the fact the score is 1.0 indicated that the set of neighbors of User A is a complete subset of User 2. That type of insight is one of the benefits of the Overlap Coefficient.
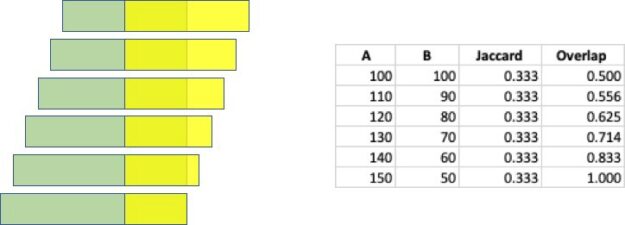
In my opinion, the Jaccard Similarity is a very powerful analysis technique, but it has a major drawback when the two sets being compared have different sizes. Consider two sets, A and B, where both sets contain 100 elements. Now assume that 50 of those elements are common across the two sets. The Jaccard Similarity is js(A, B) = 50 / (100 + 100 – 50 ) = 0.33. Now if we increase set A by 10 elements and decrease set B by the same amount, all while maintaining 50 elements in common, the Jaccard Similarity remains the same. And there is where I think Jaccard fails: it has no sensitivity to the sizes of the sets. The following figure highlights how the Jaccard and Overlap Coefficient change as the set sizes are change but the intersection size remains that same.
Figure 7: Similarity Scores as Set Sizes Change.
The use of the smaller set size as the denominator makes it so that the score provides an indication of how much of the smaller set is within the larger. That provides insight into whether one set is an exact subset of the larger set. Look back at the example described above, and illustrated above, using the Overlap Coefficient it is easy to see to what degree set B is contained within set A.
Conclusion
Jaccard might be better known than the Overlap Coefficient and that might play into why Jaccard is more widely used. The unfamiliarity with Overlap Coefficient might explain why it is not in the NetworkX package. Nevertheless, in my opinion, the Overlap Coefficient can provide better insight into how similar two vertices are — really, how similar the set of neighbors are. By knowing the sizes of each set, an analyst can easily know if one set is a proper subset (full contained) in the other set, which is something that is not apparent using Jaccard.
I also think there is a fundamental flaw in how we derive the set for similarity computation when the vertex pairs are connected by an edge. Consider the 5-clique shown below, figure 5. Since every vertex is connected to every other vertex, I (you) would assume that the similarity scores would be 1.0, exact similarity. However, because of the way the sets are created, for both Jaccard and the Overlap Coefficient, the score for vertex pairs connected by an edge can never be equal to 1.0.
Figure 8: Five Clique.
Let’s compare vertex 1 to vertex 2. The neighbors of 1 are {2, 3, 4, 5} and the neighbors of 2 are {1, 3, 4, 5}. The Jaccard score is then: 3 / 5 or 0.6. The Overlap Coefficient is 3 /4 or 0.75.
While those similarity scores are mathematically correct according to the algorithm, the resulting similarity score do not match what I would except for a clique. The issue is that the vertex pairs being compared are reflected in the neighborhood sets. Rephrasing that statement, vertex 1 appears in vertex 2’s neighbor set. Likewise, vertex 2 appears in vertex 1’s neighbor. The fact that the vertices being compared appear in the associative set prevents the sets from ever matching. In my opinion, the vertices being compared should not be part of the sets being evaluated.
A solution to this problem would be to build the sets differently or modify the similarity algorithm. The algorithm modification might be computationally easier. The change would be to subtract 1 from the size of each set on the union, not the intersection.
Figure 9: Modified Jaccard and Overlap Coefficient for Connected Vertex Pairs.
For the clique example, the similarity scores would then be:
js(1, 2) = 3 / (5–2) = 3/3 = 1.0. and
oc(1, 2) = 3 / (4–1) — 3/3 = 1.0.
Now, it could be that the results are correct and that my expectation are wrong. But this is just my opinion 🙂
About me
Brad Rees leads the RAPIDS cuGraph team at NVIDIA where he directs and develops graph analytic solutions. He has been designing, implementing, and supporting a variety of advanced software and hardware systems for over 30 years. Brad specializes in complex analytic systems, primarily using graph analytic techniques for social and cyber network analysis, and has been working on variety of advanced software and hardware systems for over 30 years. His technical interests are in HPC, machine learning, deep learning, and graph. Brad has a Ph.D. in Computer Science from the Florida Institute of Technology.
Some references
M. S. Granovetter, “The strength of weak ties,” The American Journal of Sociology, vol. 78, no. 6, pp. 1360–1380, 1973.
Posted by Manfred Ernst and Bartlomiej Wronski, Software Engineers, Google Research
We’re continuously working to improve the Pixel — making it more helpful, more capable, and more fun — with regular updates, such as the recent V8.2 update to the Camera app. One such improvement (launched on Pixel 5 and Pixel 4a 5G in October) is a feature that operates “under the hood”, HDR+ with Bracketing. This feature works by merging images taken with different exposure times to improve image quality (especially in shadows), resulting in more natural colors, improved details and texture, and reduced noise.
Why Are HDR Scenes Hard to Capture? The original HDR+ burst photography system is the engine behind high-quality mobile photography, which captures a rapid series of deliberately underexposed images, then combines and renders them in a way that preserves detail across the range of tones. But this system had one limitation: scenes with high dynamic range (HDR) like the one below were noisy in the shadows because all images captured are underexposed.
The same photo using HDR+ (red outline) and HDR+ with Bracketing (green outline). While the characteristic HDR+ look remains the same, bracketing improves image quality, especially in shadows, with more natural colors, improved details and texture, and reduced noise.
Capturing HDR scenes is difficult because of the physical constraints of image sensors combined with limited signal in the shadows. We can correctly expose either the shadows or the highlights, but not both at the same time.
The same scene shot with different exposure settings and tonemapped to similar overall brightness. Left/Top: Exposure set for the highlights. The bright blue sky is preserved, but the shadows are very noisy. Right/Bottom: Exposure set for the shadows. Noise in the shadows is reduced, but the sky is clipped (white).
Photographers sometimes work around these limitations by taking two different exposures and combining them. This approach, known as exposure bracketing, can deliver the best of both worlds, but it is time-consuming to do by hand. It is also challenging in computational photography because it requires:
Capturing additional long exposure frames while maintaining the fast, predictable capture experience of the Pixel camera.
Taking advantage of long exposure frames while avoiding ghosting artifacts caused by motion between frames.
To avoid these challenges, the original HDR+ system used a different approach to handle high dynamic range scenes.
The Limits of HDR+ The capture strategy used by HDR+ is based on underexposure, which avoids loss of detail in the highlights. While this strategy comes at the expense of noise in the shadows, HDR+ offsets the increased noise through the use of burst photography.
Using bursts to improve image quality. HDR+ starts from a burst of full-resolution raw images (left). Depending on conditions, between 2 and 15 images are aligned and merged into a computational raw image (middle). The merged image has reduced noise and increased dynamic range, leading to a higher quality final result (right).
This approach works well for scenes with moderate dynamic range, but breaks down for HDR scenes. To understand why, we need to take a closer look at how two types of noise get into an image.
Noise in Burst Photography One important type of noise is called shot noise, which depends only on the total amount of light captured — the sum of N frames, each with E seconds of exposure time has the same amount of shot noise as a single frame exposed for N × E seconds. If this were the only type of noise present in captured images, burst photography would be as efficient as taking longer exposures. Unfortunately, a second type of noise, read noise, is introduced by the sensor every time a frame is captured. Read noise doesn’t depend on the amount of light captured but instead depends on the number of frames taken — that is, with each frame taken, an additional fixed amount of read noise is added.
This is why using burst photography to reduce total noise isn’t as efficient as simply taking longer exposures: taking multiple frames can reduce the effect of shot noise, but will also increase read noise. Even though read noise increases with the number of frames, it is still possible to reduce the overall noisiness with burst photography, but it becomes less efficient. If one were to break a long exposure into N shorter exposures, the ratio of signal to noise in the final image would be lower because of the additional read noise. In this case, to get back to the signal-to-noise ratio in the single long exposure, one would need to merge N2 short-exposure frames. In the example below, if a long exposure were divided into 12 short exposures, we’d have to capture 144 (12 × 12) short frames to match the signal-to-noise ratio in the shadows! Capturing and processing this many frames would be much more time consuming — burst capture and processing could take over a minute and result in a poor user experience. Instead, with bracketing one can capture both short and long exposures — combining highlight protection and noise reduction.
Left: The result of merging 12 short-exposure frames in Night Sight mode. Right: A single frame whose exposure time is 12 times longer than an individual short exposure. The longer exposure has significantly less noise in the shadows but sacrifices the highlights.
Solving with Bracketing While the challenges of bracketing prevented the original HDR+ system from using it, incremental improvements since then, plus a recent concentrated effort, have made it possible in the Camera app. To start, adding bracketing to HDR+ required redesigning the capture strategy. Capturing is complicated by zero shutter lag (ZSL), which underpins the fast capture experience on Pixel. With ZSL, the frames displayed in the viewfinder before the shutter press are the frames we use for HDR+ burst merging. For bracketing, we capture an additional long exposure frame after the shutter press, which is not shown in the viewfinder. Note that holding the camera still for half a second after the shutter press to accommodate the long exposure can help improve image quality, even with a typical amount of handshake.
Capture strategy. Top: The original HDR+ method captures short exposures before the shutter press, six in this example. Bottom: HDR+ with Bracketing captures five short exposures before the shutter press and one long exposure after the shutter press.
For Night Sight, the capture strategy isn’t constrained by the viewfinder — because all frames are captured after the shutter press while the viewfinder is stopped, this mode easily accommodates capturing longer exposure frames. In this case, we capture three long exposures to further reduce noise.
Capture strategy for Night Sight. Top: The original Night Sight captured 15 short exposure frames. Bottom: Night Sight with bracketing captures 12 short and 3 long exposures.
The Merging Algorithm When merging bracketed shots, we choose one of the short frames as the reference frame to avoid potentially clipped highlights and motion blur. All other frames are aligned to this frame before they are merged. This introduces a challenge — for complex scene motion or occluded regions, it is impossible to find exactly matching regions and a naïve merge algorithm would produce ghosting artifacts in these cases.
Left: Ghosting artifacts are visible around the silhouette of a moving person, when deghosting is disabled. Right: Robust merging produces a clean image.
To address this, we designed a new spatial merge algorithm, similar to the one used for Super Res Zoom, that decides per pixel whether image content should be merged or not. This deghosting is more complicated for frames with different exposures. Long exposure frames have different noise characteristics, clipped highlights, and different amounts of motion blur, which makes comparisons with the short exposure reference frame more difficult. In addition, ghosting artifacts are more visible in bracketed shots, because noise that would otherwise mask these errors is reduced. Despite those challenges, our algorithm is as robust to these issues as the original HDR+ and Super Res Zoom and doesn’t produce ghosting artifacts. At the same time, it merges images 40% faster than its predecessors. Because it merges RAW images early in the photographic pipeline, we were able to achieve all of those benefits while keeping the rest of processing and the signature HDR+ look unchanged. Furthermore, users who prefer to use computational RAW images can take advantage of those image quality and performance improvements.
Bracketing on Pixel HDR+ with Bracketing is available to users of Pixel 4a (5G) and 5 in the default camera, as well as in Night Sight and Portrait modes. For users of Pixel 4 and 4a, the Google Camera app supports bracketing in Night Sight mode. No user interaction is needed to activate HDR+ with Bracketing — depending on the dynamic range of the scene, and the presence of motion, HDR+ with bracketing chooses the best exposures to maximize image quality (examples).
Acknowledgements HDR+ with Bracketing is the result of a collaboration across several teams at Google. The project would not have been possible without the joint efforts of Sam Hasinoff, Dillon Sharlet, Kiran Murthy, Mike Milne, Andy Radin, Nicholas Wilson, Navin Sarma, Gabriel Nava, Emily To, Sushil Nath, Alexander Schiffhauer, Isaac Reynolds, Bill Strathearn, Marius Renn, Alex Hong, Jose Ricardo Lima, Bob Hung, Ying Chen Lou, Joy Hsu, Blade Chiu, David Massoud, Jean Hsu, Ellie Yang, and Marc Levoy.
I found the CVAE tutorial on tensorflow.org. I then repurposed it on new data however it is only reconstructing the outline in a nearly grayscale image, ignoring the colour, the loss is 14000. Please help…
For the 13th year running, NVIDIA professional GPUs have powered the dazzling visuals and cinematics behind every Academy Award nominee for Best Visual Effects. The 93rd annual Academy Awards will take place on Sunday, April 25, with five VFX nominees in the running: The Midnight Sky Tenet Mulan The One and Only Ivan Love and Read article >
Posted by John D. Co-Reyes, Research Intern and Yingjie Miao, Senior Software Engineer, Google Research
A long-term, overarching goal of research into reinforcement learning (RL) is to design a single general purpose learning algorithm that can solve a wide array of problems. However, because the RL algorithm taxonomy is quite large, and designing new RL algorithms requires extensive tuning and validation, this goal is a daunting one. A possible solution would be to devise a meta-learning method that could design new RL algorithms that generalize to a wide variety of tasks automatically.
In recent years, AutoML has shown great success in automating the design of machine learning components, such as neural networks architectures and model update rules. One example is Neural Architecture Search (NAS), which has been used to develop better neural network architectures for image classification and efficient architectures for running on phones and hardware accelerators. In addition to NAS, AutoML-Zero shows that it’s even possible to learn the entire algorithm from scratch using basic mathematical operations. One common theme in these approaches is that the neural network architecture or the entire algorithm is represented by a graph, and a separate algorithm is used to optimize the graph for certain objectives.
These earlier approaches were designed for supervised learning, in which the overall algorithm is more straightforward. But in RL, there are more components of the algorithm that could be potential targets for design automation (e.g., neural network architectures for agent networks, strategies for sampling from the replay buffer, overall formulation of the loss function), and it is not always clear what the best model update procedure would be to integrate these components. Prior efforts for the automation RL algorithm discovery have focused primarily on model update rules. These approaches learn the optimizer or RL update procedure itself and commonly represent the update rule with a neural network such as an RNN or CNN, which can be efficiently optimized with gradient-based methods. However, these learned rules are not interpretable or generalizable, because the learned weights are opaque and domain specific.
In our paper “Evolving Reinforcement Learning Algorithms”, accepted at ICLR 2021, we show that it’s possible to learn new, analytically interpretable and generalizable RL algorithms by using a graph representation and applying optimization techniques from the AutoML community. In particular, we represent the loss function, which is used to optimize an agent’s parameters over its experience, as a computational graph, and use Regularized Evolution to evolve a population of the computational graphs over a set of simple training environments. This results in increasingly better RL algorithms, and the discovered algorithms generalize to more complex environments, even those with visual observations like Atari games.
RL Algorithm as a Computational Graph Inspired by ideas from NAS, which searches over the space of graphs representing neural network architectures, we meta-learn RL algorithms by representing the loss function of an RL algorithm as a computational graph. In this case, we use a directed acyclic graph for the loss function, with nodes representing inputs, operators, parameters and outputs. For example, in the computational graph for DQN, input nodes include data from the replay buffer, operator nodes include neural network operators and basic math operators, and the output node represents the loss, which will be minimized with gradient descent.
There are a few benefits of such a representation. This representation is expressive enough to define existing algorithms but also new, undiscovered algorithms. It is also interpretable. This graph representation can be analyzed in the same way as human designed RL algorithms, making it more interpretable than approaches that use black box function approximators for the entire RL update procedure. If researchers can understand why a learned algorithm is better, then they can both modify the internal components of the algorithm to improve it and transfer the beneficial components to other problems. Finally, the representation supports general algorithms that can solve a wide variety of problems.
Example computation graph for DQN which computes the squared Bellman error.
We implemented this representation using the PyGlove library, which conveniently turns the graph into a search space that can be optimized with regularized evolution.
Evolving RL Algorithms We use an evolutionary based approach to optimize the RL algorithms of interest. First, we initialize a population of training agents with randomized graphs. This population of agents is trained in parallel over a set of training environments. The agents first train on a hurdle environment — an easy environment, such as CartPole, intended to quickly weed out poorly performing programs.
If an agent cannot solve the hurdle environment, the training is stopped early with a score of zero. Otherwise the training proceeds to more difficult environments (e.g., Lunar Lander, simple MiniGrid environments, etc.). The algorithm performance is evaluated and used to update the population, where more promising algorithms are further mutated. To reduce the search space, we use a functional equivalence checker which will skip over newly proposed algorithms if they are functionally the same as previously examined algorithms. This loop continues as new mutated candidate algorithms are trained and evaluated. At the end of training, we select the best algorithm and evaluate its performance over a set of unseen test environments.
The population size in the experiments was around 300 agents, and we observed the evolution of good candidate loss functions after 20-50 thousand mutations, requiring about three days of training. We were able to train on CPUs because the training environments were simple, controlling for the computational and energy cost of training. To further control the cost of training, we seeded the initial population with human-designed RL algorithms such as DQN.
Overview of meta-learning method. Newly proposed algorithms must first perform well on a hurdle environment before being trained on a set of harder environments. Algorithm performance is used to update a population where better performing algorithms are further mutated into new algorithms. At the end of training, the best performing algorithm is evaluated on test environments.
Learned Algorithms We highlight two discovered algorithms that exhibit good generalization performance. The first is DQNReg, which builds on DQN by adding a weighted penalty on the Q-values to the normal squared Bellman error. The second learned loss function, DQNClipped, is more complex, although its dominating term has a simple form — the max of the Q-value and the squared Bellman error (modulo a constant). Both algorithms can be viewed as a way to regularize the Q-values. While DQNReg adds a soft constraint, DQNClipped can be interpreted as a kind of constrained optimization that will minimize the Q-values if they become too large. We show that this learned constraint kicks in during the early stage of training when overestimating the Q-values is a potential issue. Once this constraint is satisfied, the loss will instead minimize the original squared Bellman error.
A closer analysis shows that while baselines like DQN commonly overestimate Q-values, our learned algorithms address this issue in different ways. DQNReg underestimates the Q-values, while DQNClipped has similar behavior to double dqn in that it slowly approaches the ground truth without overestimating it.
It’s worth pointing out that these two algorithms consistently emerge when the evolution is seeded with DQN. Learning from scratch, the method rediscovers the TD algorithm. For completeness, we release a dataset of top 1000 performing algorithms discovered during evolution. Curious readers could further investigate the properties of these learned loss functions.
Overestimated values are generally a problem in value-based RL. Our method learns algorithms that have found a way to regularize the Q-values and thus reduce overestimation.
Learned Algorithms Generalization Performance Normally in RL, generalization refers to a trained policy generalizing across tasks. However, in this work we’re interested in algorithmic generalization performance, which means how well an algorithm works over a set of environments. On a set of classical control environments, the learned algorithms can match baselines on the dense reward tasks (CartPole, Acrobot, LunarLander) and outperform DQN on the sparser reward task, MountainCar.
Performance of learned algorithms versus baselines on classical control environments.
On a set of sparse reward MiniGrid environments, which test a variety of different tasks, we see that DQNReg greatly outperforms baselines on both the training and test environments, in terms of sample efficiency and final performance. In fact, the effect is even more pronounced on the test environments, which vary in size, configuration, and existence of new obstacles, such as lava.
Training environment performance versus training steps as measured by episode return over 10 training seeds. DQNReg can match or outperform baselines in sample efficiency and final performance.
DQNReg can greatly outperform baselines on unseen test environments.
We visualize the performance of normal DDQN vs. the learned algorithm DQNReg on a few MiniGrid environments. The starting location, wall configuration, and object configuration of these environments are randomized at each reset, which requires the agent to generalize instead of simply memorizing the environment. While DDQN often struggles to learn any meaningful behavior, DQNReg can learn the optimal behavior efficiently.
DDQN
DQNReg (Learned)
Even on image-based Atari environments we observe improved performance, even though training was on non-image-based environments. This suggests that meta-training on a set of cheap but diverse training environments with a generalizable algorithm representation could enable radical algorithmic generalization.
Env
DQN
DDQN
PPO
DQNReg
Asteroid
1364.5
734.7
2097.5
2390.4
Bowling
50.4
68.1
40.1
80.5
Boxing
88.0
91.6
94.6
100.0
RoadRunner
39544.0
44127.0
35466.0
65516.0
Performance of learned algorithm, DQNReg, against baselines on several Atari games. Performance is evaluated over 200 test episodes every 1 million steps.
Conclusion In this post, we’ve discussed learning new interpretable RL algorithms by representing their loss functions as computational graphs and evolving a population of agents over this representation. The computational graph formulation allows researchers to both build upon human-designed algorithms and study the learned algorithms using the same mathematical toolset as the existing algorithms. We analyzed a few of the learned algorithms and can interpret them as a form of entropy regularization to prevent value overestimation. These learned algorithms can outperform baselines and generalize to unseen environments. The top performing algorithms are available for further analytical study.
We hope that future work will extend to more varied RL settings such as actor critic algorithms or offline RL. Furthermore we hope that this work can lead to machine assisted algorithm development where computational meta-learning can help researchers find new directions to pursue and incorporate learned algorithms into their own work.
Acknowledgements We thank our co-authors Daiyi Peng, Esteban Real, Sergey Levine, Quoc V. Le, Honglak Lee, and Aleksandra Faust. We also thank Luke Metz for helpful early discussions and feedback on the paper, Hanjun Dai for early discussions on related research ideas, Xingyou Song, Krzysztof Choromanski, and Kevin Wu for helping with infrastructure, and Jongwook Choi for helping with environment selection. Finally we thank Tom Small for designing animations for this post.
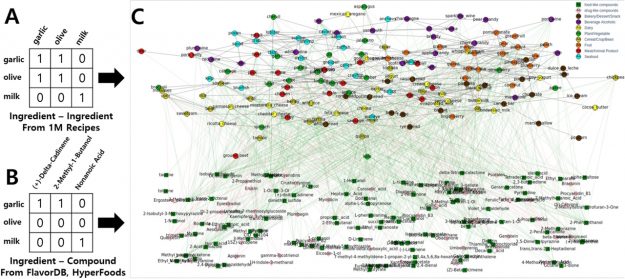
A new ingredient mapping tool by Sony AI and Korea University uses molecular science and recipe data to predict how two ingredients will pair together.
It’s not just gourmet chefs who can discover new flavor combinations— a new ingredient mapping tool by Sony AI and Korea University uses molecular science and recipe data to predict how two ingredients will pair together and suggest new mash-ups.
Dubbed FlavorGraph, the graph embedding model was trained on a million recipes and chemical structure data from more than 1,500 flavor molecules. The researchers used PyTorch, CUDA and an NVIDIA TITAN GPU to train and test their large-scale food graph.
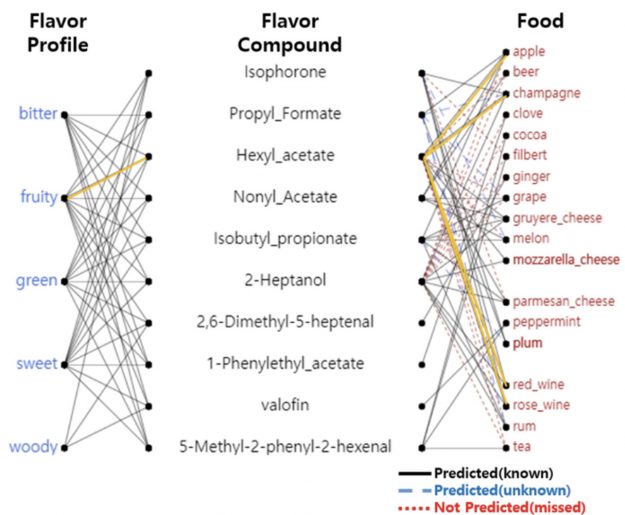
Researchers have previously used molecular science to explain classic flavor pairings such as garlic and ginger, cheese and tomato, or pork and apple — determining that ingredients with common dominant flavor molecules combine well. In the FlavorGraph database, flavor molecule information was grouped into profiles such as bitter, fruity, and sweet.
But other ingredient pairings have different chemical makeups, prompting the team to incorporate recipes into the database as well, giving the model insight into ways flavors have been combined in the past.
FlavorGraph is a large-scale graph network of food and chemical compound nodes.
“The outcome is pairing suggestions that achieve better results than ever before,” wrote Korea University researcher Donghyeon Park and Fred Gifford, strategy and partnerships manager at Sony. “These suggestions can be used to predict relationships between compounds and foods, hinting at new and exciting recipe techniques and driving new perspectives on food science in general.”
Featuring in Scientific Reports, FlavorGraph shows the connections between flavor profiles and the underlying chemical compounds in specific foods. It’s based on the metapath2vec model, and outperforms other baseline methods for food clustering.
The researchers hope the project will lead to the discovery of new recipes, more interesting flavor combinations, and potential substitutes for unhealthy or unsustainable ingredients.
“We hope that projects like this will continue to complement both the complex ingredient systems fossilized over time through cultural evolution, as well as the electric ingenuity of modern innovators and chefs,” the team wrote.
What began as a budding academic movement into farm AI projects has now blossomed into a field of startups creating agriculture technology with a positive social impact for Earth. Whether it’s the threat to honey bees worldwide from varroa mites, devastation to citrus markets from citrus greening, or contamination of groundwater caused from agrochemicals — Read article >
Though admittedly prone to breaking kitchen appliances like ovens and microwaves, Julie Bernauer — senior solutions architect for machine learning and deep learning at NVIDIA — led the small team that successfully built Selene, the world’s fifth-fastest supercomputer. Adding to an already impressive feat, Bernauer’s team brought up Selene as the world went into lockdown Read article >

 NVIDIA announced the availability of cuSPARSELt version 0.1.0. This software can be downloaded now free for members of the NVIDIA Developer Program.
NVIDIA announced the availability of cuSPARSELt version 0.1.0. This software can be downloaded now free for members of the NVIDIA Developer Program. cdot op(B) + beta op(C)")
")
")
 There is a wide range of graph applications and algorithms that I hope to discuss through this series of blog posts, all with a bias toward what is in RAPIDS cuGraph. I am assuming that the reader has a basic understanding of graph theory and graph analytics. If there is interest in a graph analytic …
There is a wide range of graph applications and algorithms that I hope to discuss through this series of blog posts, all with a bias toward what is in RAPIDS cuGraph. I am assuming that the reader has a basic understanding of graph theory and graph analytics. If there is interest in a graph analytic … 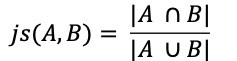
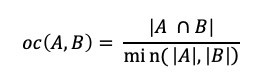
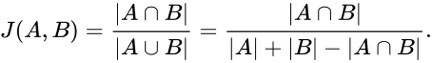

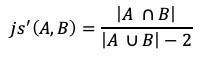
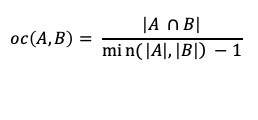























 A new ingredient mapping tool by Sony AI and Korea University uses molecular science and recipe data to predict how two ingredients will pair together.
A new ingredient mapping tool by Sony AI and Korea University uses molecular science and recipe data to predict how two ingredients will pair together.