 |
submitted by /u/MLtinkerer [visit reddit] [comments] |

 DataBloom
DataBloom
|
submitted by /u/MLtinkerer [visit reddit] [comments] |
 |
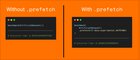
Originally posted here. 💡 #TensorFlowTip Use .prefetch to reduce your step time of training and
See the speedup with .prefetch in this image. Try it for submitted by /u/Rishit-dagli |
pip install tensorflow==2.0.0-alpha0In this tutorial, I’ll be using a generic MNIST Convolutional Neural Network example, but utilizing full TensorFlow 2 design paradigms. To learn more about CNNs, see this tutorial – to understand more about TensorFlow 2 paradigms, see this tutorial. All the code for this tutorial can be found as a Google Colaboratory file on my Github repository.

mean_metric = tf.keras.metrics.Mean() mean_metric.update_state(2.0) mean_metric.update_state(3.0) mean_metric.update_state(4.0) print(mean_metric.result().numpy())This will print the average result -> 3.0. As can be observed, there is an internal memory for the metric, which can be appended to using update_state(). The Mean metric operation is executed when result() is called. Finally, to reset the memory of the metric, we can use reset_states() as follows:
mean_metric.reset_states() print(mean_metric.result().numpy())This will print the default response of an empty metric – 0.0.
summary_writer = tf.summary.create_file_writer('/log')
To log something to the summary writer, the developer must first enclose the “space” within your code which does the logging with a Python with statement. The logging looks like so:
with summary_writer.as_default():
tf.summary.scalar('mean', mean_metric.result(), step=1)
The with context can surround the full training loop, or just the area of the code where you are storing the summaries. As can be observed, the logged scalar value is set by using the metric result() method. The step value needs to be provided to the summary – this allows TensorBoard to plot the variation of various values, images etc. between training steps. The step number can be tracked manually, but the easiest way is to use the iterations property of whatever optimizer you are using. This will be demonstrated in the example below.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() BATCH_SIZE=64 # first the training set train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(BATCH_SIZE).shuffle(10000) train_dataset = train_dataset.map(lambda x, y: (tf.cast(x, tf.float32) / 255.0, y)) train_dataset = train_dataset.map(lambda x, y: (tf.expand_dims(x, -1) / 255.0, y)) train_dataset = train_dataset.repeat() # now the validation set valid_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(5000).shuffle(10000) valid_dataset = valid_dataset.map(lambda x, y: (tf.cast(x, tf.float32) / 255.0, y)) valid_dataset = valid_dataset.map(lambda x, y: (tf.expand_dims(x, -1) / 255.0, y)) valid_dataset = valid_dataset.repeat()In the lines above, some preprocessing is applied to the image data to normalize it (divide the pixel values by 255, make the tensors 4D for consumption into CNN layers). Next I define the CNN model, using the Keras sequential paradigm:
model = tf.keras.Sequential() model.add(tf.keras.layers.Conv2D(32, 2, 1, activation='relu', input_shape=(28, 28, 1))) model.add(tf.keras.layers.MaxPool2D(2)) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.Conv2D(32, 2, 1, activation='relu')) model.add(tf.keras.layers.MaxPool2D(2)) model.add(tf.keras.layers.BatchNormalization()) model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(10))The model declaration above is all standard Keras – for more on the sequential model type of Keras, see here. Next, we create a custom training loop function in TensorFlow. It is now best practice to encapsulate core parts of your code in Python functions – this is so that the @tf.function decorator can be applied easily to the function. This signals to TensorFlow to perform Just In Time (JIT) compilation of the relevant code into a graph, which allows the performance benefits of a static graph as per TensorFlow 1.X. Otherwise, the code will execute eagerly, which is not a big deal, but if one is building production or performance dependent code it is better to decorate with @tf.function. Here’s the training loop and optimization/loss function definitions:
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def train(ds_train, optimizer, loss_fn, model, num_batches, log_freq=10):
avg_loss = tf.keras.metrics.Mean()
avg_acc = tf.keras.metrics.SparseCategoricalAccuracy()
batch_idx = 0
for batch_idx, (images, labels) in enumerate(ds_train):
images = tf.expand_dims(images, -1)
with tf.GradientTape() as tape:
logits = model(images)
loss_value = loss_fn(labels, logits)
grads = tape.gradient(loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
avg_loss.update_state(loss_value)
avg_acc.update_state(labels, logits)
if batch_idx % log_freq == 0:
print(f"Batch {batch_idx}, average loss is {avg_loss.result().numpy()}, average accuracy is {avg_acc.result().numpy()}")
tf.summary.scalar('loss', avg_loss.result(), step=optimizer.iterations)
tf.summary.scalar('acc', avg_acc.result(), step=optimizer.iterations)
avg_loss.reset_states()
avg_acc.reset_states()
if batch_idx > num_batches:
break
As can be observed, I have created two metrics for use in this training loop – avg_loss and avg_acc. These are Mean and SparseCategoricalAccuracy metrics, respectively. The Mean metric has been discussed previously. The SparseCategoricalAccuracy metric takes, as input, the training labels and logits (raw, unactivated outputs from your model). Because it is a sparse categorical accuracy measure, it can take the training labels in scalar integer form, rather than one-hot encoded label vectors. Calling result() on this metric will calculate the average accuracy of all the labels/logits pairs passed during the update_state() call – see line 15 above.
Every log_freq number of batches, the results of the metrics are printed and also passed as summary scalars. After the metrics are logged in the summaries, their states are reset. You will notice that I have not provided a with context for these summaries – this is applied in the outer epoch loop is shown below:
num_epochs = 10
summary_writer = tf.summary.create_file_writer('./log/{}'.format(dt.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")))
for i in range(num_epochs):
print(f"Epoch {i + 1} of {num_epochs}")
with summary_writer.as_default():
train(train_dataset, optimizer, loss_fn, model, 10000//BATCH_SIZE)
As can be observed, the summary_writer.as_default() is supplied as context to the whole train function.
So far so good. However, this is utilizing a “manual” TensorFlow training loop, which is no longer the easiest way to train in TensorFlow 2, given the tight Keras integration. In the next example, I’ll show you how to include run of the mill metrics in the Keras API, but also custom metrics.
metric_model.compile(optimizer=tf.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
However, if one wishes to log more complicated or custom metrics, it becomes difficult to see how to set this up in Keras. One easy way of doing so is by creating a custom Keras layer whose sole purpose is to add a metric to the model / training. In the example below, I have created a custom layer which adds the standard deviation of the kernel weights as a metric:
class MetricLayer(tf.keras.layers.Layer):
def __init__(self, layer_to_log):
super(MetricLayer, self).__init__()
self.layer_to_log = layer_to_log
def call(self, input):
self.add_metric(tf.keras.backend.std(self.layer_to_log.variables[0]),
name=f'std_of_{self.layer_to_log.name}_kernel',
aggregation='mean')
return input
A few things to notice about the creation of the custom layer above. First, notice that the layer is defined as a Python class object which inherits from the keras.layers.Layer object. The only variable passed to the initialization of this custom class is the layer with the kernel weights which we wish to log. The call method tells Keras / TensorFlow what to do when the layer is called in a feed forward pass. In this case, the input is passed straight through to the output – it is, in essence, a dummy layer. However, you’ll notice within the call a metric is added.
The value of the metric is the standard deviation of layer_to_log.variables[0]. For a CNN layer, the zero index [0] of the layer variables is the kernel weights. A name is provided to the metric for ease of viewing during training, and finally the aggregation method of the metric is specified – in this case, a ‘mean’ aggregation of the standard deviations.
To include this layer, one can just add it as a sequential element in the Keras model. In the below I take the existing CNN model created in the previous example, and create a new model with the custom metric layer appended to the end:
metric_model = tf.keras.Sequential() metric_model.add(model) metric_model.add(MetricLayer(model.layers[0]))As can be observed in the above, the first layer of the previous model is passed to the custom MetricLayer. Running the fit training method on this model will now generate both the SparseCategoricalAccuracy metric, along with the custom standard deviation from the first layer. To monitor in TensorBoard, one must also include the TensorBoard callback. All of this looks like the following:
metric_model.compile(optimizer=tf.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
callbacks = [
# Write TensorBoard logs to `./logs` directory
tf.keras.callbacks.TensorBoard(log_dir='./log/{}'.format(dt.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")), update_freq='batch')
]
metric_model.fit(train_dataset, steps_per_epoch=10000//BATCH_SIZE, epochs=5,
validation_data=valid_dataset, validation_steps=5,
callbacks=callbacks)
The code above will perform the training and ensure all the metrics (including the metric added in the custom metric layer) are output to TensorBoard via the TensorBoard callback.
This concludes my quick introduction to metrics and summaries in TensorFlow 2. Watch out for future posts and updates of existing posts as the transition to TensorFlow 2 develops.
The post Metrics and summaries in TensorFlow 2 appeared first on Adventures in Machine Learning.
For those familiar with convolutional neural networks (if you’re not, check out this post), you will know that, for many architectures, the final set of layers are often of the fully connected variety. This is like bolting a standard neural network classifier onto the end of an image processor. The convolutional neural network starts with a series of convolutional (and, potentially, pooling) layers which create feature maps which represent different components of the input images. The fully connected layers at the end then “interpret” the output of these features maps and make category predictions. However, as with many things in the fast moving world of deep learning research, this practice is starting to fall by the wayside in favor of something called Global Average Pooling (GAP). In this post, I’ll introduce the benefits of Global Average Pooling and apply it on the Cats vs Dogs image classification task using TensorFlow 2. In the process, I’ll compare its performance to the standard fully connected layer paradigm. The code for this tutorial can be found in a Jupyter Notebook on this site’s Github repository, ready for use in Google Colaboratory.
Global Average Pooling is an operation that calculates the average output of each feature map in the previous layer. This fairly simple operation reduces the data significantly and prepares the model for the final classification layer. It also has no trainable parameters – just like Max Pooling (see here for more details). The diagram below shows how it is commonly used in a convolutional neural network:

Global Average Pooling in a CNN architecture
As can be observed, the final layers consist simply of a Global Average Pooling layer and a final softmax output layer. As can be observed, in the architecture above, there are 64 averaging calculations corresponding to the 64, 7 x 7 channels at the output of the second convolutional layer. The GAP layer transforms the dimensions from (7, 7, 64) to (1, 1, 64) by performing the averaging across the 7 x 7 channel values. Global Average Pooling has the following advantages over the fully connected final layers paradigm:
To test out these ideas in practice, in the next section I’ll show you an example comparing the benefits of the Global Average Pooling with the historical paradigm. This example problem will be the Cats vs Dogs image classification task and I’ll be using TensorFlow 2 to build the models. At the time of writing, only TensorFlow 2 Alpha is available, and the reader can follow this link to find out how to install it.
To download the Cats vs Dogs data for this example, you can use the following code:
import tensorflow as tf
from tensorflow.keras import layers
import tensorflow_datasets as tfds
split = (80, 10, 10)
splits = tfds.Split.TRAIN.subsplit(weighted=split)
(cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True)
The code above utilizes the TensorFlow Datasets repository which allows you to import common machine learning datasets into TF Dataset objects. For more on using Dataset objects in TensorFlow 2, check out this post. A few things to note. First, the split tuple (80, 10, 10) signifies the (training, validation, test) split as percentages of the dataset. This is then passed to the tensorflow_datasets split object which tells the dataset loader how to break up the data. Finally, the tfds.load() function is invoked. The first argument is a string specifying the dataset name to load. Following arguments relate to whether a split should be used, whether to return an argument with information about the dataset (info) and whether the dataset is intended to be used in a supervised learning problem, with labels being included. In order to examine the images in the data set, the following code can be run:
import matplotlib.pylab as plt for image, label in cat_train.take(2): plt.figure() plt.imshow(image)
This produces the following images: 
 As can be observed, the images are of varying sizes. This will need to be rectified so that the images have a consistent size to feed into our model. As usual, the image pixel values (which range from 0 to 255) need to be normalized – in this case, to between 0 and 1. The function below performs these tasks:
As can be observed, the images are of varying sizes. This will need to be rectified so that the images have a consistent size to feed into our model. As usual, the image pixel values (which range from 0 to 255) need to be normalized – in this case, to between 0 and 1. The function below performs these tasks:
IMAGE_SIZE = 100 def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0 image = tf.image.resize(image, (IMAGE_SIZE, IMAGE_SIZE)) return image, label
In this example, we’ll be resizing the images to 100 x 100 using tf.image.resize. To get state of the art levels of accuracy, you would probably want a larger image size, say 200 x 200, but in this case I’ve chosen speed over accuracy for demonstration purposes. As can be observed, the image values are also cast into the tf.float32 datatype and normalized by dividing by 255. Next we apply this function to the datasets, and also shuffle and batch where appropriate:
TRAIN_BATCH_SIZE = 64 cat_train = cat_train.map(pre_process_image).shuffle(1000).repeat().batch(TRAIN_BATCH_SIZE) cat_valid = cat_valid.map(pre_process_image).repeat().batch(1000)
For more on TensorFlow datasets, see this post. Now it is time to build the model – in this example, we’ll be using the Keras API in TensorFlow 2. In this example, I’ll be using a common “head” model, which consists of layers of standard convolutional operations – convolution and max pooling, with batch normalization and ReLU activations:
head = tf.keras.Sequential()
head.add(layers.Conv2D(32, (3, 3), input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
head.add(layers.Conv2D(32, (3, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
head.add(layers.Conv2D(64, (3, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
Next, we need to add the “back-end” of the network to perform the classification.
In the first instance, I’ll show the results of a standard fully connected classifier, without dropout. Because, for this example, there are only two possible classes – “cat” or “dog” – the final output layer is a dense / fully connected layer with a single node and a sigmoid activation.
standard_classifier = tf.keras.Sequential()
standard_classifier.add(layers.Flatten())
standard_classifier.add(layers.BatchNormalization())
standard_classifier.add(layers.Dense(100))
standard_classifier.add(layers.Activation('relu'))
standard_classifier.add(layers.BatchNormalization())
standard_classifier.add(layers.Dense(100))
standard_classifier.add(layers.Activation('relu'))
standard_classifier.add(layers.Dense(1))
standard_classifier.add(layers.Activation('sigmoid'))
As can be observed, in this case, the output classification layers includes 2 x 100 node dense layers. To combine the head model and this standard classifier, the following commands can be run:
standard_model = tf.keras.Sequential([
head,
standard_classifier
])
Finally, the model is compiled, a TensorBoard callback is created for visualization purposes, and the Keras fit command is executed:
standard_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='binary_crossentropy',
metrics=['accuracy'])
callbacks = [tf.keras.callbacks.TensorBoard(log_dir='./log/{}'.format(dt.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")))]
standard_model.fit(cat_train, steps_per_epoch = 23262//TRAIN_BATCH_SIZE, epochs=10, validation_data=cat_valid, validation_steps=10, callbacks=callbacks)
Note that the loss used is binary crossentropy, due to the binary classes for this example. The training progress over 7 epochs can be seen in the figure below:

Standard classifier accuracy (red – training, blue – validation)

Standard classifier loss (red – training, blue – validation)
As can be observed, with a standard fully connected classifier back-end to the model (without dropout), the training accuracy reaches high values but it overfits with respect to the validation dataset. The validation dataset accuracy stagnates around 80% and the loss begins to increase – a sure sign of overfitting.
The next step is to test the results of the Global Average Pooling in TensorFlow 2. To build the GAP layer and associated model, the following code is added:
average_pool = tf.keras.Sequential()
average_pool.add(layers.AveragePooling2D())
average_pool.add(layers.Flatten())
average_pool.add(layers.Dense(1, activation='sigmoid'))
pool_model = tf.keras.Sequential([
head,
average_pool
])
The accuracy results for this model, along with the results of the standard fully connected classifier model, are shown below:

Global average pooling accuracy vs standard fully connected classifier model (pink – GAP training, green – GAP validation, blue – FC classifier validation)
As can be observed from the graph above, the Global Average Pooling model has a higher validation accuracy by the 7th epoch than the fully connected model. The training accuracy is lower than the FC model, but this is clearly due to overfitting being reduced in the GAP model. A final comparison including the case of the FC model with a dropout layer inserted is shown below:
standard_classifier_with_do = tf.keras.Sequential()
standard_classifier_with_do.add(layers.Flatten())
standard_classifier_with_do.add(layers.BatchNormalization())
standard_classifier_with_do.add(layers.Dense(100))
standard_classifier_with_do.add(layers.Activation('relu'))
standard_classifier_with_do.add(layers.Dropout(0.5))
standard_classifier_with_do.add(layers.BatchNormalization())
standard_classifier_with_do.add(layers.Dense(100))
standard_classifier_with_do.add(layers.Activation('relu'))
standard_classifier_with_do.add(layers.Dense(1))
standard_classifier_with_do.add(layers.Activation('sigmoid'))

Global average pooling validation accuracy vs FC classifier with and without dropout (green – GAP model, blue – FC model without DO, orange – FC model with DO)
As can be seen, of the three model options sharing the same convolutional front end, the GAP model has the best validation accuracy after 7 epochs of training (x – axis in the graph above is the number of batches). Dropout improves the validation accuracy of the FC model, but the GAP model is still narrowly out in front. Further tuning could be performed on the fully connected models and results may improve. However, one would expect Global Average Pooling to be at least equivalent to a FC model with dropout – even though it has hundreds of thousands of fewer parameters. I hope this short tutorial gives you a good understanding of Global Average Pooling and its benefits. You may want to consider it in the architecture of your next image classifier design.
The post An introduction to Global Average Pooling in convolutional neural networks appeared first on Adventures in Machine Learning.
In this post, I’m going to cover the very important deep learning concept called transfer learning. Transfer learning is the process whereby one uses neural network models trained in a related domain to accelerate the development of accurate models in your more specific domain of interest. For instance, a deep learning practitioner can use one of the state-of-the-art image classification models, already trained, as a starting point for their own, more specialized, image classification task. In this tutorial, I’ll be showing you how to perform transfer learning using an advanced, pre-trained image classification model – ResNet50 – to improve a more specific image classification task – the cats vs dogs classification problem. In particular, I’ll be showing you how to do this using TensorFlow 2. The code for this tutorial, in a Google Colaboratory notebook format, can be found on this site’s Github repository here. This code borrows some components from the official TensorFlow tutorial.
Transfer learning has many benefits, these are:
For these reasons, if you are performing some image recognition task, it may be worth using some of the pre-trained, state-of-the-art image classification models, like ResNet, DenseNet, InceptionNet and so on. How does one use these pre-trained models?
To create a transfer learning model, all that is required is to take the pre-trained layers and “bolt on” your own network. This could be either at the beginning or end of the pre-trained model. Usually, one disables the pre-trained layer weights and only trains the “bolted on” layers which have been added. For image classification transfer learning, one usually takes the convolutional neural network (CNN) layers from the pre-trained model and adds one or more densely connected “classification” layers at the end (for more on convolutional neural networks, see this tutorial). The pre-trained CNN layers act as feature extractors / maps, and the classification layer/s at the end can be “taught” to “interpret” these image features. The transfer learning model architecture that will be used in this example is shown below:

ResNet50 transfer learning architecture
The full ResNet50 model shown in the image above, in addition to a Global Average Pooling (GAP) layer, contains a 1000 node dense / fully connected layer which acts as a “classifier” of the 2048 (4 x 4) feature maps output from the ResNet CNN layers. For more on Global Average Pooling, see my tutorial. In this transfer learning task, we’ll be removing these last two layers (GAP and Dense layer) and replacing these with our own GAP and dense layer (in this example, we have a binary classification task – hence the output size is only 1). The GAP layer has no trainable parameters, but the dense layer obviously does – these will be the only parameters trained in this example. All of this is performed quite easily in TensorFlow 2, as will be shown in the next section.
In this example, we’ll be using the pre-trained ResNet50 model and transfer learning to perform the cats vs dogs image classification task. I’ll also train a smaller CNN from scratch to show the benefits of transfer learning. To access the image dataset, we’ll be using the tensorflow_datasets package which contains a number of common machine learning datasets. To load the data, the following commands can be run:
import tensorflow as tf
from tensorflow.keras import layers
import tensorflow_datasets as tfds
split = (80, 10, 10)
splits = tfds.Split.TRAIN.subsplit(weighted=split)
(cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True)
A few things to note about the code snippet above. First, the split tuple (80, 10, 10) signifies the (training, validation, test) split as percentages of the dataset. This is then passed to the tensorflow_datasets split object which tells the dataset loader how to break up the data. Finally, the tfds.load() function is invoked. The first argument is a string specifying the dataset name to load. Following arguments relate to whether a split should be used, whether to return an argument with information about the dataset (info) and whether the dataset is intended to be used in a supervised learning problem, with labels being included. The variables cat_train, cat_valid and cat_test are TensorFlow Dataset objects – to learn more about these, check out my previous post. In order to examine the images in the data set, the following code can be run:
import matplotlib.pylab as plt for image, label in cat_train.take(2): plt.figure() plt.imshow(image)
This produces the following images: As can be observed, the images are of varying sizes. This will need to be rectified so that the images have a consistent size to feed into our model. As usual, the image pixel values (which range from 0 to 255) need to be normalized – in this case, to between 0 and 1. The function below performs these tasks:
IMAGE_SIZE = 100 def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0 image = tf.image.resize(image, (IMAGE_SIZE, IMAGE_SIZE)) return image, label
In this example, we’ll be resizing the images to 100 x 100 using tf.image.resize. To get state of the art levels of accuracy, you would probably want a larger image size, say 200 x 200, but in this case I’ve chosen speed over accuracy for demonstration purposes. As can be observed, the image values are also cast into the tf.float32 datatype and normalized by dividing by 255. Next we apply this function to the datasets, and also shuffle and batch where appropriate:
TRAIN_BATCH_SIZE = 64 cat_train = cat_train.map(pre_process_image).shuffle(1000).repeat().batch(TRAIN_BATCH_SIZE) cat_valid = cat_valid.map(pre_process_image).repeat().batch(1000)
First, we’ll build a smaller CNN image classifier which will be trained from scratch.
In the code below, a 3 x CNN layer head, a GAP layer and a final densely connected output layer is created. The Keras API, which is the encouraged approach for TensorFlow 2, is used in the model definition below. For more on Keras, see this and this tutorial.
head = tf.keras.Sequential()
head.add(layers.Conv2D(32, (3, 3), input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
head.add(layers.Conv2D(32, (3, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
head.add(layers.Conv2D(64, (3, 3)))
head.add(layers.BatchNormalization())
head.add(layers.Activation('relu'))
head.add(layers.MaxPooling2D(pool_size=(2, 2)))
average_pool = tf.keras.Sequential()
average_pool.add(layers.AveragePooling2D())
average_pool.add(layers.Flatten())
average_pool.add(layers.Dense(1, activation='sigmoid'))
standard_model = tf.keras.Sequential([
head,
average_pool
])
To train the model we run:
standard_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='binary_crossentropy',
metrics=['accuracy'])
callbacks = [tf.keras.callbacks.TensorBoard(log_dir='./log/standard_model', update_freq='batch')]
standard_model.fit(cat_train, steps_per_epoch = 23262//TRAIN_BATCH_SIZE, epochs=7,
validation_data=cat_valid, validation_steps=10, callbacks=callbacks)
Note that the loss function is ‘binary cross-entropy’, due to the fact that the cats vs dogs image classification task is a binary classification problem (i.e. 0 = cat, 1 = dog or vice-versa). Running the code above, after 7 epochs, gives a training accuracy of around 89% and a validation accuracy of around 85%. Next we’ll see how this compares to the transfer learning case.
To download the ResNet50 model, you can utilize the tf.keras.applications object to download the ResNet50 model in Keras format with trained parameters. To do so, run the following code:
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) res_net = tf.keras.applications.ResNet50(weights='imagenet', include_top=False, input_shape=IMG_SHAPE)
The weights argument ‘imagenet’ denotes that the weights to be used are those generated by being trained on the ImageNet dataset. The include_top argument states that we only want the CNN-feature maps part of the ResNet50 model – not its final GAP and dense connected layers. Finally, we need to specify what input shape we want the model being setup to receive. Next, we need to disable the training of the parameters within this Keras model. This is performed really easily:
res_net.trainable = False
Next we create a Global Average Pooling layer, along with a final densely connected output layer with sigmoid activation. Then the model is combined using the Keras sequential framework where Keras models can be chained together:
global_average_layer = layers.GlobalAveragePooling2D() output_layer = layers.Dense(1, activation='sigmoid') tl_model = tf.keras.Sequential([ res_net, global_average_layer, output_layer ])
That’s all that’s required – TensorFlow 2 and Keras make many deep learning tasks quite easy. Running tl_model.summary() gives the following output:
Layer (type) Output Shape Param # ================================================================= resnet50 (Model) (None, 4, 4, 2048) 23587712 _________________________________________________________________ global_average_pooling2d (Gl (None, 2048) 0 _________________________________________________________________ dense_1 (Dense) (None, 1) 2049 ================================================================= Total params: 23,589,761 Trainable params: 2,049 Non-trainable params: 23,587,712 _________________________________________________________________
As can be observed, while the total number of parameters is large (i.e. 23 million) the number of trainable parameters, corresponding to the weights of the final output layer, is only 2,049.
To train the model we run:
tl_model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='binary_crossentropy',
metrics=['accuracy'])
callbacks = [tf.keras.callbacks.TensorBoard(log_dir='./log/transer_learning_model', update_freq='batch')]
tl_model.fit(cat_train, steps_per_epoch = 23262//TRAIN_BATCH_SIZE, epochs=7,
validation_data=cat_valid, validation_steps=10, callbacks=callbacks)
The graphs below from TensorBoard show the relative performance of the small CNN model trained from scratch and the ResNet50 transfer learning model:

Transfer learning training accuracy comparison (blue – ResNet50, pink – smaller CNN model)

Transfer learning validation accuracy comparision (red – ResNet50 model, green – smaller CNN model)
The results above show that the ResNet50 model reaches higher levels of both training and validation accuracy much quicker than the smaller CNN model that was trained from scratch. This illustrates the benefit of using these powerful pre-trained models as a starting point for your more domain specific deep learning tasks. I hope this post has been a help and given you a good understanding of the benefits of transfer learning, and also how to implement it easily in TensorFlow 2.
The post Transfer learning in TensorFlow 2 tutorial appeared first on Adventures in Machine Learning.
In previous posts (here and here), deep Q reinforcement learning was introduced. In these posts, examples were presented where neural networks were used to train an agent to act within an environment to maximize rewards. The neural network was trained using something called Q-learning. However, deep Q learning (DQN) has a flaw – it can be unstable due to biased estimates of future rewards, and this slows learning. In this post, I’ll introduce Double Q learning which can solve this bias problem and produce better Q-learning outcomes. We’ll be running a Double Q network on a modified version of the Cartpole reinforcement learning environment. We’ll also be developing the network in TensorFlow 2 – at the time of writing, TensorFlow 2 is in beta and installation instructions can be found here. The code examined in this post can be found here.
As mentioned above, you can go here and here to review deep Q learning. However, a quick recap is in order. The goal of the neural network in deep Q learning is to learn the function $Q(s_t, a_t; theta_t)$. At a given time in the game / episode, the agent will be in a state $s_t$. This state is fed into the network, and various Q values will be returned for each of the possible actions $a_t$ from state $s_t$. The $theta_t$ refers to the parameters of the neural network (i.e. all the weight and bias values).
The agent chooses an action based on an epsilon-greedy policy $pi$. This policy is a combination of randomly selected actions combined with the output of the deep Q neural network – with the probability of a randomly selected action decreasing over the training time. When the deep Q network is used to select an action, it does so by taking the maximum Q value returned over all the actions, for state $s_t$. For example, if an agent is in state 1, and this state has 4 possible actions which the agent can perform, it will output 4 Q values. The action which has the highest Q value is the action which will be selected. This can be expressed as:
$$a = argmax Q(s_t, a; theta_t)$$
Where the argmax is performed over all the actions / output nodes of the neural network. That’s how actions are chosen in deep Q learning. How does training occur? It occurs by utilising the Q-learning / Bellman equation. The equation looks like this:
$$Q_{target} = r_{t+1} + gamma max_{{a}}Q(s_{t+1}, a;theta_t)$$
How does this read? For a given action a from state $s_{t}$, we want to train the network to predict the following:
If we are successful in training the network to predict these values, the agent will consistently chose the action which gives the best immediate reward ($r_{t+1}$) plus the discounted future rewards of future states $gamma max_{{a}}Q(s_{t+1}, a;theta_t)$. The $gamma$ term is the discount term, which places less value on future reward than present rewards (but usually only marginally).
In deep Q learning, the game is repeatedly played and the states, actions and rewards are stored in memory as a list of tuples or an array – ($s_t$, $a$, $r_t$, $s_{t+1}$). Then, for each training step, a random batch of these tuples is extracted from memory and the $Q_{target}(s_t, a_t)$ is calculated and compared to the value produced from the current network $Q(s_t, a_t)$ – the mean squared difference between these two values is used as the loss function to train the neural network.
That’s a fairly brief recap of deep Q learning – for a more extended treatment see here and here. The next section will explain the problems with standard deep Q learning.
The problem of deep Q learning has to do with the way it sets the target values:
$$Q_{target} = r_{t+1} + gamma max_{{a}}Q(s_{t+1}, a;theta_t)$$
Namely, the issue is with the $max$ value. This part of the equation is supposed to estimate the value of the rewards for future actions if action a is taken from the current state $s_t$. That’s a bit of a mouthful, but just consider it as trying to estimate the optimal future rewards $r_future$ if action a is taken.
The problem is that in many environments, there is random noise. Therefore, as an agent explores an environment, it is not directly observing r or $r_future$, but something like $r + epsilon$, where $epsilon$ is the noise. In such an environment, after repeated playing of the game, we would hope that the network would learn to make unbiased estimates of the expected value of the rewards – so E[r]. If it can do this, we are in a good spot – the network should pick out the best actions for current and future rewards, despite the presence of noise.
This is where the $max$ operation is a problem – it produces biased estimates of the future rewards, not the unbiased estimates we require for optimal results. An example will help explain this better. Consider the environment below. The agent starts in state A and at each state can move left or right. The states C, D and F are terminal states – the game ends once these points are reached. The r values are the rewards the agent receives when transitioning from state to state.

Deep Q network bias illustration
All the rewards are deterministic except for the rewards when transitioning from states B to C and B to D. The rewards for these transitions are randomly drawn from a normal distribution with a mean of 1 and a standard deviation of 4.
We know the expected rewards, E[r] from taking either action (B to C or B to D) is 1 – however, there is a lot of noise associated with these rewards. Regardless, on average, the agent should ideally learn to always move to the left from A, towards E and finally F where r always equals 2.
Let’s consider the $Q_{target}$ expression for these cases. Let’s set $gamma$ to be 0.95. The $Q_target$ expression to move to the left from A is: $Q_{target} = 0 + 0.95 * max([0, 2]) = 1.9$. The two action options from E are to either move right (r = 0) or left (r = 2). The maximum of these is obviously 2, and hence we get the result 1.9.
What about in the opposite direction, moving right from A? In this case, it is $Q_{target} = 0 + 0.95 * max([N(1, 4), N(1, 4)])$. We can explore the long term value of this “moving right” action by using the following code snippet:
import numpy as np Ra = np.zeros((10000,)) Rc = np.random.normal(1, 4, 10000) Rd = np.random.normal(1, 4, 10000) comb = np.vstack((Ra, Rc, Rd)).transpose() max_result = np.max(comb, axis=1) print(np.mean(Rc)) print(np.mean(Rd)) print(np.mean(max_result))
Here a 10,000 iteration trial is created of what the $max$ term will yield in the long term of running a deep Q agent in this environment. Ra is the reward for moving back to the left towards A (always zero, hence np.zeros()). Rc and Rd are both normal distributions, with mean 1 and standard deviation of 4. Combining all these options together and taking the maximum for each trial gives us what the trial-by-trial $max$ term will be (max_result). Finally, the expected values (i.e. the means) of each quantity are printed. As expected, the mean of Rc and Rd are approximately equal to 1 – the mean which we set for their distributions. However, the expected value / mean from the $max$ term is actually around 3!
You can see the problem here. Because the $max$ term is always taking the maximum value from the random draws of the rewards, it tends to be positively biased and does not give a true indication of the expected values of the rewards for a move in this direction (i.e. 1). As such, an agent using the deep Q learning methodology will not chose the optimal action from A (i.e. move left) but will rather tend to move right!
Therefore, in noisy environments, it can be seen that deep Q learning will tend to overestimate rewards. Eventually, deep Q learning will converge to a reasonable solution, but it is potentially much slower than it needs to be. A further problem occurs in deep Q learning which can cause instability in the training process. Consider that in deep Q learning the same network both choses the best action and determines the value of choosing said actions. There is a feedback loop here which can exacerbate the previously mentioned reward overestimation problem, and further slow down the learning process. This is clearly not ideal, and this is why Double Q learning was developed.
The paper that introduced Double Q learning initially proposed the creation of two separate networks which predicted $Q^A$ and $Q^B$ respectively. These networks were trained on the same environment / problem, but were each randomly updated. So, say, 50% of the time, $Q^A$ was updated based on a certain random set of training tuples, and 50% of the time $Q^B$ was updated on a different random set of training tuples. Importantly, the update or target equation for network A had an estimate of the future rewards from network B – not itself. This new approach does two things:
The algorithm from the original paper is as follows:

Original Double Q algorithm
As can be observed, first an action is chosen from either $Q^A(s_t,.)$ or $Q^B(s_t,.)$ and the rewards, next state, action etc. are stored in the memory. Then either UPDATE(A) or UPDATE(B) is chosen randomly. Next, for the state $s_{t+1}$ (or s’ in the above) the predicted Q value for all actions from this state are taken from network A or B, and the action with the highest predicted Q value is chosen, a*. Note that, within UPDATE(A), this action is chosen from the output of the $Q^A$ network.
Next, you’ll see something interesting. Consider the update equation for $Q^A$ above – I’ll represent it in more familiar, neural network based notation below:
$$Q^A_{target} = r_{t+1} + gamma Q^B(s_{t+1}, a*)$$
Notice that, while the best action a* from the next state ($s_{t+1}$) is chosen from network A, the discounted reward for taking that future action is extracted from network B. This removes any bias associated with the $argmax$ from network A, and also decouples the choice of actions from the evaluation of the value of such actions (i.e. breaks the feedback loop). This is the heart of the Double Q reinforcement learning.
The same author of the original Double Q algorithm shown above proposed an update of the algorithm in this paper. This updated algorithm can still legitimately be called a Double Q algorithm, but the author called it Double DQN (or DDQN) to disambiguate. The main difference in this algorithm is the removal of the randomized back-propagation based updating of two networks A and B. There are still two networks involved, but instead of training both of them, only a primary network is actually trained via back-propagation. The other network, often called the target network, is periodically copied from the primary network. The update operation for the primary network in the Double DQN network looks like the following:
$$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, argmax Q(s_{t+1}, a; theta_t); theta^-_t)$$
Alternatively, keeping in line with the previous representation:
$$a* = argmax Q(s_{t+1}, a; theta_t)$$
$$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, a*); theta^-_t)$$
Notice that, as per the previous algorithm, the action a* with the highest Q value from the next state ($s_{t+1}$) is extracted from the primary network, which has weights $theta_t$. This primary network is also often called the “online” network – it is the network from which action decisions are taken. However, notice that, when determining $Q_{target}$, the discounted Q value is taken from the target network with weights $theta^-_t$. Therefore, the actions for the agent to take are extracted from the online network, but the evaluation of the future rewards are taken from the target network. So far, this is similar to the UPDATE(A) step shown in the previous Double Q algorithm.
The difference in this algorithm is that the target network weights ($theta^-_t$) are not trained via back-propagation – rather they are periodically copied from the online network. This reduces the computational overhead of training two networks by back-propagation. This copying can either be a periodic “hard copy”, where the weights are copied from the online network to the target network with no modification, or a more frequent “soft copy” can occur, where the existing target weight values and the online network values are blended. In the example which will soon follow, soft copying will be performed every training iteration, under the following rule:
$$theta^- = theta^- (1-tau) + theta tau$$
With $tau$ being a small constant (i.e. 0.05).
This DDQN algorithm achieves both decoupling between the action choice and evaluation, and it has been shown to remove the bias of deep Q learning. In the next section, I’ll present a code walkthrough of a training algorithm which contains options for both standard deep Q networks and Double DQNs.
In this example, I’ll present code which trains a double Q network on the Cartpole reinforcement learning environment. This environment is implemented in OpenAI gym, so you’ll need to have that package installed before attempting to run or replicate. The code for this example can be found on this site’s Github repo.
First, we declare some constants and create the environment:
STORE_PATH = '/Users/andrewthomas/Adventures in ML/TensorFlowBook/TensorBoard'
MAX_EPSILON = 1
MIN_EPSILON = 0.01
LAMBDA = 0.0005
GAMMA = 0.95
BATCH_SIZE = 32
TAU = 0.08
RANDOM_REWARD_STD = 1.0
env = gym.make("CartPole-v0")
state_size = 4
num_actions = env.action_space.n
Notice the epsilon greedy policy parameters (MIN_EPSILON, MAX_EPSILON, LAMBDA) which dictate how long the exploration period of the training should last. GAMMA is the discount rate of future rewards. The final constant RANDOM_REWARD_STD will be explained later in more detail.
It can be observed that the CartPole environment has a state size of 4, and the number of actions available are extracted directly from the environment (there are only 2 of them). Next the primary (or online) network and the target network are created using the Keras Sequential API:
primary_network = keras.Sequential([
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(num_actions)
])
target_network = keras.Sequential([
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(num_actions)
])
primary_network.compile(optimizer=keras.optimizers.Adam(), loss='mse')
The code above is fairly standard Keras model definitions, with dense layers and ReLU activations, and He normal initializations (for further information, see these posts: Keras, ReLU activations and initialization). Notice that only the primary network is compiled, as this is the only network which will be trained via the Adam optimizer.
class Memory:
def __init__(self, max_memory):
self._max_memory = max_memory
self._samples = []
def add_sample(self, sample):
self._samples.append(sample)
if len(self._samples) > self._max_memory:
self._samples.pop(0)
def sample(self, no_samples):
if no_samples > len(self._samples):
return random.sample(self._samples, len(self._samples))
else:
return random.sample(self._samples, no_samples)
@property
def num_samples(self):
return len(self._samples)
memory = Memory(50000)
Next a generic Memory class object is created. This holds all the ($s_t$, a, $r_t$, $s_{t+1}$) tuples which are stored during training, and includes functionality to extract random samples for training. In this example, we’ll be using a Memory instance with a maximum sample buffer of 50,000 rows.
def choose_action(state, primary_network, eps):
if random.random() < eps:
return random.randint(0, num_actions - 1)
else:
return np.argmax(primary_network(state.reshape(1, -1)))
The function above executes the epsilon greedy action policy. As explained in previous posts on deep Q learning, the epsilon value is slowly reduced and the action selection moves from the random selection of actions to actions selected from the primary network. A final training function needs to be reviewed, but first we’ll examine the main training loop:
num_episodes = 1000
eps = MAX_EPSILON
render = False
train_writer = tf.summary.create_file_writer(STORE_PATH + f"/DoubleQ_{dt.datetime.now().strftime('%d%m%Y%H%M')}")
double_q = False
steps = 0
for i in range(num_episodes):
state = env.reset()
cnt = 0
avg_loss = 0
while True:
if render:
env.render()
action = choose_action(state, primary_network, eps)
next_state, reward, done, info = env.step(action)
reward = np.random.normal(1.0, RANDOM_REWARD_STD)
if done:
next_state = None
# store in memory
memory.add_sample((state, action, reward, next_state))
loss = train(primary_network, memory, target_network if double_q else None)
avg_loss += loss
state = next_state
# exponentially decay the eps value
steps += 1
eps = MIN_EPSILON + (MAX_EPSILON - MIN_EPSILON) * math.exp(-LAMBDA * steps)
if done:
avg_loss /= cnt
print(f"Episode: {i}, Reward: {cnt}, avg loss: {avg_loss:.3f}, eps: {eps:.3f}")
with train_writer.as_default():
tf.summary.scalar('reward', cnt, step=i)
tf.summary.scalar('avg loss', avg_loss, step=i)
break
cnt += 1
Starting from the num_episodes loop, we can observe that first the environment is reset, and the current state of the agent returned. A while True loop is then entered into, which is only exited when the environment returns the signal that the episode has been completed. The code will render the Cartpole environment if the relevant variable has been set to True.
The next line shows the action selection, where the primary network is fed into the previously examined choose_network function, along with the current state and the epsilon value. This action is then fed into the environment by calling the env.step() command. This command returns the next state that the agent has entered ($s_{t+1}$), the reward ($r_{t+1}$) and the done Boolean which signifies if the episode has been completed.
The Cartpole environment is completely deterministic, with no randomness involved except in the initialization of the environment. Because Double Q learning is superior to deep Q learning especially when there is randomness in the environment, the Cartpole environment has been externally transformed into a stochastic environment on the next line. Normally, the reward from the Cartpole environment is a deterministic value of 1.0 for every step the pole stays upright. Here, however, the reward is replaced with a sample from a normal distribution, with mean 1.0 and standard deviation equal to the constant RANDOM_REWARD_STD.
In the first pass – RANDOM_REWARD_STD is set to 0.0 to transform the environment back to a deterministic case, but this will be changed in the next example run.
After this, the memory is added to and the primary network is trained.
Notice that the target_network is only passed to the training function if the double_q variable is set to True. If double_q is set to False, the training function defaults to standard deep Q learning. Finally the state is updated, and if the environment has signalled the episode has ended, some logging is performed and the while loop is exited.
It is now time to review the train function, which is where most of the work takes place:
def train(primary_network, memory, target_network=None):
if memory.num_samples < BATCH_SIZE * 3:
return 0
batch = memory.sample(BATCH_SIZE)
states = np.array([val[0] for val in batch])
actions = np.array([val[1] for val in batch])
rewards = np.array([val[2] for val in batch])
next_states = np.array([(np.zeros(state_size)
if val[3] is None else val[3]) for val in batch])
# predict Q(s,a) given the batch of states
prim_qt = primary_network(states)
# predict Q(s',a') from the evaluation network
prim_qtp1 = primary_network(next_states)
# copy the prim_qt into the target_q tensor - we then will update one index corresponding to the max action
target_q = prim_qt.numpy()
updates = rewards
valid_idxs = np.array(next_states).sum(axis=1) != 0
batch_idxs = np.arange(BATCH_SIZE)
if target_network is None:
updates[valid_idxs] += GAMMA * np.amax(prim_qtp1.numpy()[valid_idxs, :], axis=1)
else:
prim_action_tp1 = np.argmax(prim_qtp1.numpy(), axis=1)
q_from_target = target_network(next_states)
updates[valid_idxs] += GAMMA * q_from_target.numpy()[batch_idxs[valid_idxs], prim_action_tp1[valid_idxs]]
target_q[batch_idxs, actions] = updates
loss = primary_network.train_on_batch(states, target_q)
if target_network is not None:
# update target network parameters slowly from primary network
for t, e in zip(target_network.trainable_variables, primary_network.trainable_variables):
t.assign(t * (1 - TAU) + e * TAU)
return loss
The first line is a bypass of this function if the memory does not contain more than 3 x the batch size – this is to ensure no training of the primary network takes place until there is a reasonable amount of samples within the memory.
Next, a batch is extracted from the memory – this is a list of tuples. The individual state, actions and reward values are then extracted and converted to numpy arrays using Python list comprehensions. Note that the next_state values are set to zeros if the raw next_state values are None – this only happens when the episode has terminated.
Next the sampled states ($s_t$) are passed through the network – this returns the values $Q(s_t, a; theta_t)$. The next line extracts the Q values from the primary network for the next states ($s_{t+1}$). Next, we want to start constructing our target_q values ($Q_target$). These are the “labels” which will be supplied to the primary network to train towards.
Note that the target_q values are the same as the prim_qt ($Q(s_t, a; theta_t)$) values except for the index corresponding to the action chosen. So, for instance, let’s say a single sample of the prim_qt values are [0.5, -0.5] – but the action chosen from $s_t$ was 0. We only want to update the 0.5 value while training, the remaining values in target_q remain equal to prim_qt (i.e. [update, -0.5]). Therefore, in the next line, we create target_q by simply converting prim_qt from a tensor into its numpy equivalent. This is basically a copy of the values from prim_qt t0 target_q. We convert to numpy also, as it is easier to deal with indexing in numpy than TensorFlow at this stage.
To affect these updates, we create a new variable updates. The first step is to set the update values to the sampled rewards – the $r_{t+1}$ values are the same regardless of whether we are performing deep Q learning or Double Q learning. In the following lines, these update values will be added to in order to capture the discounted future reward terms. The next line creates an array called valid_idxs. This array is to hold all those samples in the batch which don’t include a case where next_state is zero. When next_state is zero, this means that the episode has terminated. In those cases, only the first term of the equation below remains ($r_{t+1}$):
$$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, a*); theta^-_t)$$
Seeing as update already includes the first term, any further additions to update need to exclude these indexes.
The next line, batch_idxs, is simply a numpy arange which counts out the number of samples within the batch. This is included to ensure that the numpy indexing / broadcasting to follow works properly.
The next line switches depending on whether Double Q learning has been enabled or not. If target_network is None, then standard deep Q learning ensures. In such a case, the following term is calculated and added to updates (which already includes the reward term):
$$gamma max Q(s_{t+1}, a; theta)$$
Alternatively, if target_network is not None, then Double Q learning is performed. The first line:
prim_action_tp1 = np.argmax(prim_qtp1.numpy(), axis=1)
calculates the following equation shown earlier:
$$a* = argmax Q(s_{t+1}, a; theta_t)$$
The next line extracts the Q values from the target network for state $s_{t+1}$ and assigns this to variable q_from_target. Finally, the update term has the following added to it:
$$gamma Q(s_{t+1}, a*); theta^-_t)$$
Notice, that the numpy indexing extracts from q_from_target all the valid batch samples, and within those samples, all the highest Q actions drawn from the primary network (i.e. a*).
Finally, the target_q values corresponding to the actions a from state $s_t$ are updated with the update array.
Following this, the primary network is trained on this batch of data using the Keras train_on_batch. The last step in the function involves copying the primary or online network values into the target network. This can be varied so that this step only occurs every X amount of training steps (especially when one is doing a “hard copy”). However, as stated previously, in this example we’ll be doing a “soft copy” and therefore every training step involves the target network weights being moved slightly towards the primary network weights. As can be observed, for every trainable variable in both the primary and target networks, the target network trainable variables are assigned new values updated via the previously presented formula:
$$theta^- = theta^- (1-tau) + theta tau$$
That (rather lengthy) explanation concludes the discussion of how Double Q learning can be implemented in TensorFlow 2. Now it is time to examine the results of the training.
In the first case, we are going to examine the deterministic training case when RANDOM_REWARD_STD is set to 0.0. The TensorBoard graph below shows the results:

Double Q deterministic case (blue – Double Q, red – deep Q)
As can be observed, in both the Double Q and deep Q training cases, the networks converge on “correctly” solving the Cartpole problem – with eventual consistent rewards of 180-200 per episode (a total reward of 200 is the maximum available per episode in the Cartpole environment). The Double Q case shows slightly better performance in reaching the “solved” state than the deep Q network implementation. This is likely due to better stability in decoupling the choice and evaluation of the actions, but it is not a conclusive result in this rather simple deterministic environment.
However, what happens when we increase the randomness by elevated RANDOM_REWARD_STD > 0?
The results below show the case when RANDOM_REWARD_STD is increased to 1.0 – in this case, the rewards are drawn from a random normal distribution of mean 1.0 and standard deviation of 1.0:

Double Q stochastic case (blue – Double Q, red – deep Q)
As can be seen, in this case, the Double Q network significantly outperforms the deep Q training methodology. This demonstrates the effect of biasing in the deep Q training methodology, and the advantages of using Double Q learning in your reinforcement learning tasks.
I hope this post was helpful in increasing your understanding of both deep Q and Double Q reinforcement learning. Keep an eye out for future posts on reinforcement learning.
The post Double Q reinforcement learning in TensorFlow 2 appeared first on Adventures in Machine Learning.
In previous tutorials, I’ve explained convolutional neural networks (CNN) and shown how to code them. The convolutional layer has proven to be a great success in the area of image recognition and processing in machine learning. However, state of the art techniques don’t involve just a few CNN layers. Rather, they can be very deep, consisting of 10s to >100 numbers of layers. One of the most successful CNN architectures developed has been the ResNet architecture. It was first introduced in 2015 (see this paper) and won the ILSVRC 2015 image classification task. The winning ResNet consisted of a whopping 152 layers, and in order to successfully make a network that deep, a significant innovation in CNN architecture was developed for ResNet. This innovation will be discussed in this post, and an example ResNet architecture will be developed in TensorFlow 2 and compared to a standard architecture. Because of the training requirements for this task, I have developed the code in Google Colaboratory (which gives free GPU time – see my tutorial here), and the notebook can be found on this site’s Github repository.
The vanishing gradient problem was an initial barrier to making neural networks deeper and more powerful. However, as explained in this post, the problem has now largely been solved through the use of ReLU activations and batch normalization. Given this is true, and given enough computational power and data, we should be able to stack many CNN layers and dramatically increase classification accuracy, right? Well – to a degree. An early architecture, called the VGG-19 architecture, had 19 layers. However, this is a long way off the 152 layers of the version of ResNet that won the ILSVRC 2015 image classification task. The reason deeper networks were not successful prior to the ResNet architecture was due to something called the degradation problem. Note, this is not the vanishing gradient problem, but something else. It was observed that making the network deeper led to higher classification errors. One might think this is due to overfitting of the data – but not so fast, the degradation problem leads to higher training errors too! Consider the diagrams below from the original ResNet paper:

Illustration of degradation problem that ResNet solves
Note that the 56-layer network has higher test and training errors. Theoretically, this doesn’t make much sense. Let’s say the 20-layer network learns some mapping H(x) that gives a training error of 10%. If another 36 layers are added, we would expect that the error would at least not be any worse than 10%. Why? Well, the 36 extra layers, at worst, could just learn identity functions. In other words, the extra 36 layers could just learn to pass through the output from the first 20-layers of the network. This would give the same error of 10%. This doesn’t seem to happen though. It appears neural networks aren’t great at learning the identity function in deep architectures. Not only don’t they learn the identity function (and hence pass through the 20 layer error rate), they make things worse. Beyond a certain number of layers, they begin to degrade the performance of the network compared to shallower implementations. Here is where the ResNet architecture comes in.
The ResNet solution relies on making the identity function option explicit in the architecture, rather than relying on the network itself to learn the identity function where appropriate. It consists of building networks which consist of the following CNN blocks:

ResNet building block from here
In the diagram above, the input tensor x enters the building block. This input then splits. On one path, the input is processed by two stacked convolutional layers (called a “weight layer” in the above). This path is the “standard” CNN processing part of the building block. The ResNet innovation is the “identity” path. Here, the input x is simply added to the output of the CNN component of the building block, F(x). The output from the block is then F(x) + x with a final ReLU activation applied at the end. This identity path in the ResNet building block allows the neural network to more easily pass through any abstractions learnt in previous layers. Alternatively, it can more easily build incremental abstractions on top of the abstractions learnt in the previous layers. What do I mean by this? The diagram below may help:

Layers and abstractions
Generally speaking, as CNN layers are added to a network, the network during training will learn lower level abstractions in the early layers (i.e lines, colours, corners, basic shapes etc.) and higher level abstractions in the later layers (groups of geometries, objects etc.). Let’s say that, when trying to classify an aircraft in an image, there are some mid-level abstractions which reliably signal that an aircraft is present. Say the shape of a jet engine near a wing (this is just an example). These abstractions might be able to be learnt in, say, 10 layers.
However, if we add an additional 20 or more layers after these first 10 layers, these reliable signals may get degraded / obfuscated. The ResNet architecture gives the network a more explicit chance of muting further CNN abstractions on some filters by driving F(x) to zero, with the output of the block defaulting to its input x. Not only that, the ResNet architecture allows blocks to “tinker” more easily with the input. This is because the block only has to learn the incremental difference between the previous layer abstraction and the optimal output H(x). In other words, it has to learn F(x) = H(x) – x. This is a residual expression, hence the name ResNet. This, theoretically at least, should be easier to learn than the full expression H(x).
An (somewhat tortured) analogy might assist here. Say you are trying to draw the picture of a tree. Someone hands you a picture of a pencil outline of the main structure of the tree – the trunk, large branches, smaller branches etc. Now say you are somewhat proud, and you don’t want too much help in drawing the picture. So, you rub out parts of the pencil outline of the tree that you were handed. You then proceed to add some detail to the picture you were handed, but you have to redraw parts that you already rubbed out. This is kind of like the case of a standard non-ResNet network. Because layers seem to struggle to reproduce an identity function, at each subsequent layer they essentially erase or degrade some of the previous level abstractions and these need to be re-estimated (at least to an extent).
Alternatively, you, the artist, might not be too proud and you happily accept the pencil outline that you received. It is much easier to then add new details to what you have already been given. This is like what the ResNet blocks do – they take what they are give i.e. x and just make tweaks to it by adding F(x). This analogy isn’t perfect, but it should give you an idea of what is going on here, and how the ResNet blocks help the learning along.
A full 34-layer version of ResNet is (partially) illustrated below (from the original paper):

ResNet-34 architecture (partial)
The diagram above shows roughly the first half of the ResNet 34-layer architecture, along with the equivalent layers of the VGG-19 architecture and a “plain” version of the ResNet architecture. The “plain” version has the same CNN layers, but lacks the identity path previously presented in the ResNet building block. These identity paths can be seen looping around every second CNN layer on the right hand side of the ResNet (“residual”) architecture.
In the next section, I’m going to show you how to build a ResNet architecture in TensorFlow 2/Keras. In the example, we’ll compare both the “plain” and “residual” networks on the CIFAR-10 classification task. Note that for computational ease, I’ll only include 10 ResNet blocks.
As discussed previously, the code for this example can be found on this site’s Github repository. Importing the CIFAR-10 dataset can be performed easily by using the Keras datasets API:
import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers import numpy as np import datetime as dt (x_train, y_train), (x_test, y_test) = tf.keras.datasets.cifar10.load_data()
We then perform some pre-processing of the training and test data. This pre-processing includes image renormalization (converting the data so it resides in the range [0,1]) and centrally cropping the image to 75% of it’s normal extents. Data augmentation is also performed by randomly flipping the image about the centre axis. This is performed using the TensorFlow Dataset API – more details on the code below can be found in this, this post and my book.
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(64).shuffle(10000) train_dataset = train_dataset.map(lambda x, y: (tf.cast(x, tf.float32) / 255.0, y)) train_dataset = train_dataset.map(lambda x, y: (tf.image.central_crop(x, 0.75), y)) train_dataset = train_dataset.map(lambda x, y: (tf.image.random_flip_left_right(x), y)) train_dataset = train_dataset.repeat() valid_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(5000).shuffle(10000) valid_dataset = valid_dataset.map(lambda x, y: (tf.cast(x, tf.float32) / 255.0, y)) valid_dataset = valid_dataset.map(lambda x, y: (tf.image.central_crop(x, 0.75), y)) valid_dataset = valid_dataset.repeat()
In this example, to build the network, we’re going to use the Keras Functional API, in the TensorFlow 2 context. Here is what the ResNet model definition looks like:
inputs = keras.Input(shape=(24, 24, 3))
x = layers.Conv2D(32, 3, activation='relu')(inputs)
x = layers.Conv2D(64, 3, activation='relu')(x)
x = layers.MaxPooling2D(3)(x)
num_res_net_blocks = 10
for i in range(num_res_net_blocks):
x = res_net_block(x, 64, 3)
x = layers.Conv2D(64, 3, activation='relu')(x)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(256, activation='relu')(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(10, activation='softmax')(x)
res_net_model = keras.Model(inputs, outputs)
First, we specify the input dimensions to Keras. The raw CIFAR-10 images have a size of (32, 32, 3) – but because we are performing central cropping of 75%, the post-processed images are of size (24, 24, 3). Next, we create 2 standard CNN layers, with 32 and 64 filters respectively (for more on convolutional layers, see this post and my book). The filter window sizes are 3 x 3, in line with the original ResNet architectures. Next some max pooling is performed and then it is time to produce some ResNet building blocks. In this case, 10 ResNet blocks are created by calling the res_net_block() function:
def res_net_block(input_data, filters, conv_size):
x = layers.Conv2D(filters, conv_size, activation='relu', padding='same')(input_data)
x = layers.BatchNormalization()(x)
x = layers.Conv2D(filters, conv_size, activation=None, padding='same')(x)
x = layers.BatchNormalization()(x)
x = layers.Add()([x, input_data])
x = layers.Activation('relu')(x)
return x
The first few lines of this function are standard CNN layers with Batch Normalization, except the 2nd layer does not have an activation function (this is because one will be applied after the residual addition part of the block). After these two layers, the residual addition part, where the input data is added to the CNN output (F(x)), is executed. Here we can make use of the Keras Add layer, which simply adds two tensors together. Finally, a ReLU activation is applied to the result of this addition and the outcome is returned.
After the ResNet block loop is finished, some final layers are added. First, a final CNN layer is added, followed by a Global Average Pooling (GAP) layer (for more on GAP layers, see here). Finally, we have a couple of dense classification layers with a dropout layer in between. This model was trained over 30 epochs and then an alternative “plain” model was also created. This was created by taking the same architecture but replacing the res_net_block function with the following function:
def non_res_block(input_data, filters, conv_size): x = layers.Conv2D(filters, conv_size, activation='relu', padding='same')(input_data) x = layers.BatchNormalization()(x) x = layers.Conv2D(filters, conv_size, activation='relu', padding='same')(x) x = layers.BatchNormalization()(x) return x
Note that this function is simply two standard CNN layers, with no residual components included. The training code is as follows:
callbacks = [
# Write TensorBoard logs to `./logs` directory
keras.callbacks.TensorBoard(log_dir='./log/{}'.format(dt.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")), write_images=True),
]
res_net_model.compile(optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
res_net_model.fit(train_dataset, epochs=30, steps_per_epoch=195,
validation_data=valid_dataset,
validation_steps=3, callbacks=callbacks)
The accuracy results of the training of these two models can be observed below:

ResNet (red) vs “plain” (pink) training accuracy

ResNet (blue) vs “plain” (green) training accuracy
As can be observed there is around a 5-6% improvement in the training accuracy from a ResNet architecture compared to the “plain” non-ResNet architecture. I have run this comparison a number of times and the 5-6% gap is consistent across the runs. These results illustrate the power of the ResNet idea, even for a relatively shallow 10 layer ResNet architecture. As demonstrated in the original paper, this effect will be more pronounced in deeper networks. Note that this network is not very well optimized, and the accuracy could be improved by running for more iterations. However, it is enough to show the benefits of the ResNet architecture. In future posts, I’ll demonstrate other ResNet-based architectures which can achieve even better results.
The post Introduction to ResNet in TensorFlow 2 appeared first on Adventures in Machine Learning.
In this post, we’ll be covering Dueling Q networks for reinforcement learning in TensorFlow 2. This reinforcement learning architecture is an improvement on the Double Q architecture, which has been covered here. In this tutorial, I’ll introduce the Dueling Q network architecture, it’s advantages and how to build one in TensorFlow 2. We’ll be running the code on the Open AI gym‘s CartPole environment so that readers can train the network quickly and easily. In future posts, I’ll be showing results on Atari environments which are more complicated. For an introduction to reinforcement learning, check out this post and this post. All the code for this tutorial can be found on this site’s Github repo.
As discussed in detail in this post, vanilla deep Q learning has some problems. These problems can be boiled down to two main issues:
With regards to (1) – say we have a state with two possible actions, each giving noisy rewards. Action a returns a random reward based on a normal distribution with a mean of 2 and a standard deviation of 1 – N(2, 1). Action b returns a random reward from a normal distribution of N(1, 4). On average, action a is the optimal action to take in this state – however, because of the argmax function in deep Q learning, action b will tend to be favoured because of the higher standard deviation / higher random rewards.
For (2) – let’s consider another state, state 1, with three possible actions a, b, and c. Let’s say we know that b is the optimal action. However, when we first initialize the neural network, in state 1, action a tends to be chosen. When we’re training our network, the loss function will drive the weights of the network towards choosing action b. However, next time we are in state 1, the parameters of the network have changed to such a degree that now action c is chosen. Ideally, we would have liked the network to consistently chose action a in state 1 until it was gradually trained to chose action b. But now the goal posts have shifted, and we are trying to move the network from c to b instead of a to b – this gives rise to instability in training. This is the problem that arises when you have the same network both choosing actions and evaluating the worth of actions.
To overcome this problem , Double Q learning proposed the following way of determining the target Q value: $$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, argmax Q(s_{t+1}, a; theta_t); theta^-_t)$$ Here $theta_t$ refers to the primary network parameters (weights) at time t, and $theta^-_t$ refers to something called the target network parameters at time t. This target network is a kind of delayed copy of the primary network. As can be observed, the optimal action in state t + 1 is chosen from the primary network ($theta_t$) but the evaluation or estimate of the Q value of this action is determined from the target network ($theta^-_t$).
This can be shown more clearly by the equations below: $$a* = argmax Q(s_{t+1}, a; theta_t)$$ $$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, a*; theta^-_t)$$ By doing this two things occur. First, different networks are used to chose the actions and evaluate the actions. This breaks the moving target problem mentioned earlier. Second, the primary network and the target network have essentially been trained on different samples from the memory bank of states and actions (the target network is “trained” on older samples than the primary network). Because of this, any bias due to environmental randomness should be “smoothed out”. As was shown in my previous post on Double Q learning, there is a significant improvement in using Double Q learning instead of vanilla deep Q learning. However, a further improvement can be made on the Double Q idea – the Dueling Q architecture, which will be covered in the next section.
The Dueling Q architecture trades on the idea that the evaluation of the Q function implicitely calculates two quantities:
These values, along with the Q function, Q(s, a), are very important to understand, so we will do a deep dive of these concepts here. Let’s first examine the generalised formula for the value function V(s): $$V^{pi}(s) = mathbb{E} left[ sum_{i=1}^T gamma^{i – 1}r_{i}right]$$ The formula above means that the value function at state s, operating under a policy $pi$, is the summation of future discounted rewards starting from state s. In other words, if an agent starts at s, it is the sum of all the rewards the agent collects operating under a given policy $pi$. The $mathbb{E}$ is the expectation operator.
Let’s consider a basic example. Let’s assume an agent is playing a game with a set number of turns. In the second-to-last turn, the agent is in state s. From this state, it has 3 possible actions, with a reward of 10, 50 and 100 respectively. Let’s say that the policy for this agent is a simple random selection. Because this is the last set of actions and rewards in the game, due to the game finishing next turn, there are no discounted future rewards. The value for this state and the random action policy is: $$V^{pi}(s) = mathbb{E} left[randomleft(10, 50, 100)right)right] = 53.333$$ Now, clearly this policy is not going to produce optimum outcomes. However, we know that for the optimum policy, the value of this state would be: $$V^*(s) = max (10, 50, 100) = 100$$ If you recall, from Q learning theory, the optimal action in this state is: $$a* = argmax Q(s_{t+1}, a)$$ and the optimal Q value from this action in this state would be: $$Q(s, a^*) = max (10, 50, 100) = 100$$ Therefore, under the optimal (deterministic) policy we have: $$Q(s,a^*) = V(s)$$ However, what if we aren’t operating under the optimal policy (yet)? Let’s return to the case where our policy is simple random action selection. In such a case, the Q function at state s could be described as (remember there are no future discounted rewards, and V(s) = 53.333): $$Q(s, a) = V(s) + (-43.33, -3.33, 46.67) = (10, 50, 100)$$ The term (-43.33, -3.33, 46.67) under such an analysis is called the Advantage function A(s, a). The Advantage function expresses the relative benefits of the various actions possible in state s. The Q function can therefore be expressed as: $$Q(s, a) = V(s) + A(s, a)$$ Under the optimum policy we have $A(s, a^*) = 0$, $V(s) = 100$ and therefore: $$Q(s, a) = V(s) + A(s, a) = 100 + (-90, -50, 0) = (10, 50, 100)$$ Now the question becomes, why do we want to decompose the Q function in this way? Because there is a difference between the value of a particular state s and the actions proceeding from that state. Consider a game where, from a given state s*, all actions lead to the agent dying and ending the game. This is an inherently low value state to be in, and who cares about the actions which one can take in such a state? It is pointless for the learning algorithm to waste training resources trying to find the best actions to take. In such a state, the Q values should be based solely on the value function V, and this state should be avoided. The converse case also holds – some states are just inherently valuable to be in, regardless of the effects of subsequent actions.
Consider these images taken from the original Dueling Q paper – showing the value and advantage components of the Q value in the Atari game Enduro:

Atari Enduro – value and advantage highlights
In the Atari Enduro game, the goal of the agent is to pass as many cars as possible. “Running into” a car slows the agent’s car down and therefore reduces the number of cars which will be overtaken. In the images above, it can be observed that the value stream considers the road ahead and the score. However, the advantage stream, does not “pay attention” to anything much when there are no cars visible. It only begins to register when there are cars close by and an action is required to avoid them. This is a good outcome, as when no cars are in view, the network should not be trying to determine which actions to take as this is a waste of training resources. This is the benefit of splitting value and advantage functions.
Now, you could argue that, because the Q function inherently contains both the value and advantage functions anyway, the neural network should learn to separate out these components regardless. Indeed, it may do. However, this comes at a cost. If the ML engineer already knows that it is important to try and separate these values, why not build them into the architecture of the network and save the learning algorithm the hassle? That is essentially what the Dueling Q network architecture does. Consider the image below showing the original architecture:

Dueling Q architecture
First, notice that the first part of architecture is common, with CNN input filters and a common Flatten layer (for more on convolutional neural networks, see this tutorial). After the flatten layer, the network bifurcates – with separate densely connected layers. The first densely connected layer produces a single output corresponding to V(s). The second densely connected layer produces n outputs, where n is the number of available actions – and each of these outputs is the expression of the advantage function. These value and advantage functions are then aggregated in the Aggregation layer to produce Q values estimations for each possible action in state s. These Q values can then be trained to approach the target Q values, generated via the Double Q mechanism i.e.: $$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, argmax Q(s_{t+1}, a; theta_t); theta^-_t)$$ The idea is that, through these separate value and advantage streams, the network will learn to produce accurate estimates of the values and advantages, improving learning performance. What goes on in the aggregation layer? One might think we could just add the V(s) and A(s, a) values together like so: $$Q(s, a) = V(s) + A(s, a)$$ However, there is an issue here and it’s called the problem of identifiabilty. This problem in the current context can be stated as follows: given Q, there is no way to uniquely identify V or A. What does this mean? Say that the network is trying to learn some optimal Q value for action a. Given this Q value, can we uniquely learn a V(s) and A(s, a) value? Under the formulation above, the answer is no.
Let’s say the “true” value of being in state s is 50 i.e. V(s) = 50. Let’s also say the “true” advantage in state s for action a is 10. This will give a Q value, Q(s, a) of 60 for this state and action. However, we can also arrive at the same Q value for a learned V(s) of, say, 0, and an advantage function A(s, a) = 60. Or alternatively, a learned V(s) of -1000 and an advantage A(s, a) of 1060. In other words, there is no way to guarantee the “true” values of V(s) and A(s, a) are being learned separately and uniquely from each other. The commonly used solution to this problem is to instead perform the following aggregation function: $$Q(s,a) = V(s) + A(s,a) – frac{1}{|a|}sum_{a’}A(s,a’)$$ Here the advantage function value is normalized with respect to the mean of the advantage function values over all actions in state s.
In TensorFlow 2.0, we can create a common “head” network, consisting of introductory layers which act to process the images or other environmental / state inputs. Then, two separate streams are created using densely connected layers which learn the value and advantage estimates, respectively. These are then combined in a special aggregation layer which calculates the equation above to finally arrive at Q values. Once the network architecture is specified in accordance with the above description, the training proceeds in the same fashion as Double Q learning. The agent actions can be selected either directly from the output of the advantage function, or from the output Q values. Because the Q values differ from the advantage values only by the addition of the V(s) value (which is independent of the actions), the argmax-based selection of the best action will be the same regardless of whether it is extracted from the advantage or the Q values of the network.
In the next section, the implementation of a Dueling Q network in TensorFlow 2.0 will be demonstrated.
In this section we will be building a Dueling Q network in TensorFlow 2. However, the code will be written so that both Double Q and Dueling Q networks will be able to be constructed with the simple change of a boolean identifier. The environment that the agent will train in is Open AI Gym’s CartPole environment. In this environment, the agent must learn to move the cart platform back and forth in order to stop a pole falling too far below the vertical axis. While Dueling Q was originally designed for processing images, with its multiple CNN layers at the beginning of the model, in this example we will be replacing the CNN layers with simple dense connected layers. Because training reinforcement learning agents using images only (i.e. Atari RL environments) takes a long time, in this introductory post, only a simple environment is used for training the model. Future posts will detail how to efficiently train in Atari RL environments. All the code for this tutorial can be found on this site’s Github repo.
First of all, we declare some constants that will be used in the model, and initiate the CartPole environment:
STORE_PATH = '/Users/andrewthomas/Adventures in ML/TensorFlowBook/TensorBoard'
MAX_EPSILON = 1
MIN_EPSILON = 0.01
EPSILON_MIN_ITER = 5000
DELAY_TRAINING = 300
GAMMA = 0.95
BATCH_SIZE = 32
TAU = 0.08
RANDOM_REWARD_STD = 1.0
env = gym.make("CartPole-v0")
state_size = 4
num_actions = env.action_space.n
The MAX_EPSILON and MIN_EPSILON variables define the maximum and minimum values of the epsilon-greedy variable which will determine how often random actions are chosen. Over the course of the training, the epsilon-greedy parameter will decay from MAX_EPSILON gradually to MIN_EPSILON. The EPSILON_MIN_ITER value specifies how many training steps it will take before the MIN_EPSILON value is obtained. The DELAY_TRAINING constant specifies how many iterations should occur, with the memory buffer being filled, before training of the network is undertaken. The GAMMA value is the future reward discount value used in the Q-target equation, and TAU is the merging rate of the weight values between the primary network and the target network as per the Double Q learning algorithm. Finally, RANDOM_REWARD_STD is the standard deviation of the rewards that introduces some stochastic behaviour into the otherwise deterministic CartPole environment.
After the definition of all these constants, the CartPole environment is created and the state size and number of actions are defined.
The next step in the code is to create a Keras model inherited class which defines the Double or Dueling Q network:
class DQModel(keras.Model):
def __init__(self, hidden_size: int, num_actions: int, dueling: bool):
super(DQModel, self).__init__()
self.dueling = dueling
self.dense1 = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.dense2 = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.adv_dense = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.adv_out = keras.layers.Dense(num_actions,
kernel_initializer=keras.initializers.he_normal())
if dueling:
self.v_dense = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.v_out = keras.layers.Dense(1, kernel_initializer=keras.initializers.he_normal())
self.lambda_layer = keras.layers.Lambda(lambda x: x - tf.reduce_mean(x))
self.combine = keras.layers.Add()
def call(self, input):
x = self.dense1(input)
x = self.dense2(x)
adv = self.adv_dense(x)
adv = self.adv_out(adv)
if self.dueling:
v = self.v_dense(x)
v = self.v_out(v)
norm_adv = self.lambda_layer(adv)
combined = self.combine([v, norm_adv])
return combined
return adv
Let’s go through the above line by line. First, a number of parameters are passed to this model as part of its initialization – these include the size of the hidden layers of the advantage and value streams, the number of actions in the environment and finally a Boolean variable, dueling, to specify whether the network should be a standard Double Q network or a Dueling Q network. The first two model layers defined are simple Keras densely connected layers, dense1 and dense2. These layers have ReLU activations and use the He normal weight initialization. The next two layers defined adv_dense and adv_out pertain to the advantage stream of the network, provided we are discussing a Dueling Q network architecture. If in fact the network is to be a Double Q network (i.e. dueling == False), then these names are a bit misleading and will simply be a third densely connected layer followed by the output Q layer (adv_out). However, keeping with the Dueling Q terminology, the first dense layer associated with the advantage stream is simply another standard dense layer of size = hidden_size. The final layer in this stream, adv_out is a dense layer with only num_actions outputs – each of these outputs will learn to estimate the advantage of all the actions in the given state (A(s, a)).
If the network is specified to be a Dueling Q network (i.e. dueling == True), then the value stream is also created. Again, a standard densely connected layer of size = hidden_size is created (v_dense). Then a final, single node dense layer is created to output the single value estimation (V(s)) for the given state. These layers specify the advantage and value streams respectively. Now the aggregation layer is to be created. This aggregation layer is created by using two Keras layers – a Lambda layer and an Add layer. The Lambda layer allows the developer to specify some user-defined operation to perform on the inputs to the layer. In this case, we want the layer to calculate the following: $$A(s,a) – frac{1}{|a|}sum_{a’}A(s,a’)$$ This is calculated easily by using the lambda x: x – tf.reduce_mean(x) expression in the Lambda layer. Finally, we need a simple Keras addition layer to add this mean-normalized advantage function to the value estimation.
This completes the explanation of the layer definitions in the model. The call method in this model definition then applies these various layers to the state inputs of the model. The following two lines execute the Dueling Q aggregation function:
norm_adv = self.lambda_layer(adv) combined = self.combine([v, norm_adv])
Note that first the mean-normalizing lambda function is applied to the output from the advantage stream. This normalized advantage is then added to the value stream output to produce the final Q values (combined). Now that the model class has been defined, it is time to instantiate two models – one for the primary network and the other for the target network:
primary_network = DQModel(30, num_actions, True)
target_network = DQModel(30, num_actions, True)
primary_network.compile(optimizer=keras.optimizers.Adam(), loss='mse')
# make target_network = primary_network
for t, e in zip(target_network.trainable_variables, primary_network.trainable_variables):
t.assign(e)
After the primary_network and target_network have been created, only the primary_network is compiled as only the primary network is actually trained using the optimization function. As per Double Q learning, the target network is instead moved slowly “towards” the primary network by the gradual merging of weight values. Initially however, the target network trainable weights are set to be equal to the primary network trainable variables, using the TensorFlow assign function.
The next function to discuss is the target network updating which is performed during training. In Double Q network training, there are two options for transitioning the target network weights towards the primary network weights. The first is to perform a wholesale copy of the weights every N training steps. Alternatively, the weights can be moved towards the primary network gradually every training iteration as follows:
def update_network(primary_network, target_network):
# update target network parameters slowly from primary network
for t, e in zip(target_network.trainable_variables, primary_network.trainable_variables):
t.assign(t * (1 - TAU) + e * TAU)
As can be observed, the new target weight variables are a weighted average between the current weight values and the primary network weights – with the weighting factor equal to TAU. The next code snippet is the definition of the memory class:
class Memory:
def __init__(self, max_memory):
self._max_memory = max_memory
self._samples = []
def add_sample(self, sample):
self._samples.append(sample)
if len(self._samples) > self._max_memory:
self._samples.pop(0)
def sample(self, no_samples):
if no_samples > len(self._samples):
return random.sample(self._samples, len(self._samples))
else:
return random.sample(self._samples, no_samples)
@property
def num_samples(self):
return len(self._samples)
memory = Memory(500000)
This class takes tuples of (state, action, reward, next state) values and appends them to a memory list, which is randomly sampled from when required during training. The next function defines the epsilon-greedy action selection policy:
def choose_action(state, primary_network, eps):
if random.random() < eps:
return random.randint(0, num_actions - 1)
else:
return np.argmax(primary_network(state.reshape(1, -1)))
If a random number sampled between the interval 0 and 1 falls below the current epsilon value, a random action is selected. Otherwise, the current state is passed to the primary model – from which the Q values for each action are returned. The action with the highest Q value, selected by the numpy argmax function, is returned.
The next function is the train function, where the training of the primary network takes place:
def train(primary_network, memory, target_network):
batch = memory.sample(BATCH_SIZE)
states = np.array([val[0] for val in batch])
actions = np.array([val[1] for val in batch])
rewards = np.array([val[2] for val in batch])
next_states = np.array([(np.zeros(state_size)
if val[3] is None else val[3]) for val in batch])
# predict Q(s,a) given the batch of states
prim_qt = primary_network(states)
# predict Q(s',a') from the evaluation network
prim_qtp1 = primary_network(next_states)
# copy the prim_qt tensor into the target_q tensor - we then will update one index corresponding to the max action
target_q = prim_qt.numpy()
updates = rewards
valid_idxs = np.array(next_states).sum(axis=1) != 0
batch_idxs = np.arange(BATCH_SIZE)
# extract the best action from the next state
prim_action_tp1 = np.argmax(prim_qtp1.numpy(), axis=1)
# get all the q values for the next state
q_from_target = target_network(next_states)
# add the discounted estimated reward from the selected action (prim_action_tp1)
updates[valid_idxs] += GAMMA * q_from_target.numpy()[batch_idxs[valid_idxs], prim_action_tp1[valid_idxs]]
# update the q target to train towards
target_q[batch_idxs, actions] = updates
# run a training batch
loss = primary_network.train_on_batch(states, target_q)
return loss
For a more detailed explanation of this function, see my Double Q tutorial. However, the basic operations that are performed are expressed in the following formulas: $$a* = argmax Q(s_{t+1}, a; theta_t)$$ $$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, a*; theta^-_t)$$ The best action from the next state, a*, is selected from the primary network (weights = $theta_t$). However, the Q value for this action in the next state ($s_{t+1}$) is extracted from the target network (weights = $theta^-_t$). A Keras train_on_batch operation is performed by passing a batch of states and subsequent target Q values, and the loss is finally returned from this function.
The main training loop which trains our Dueling Q network is shown below:
num_episodes = 1000000
eps = MAX_EPSILON
render = False
train_writer = tf.summary.create_file_writer(STORE_PATH + f"/DuelingQ_{dt.datetime.now().strftime('%d%m%Y%H%M')}")
steps = 0
for i in range(num_episodes):
cnt = 1
avg_loss = 0
tot_reward = 0
state = env.reset()
while True:
if render:
env.render()
action = choose_action(state, primary_network, eps)
next_state, _, done, info = env.step(action)
reward = np.random.normal(1.0, RANDOM_REWARD_STD)
tot_reward += reward
if done:
next_state = None
# store in memory
memory.add_sample((state, action, reward, next_state))
if steps > DELAY_TRAINING:
loss = train(primary_network, memory, target_network)
update_network(primary_network, target_network)
else:
loss = -1
avg_loss += loss
# linearly decay the eps value
if steps > DELAY_TRAINING:
eps = MAX_EPSILON - ((steps - DELAY_TRAINING) / EPSILON_MIN_ITER) *
(MAX_EPSILON - MIN_EPSILON) if steps < EPSILON_MIN_ITER else
MIN_EPSILON
steps += 1
if done:
if steps > DELAY_TRAINING:
avg_loss /= cnt
print(f"Episode: {i}, Reward: {cnt}, avg loss: {avg_loss:.5f}, eps: {eps:.3f}")
with train_writer.as_default():
tf.summary.scalar('reward', cnt, step=i)
tf.summary.scalar('avg loss', avg_loss, step=i)
else:
print(f"Pre-training...Episode: {i}")
break
state = next_state
cnt += 1
Again, this training loop has been explained in detail in the Double Q tutorial. However, some salient points are worth highlighting. First, Double and Dueling Q networks are superior to vanilla Deep Q networks especially in the cases where there is some stochastic component to the environment. As the CartPole environment is deterministic, some stochasticity is added in the reward. Normally, every time step in the episode results in a reward of 1 i.e. the CartPole has survived another time step – good job. However, in this case I’ve added a reward which is sampled from a normal distribution with a mean of 1.0 but a standard deviation of RANDOM_REWARD_STD. This adds the requisite uncertainty which makes Double and Dueling Q networks clearly superior to Deep Q networks – see my Double Q tutorial for a demonstration of this.
Another point to highlight is that training of the primary (and by extension target) network until DELAY_TRAINING steps have been exceeded. Also, the epsilon value for the epsilon-greedy action selection policy doesn’t decay until these DELAY_TRAINING steps have been exceeded.
A comparison of the training progress with respect to the deterministic reward of the agent in the CartPole environment under Double Q and Dueling Q architectures can be observed in the figure below, with the x-axis being the number of episodes:

Dueling Q (light blue) vs Double Q (dark blue) rewards in the CartPole environment
As can be observed, there is a slightly higher performance of the Double Q network with respect to the Dueling Q network. However, the performance difference is fairly marginal, and may be within the variation arising from the random weight initialization of the networks. There is also the issue of the Dueling Q network being slightly more complicated due to the additional value stream. As such, on a fairly simple environment like the CartPole environment, the benefits of Dueling Q over Double Q may not be realized. However, in more complex environments like Atari environments, it is likely that the Dueling Q architecture will be superior to Double Q (this is what the original Dueling Q paper has shown). Future posts will demonstrate the Dueling Q architecture in Atari environments.
The post Dueling Q networks in TensorFlow 2 appeared first on Adventures in Machine Learning.
In previous posts (here and here) I introduced Double Q learning and the Dueling Q architecture. These followed on from posts about deep Q learning, and showed how double Q and dueling Q learning is superior to vanilla deep Q learning. However, these posts only included examples of simplistic environments like the OpenAI Cartpole environment. These types of environments are good to learn on, but more complicated environments are both more interesting and fun. They also demonstrate better the complexities of implementing deep reinforcement learning in realistic cases. In this post, I’ll use similar code to that shown in my Dueling Q TensorFlow 2 but in this case apply it to the Open AI Atari Space Invaders environment. All code for this post can be found on this site’s Github repository. Also, as mentioned in the title, the example code for this post is written using TensorFlow 2. TensorFlow 2 is now released and installation instructions can be found here.
Double Q learning was created to address two problems with vanilla deep Q learning. These are:
The problematic Bellman equation is shown below: $$Q_{target} = r_{t+1} + gamma max_{{a}}Q(s_{t+1}, a;theta_t)$$ The Double Q solution to the two problems above involves creating another target network, which is initially created with weights equal to the primary network. However, during training the primary network and the target network are allowed to “drift” apart. The primary network is trained as per usual, but the target network is not. Instead, the target network weights are either periodically (but not frequently) set equal to the primary network weights, or they are only gradually “blended” with the primary network in a weighted average fashion. The benefit then comes from the fact that in Double Q learning, the Q value of the best action in the next state ($s_{t + 1}$) is extracted from the target network, not the primary network. The primary network is still used to evaluate what the best action will be, a*, by taking an argmax of the outputs from the primary network, but the Q value for this action is evaluated from the target network. This can be observed in the formulation below: $$a* = argmax Q(s_{t+1}, a; theta_t)$$ $$Q_{target} = r_{t+1} + gamma Q(s_{t+1}, a*; theta^-_t)$$ Notice the different weights involved in the formulas above – the best action, a*, is calculated from the network with $theta_t$ weights – this is the primary network weights. However the $Q_{target}$ calculation uses the target network, with weights $theta^-_t$, to estimate the Q value for this chosen action. This Double Q methodology decouples the choosing of an action from the evaluation of the Q value of such an action. This provides more stability to the learning – for more details and a demonstration of the superiority of the Double Q methodology over vanilla Deep Q learning, see this post.
The Dueling Q architecture, discussed in detail in this post, is an improvement to the Double Q network. It uses the same methodology of a target and a primary network, with periodic updates or blending of the target network weights to the primary network weights. However, it builds two important concepts into the architecture of the network. These are the advantage and value functions:
The Q function is the simple addition of these two functions: $$Q(s, a) = V(s) + A(s, a)$$ The motivation of splitting these two functions explicitly in the architecture is that there can be inherently good or bad states for the agent to be in, regardless of the relative benefit of any actions within that state. For instance, in a certain state, all actions may lead to the agent “dying” in a game – this is an inherently bad state to be in, and there is no need to waste computational resources trying to determine the best action in this state. The converse can also be true. Ideally, this “splitting” into the advantage function and value function should be learnt implicitly during training. However, the Dueling Q architecture makes this split explicit, which acts to improve training. The Dueling Q architecture can be observed in the figure below:
Dueling Q architecture
It can be observed that in the Dueling Q architecture, there are common Convolutional Neural Network layers which perform image processing. The output from these layers is then flattened and the network then bifurcates into a Value function stream V(s) and an Advantage function stream A(s, a). The output of these separate streams are then aggregated in a special layer, before finally outputting Q values from the network. The aggregation layer does not perform a simple addition of the Value and Advantage streams – this would result in problems of identifiability (for more details on this, see the original Dueling Q post). Instead, the following aggregation function is performed: $$Q(s,a) = V(s) + A(s,a) – frac{1}{|a|}sum_{a’}A(s,a’)$$ In this post, I’ll demonstrate how to use the Dueling Q architecture to train an agent in TensorFlow 2 to play Atari Space Invaders. However, in this post I will concentrate on the extra considerations required to train the agent via an image stream from an Atari game. For more extra details, again, refer to the original Dueling Q post.
Training reinforcement learning agents on Atari environments is hard – it can be a very time consuming process as the environment complexity is high, especially when the agent needs to visually interpret objects direct from images. As such, each environment needs to be considered to determine legitimate ways of reducing the training burden and improving the performance. Three methods will be used in this post:
The first, relatively easy, step in reducing the computational training burden is to convert all the incoming Atari images from depth-3 RGB colour images to depth-1 greyscale images. This reduces the number of input CNN filters required in the first layer by 3. Another step which can be performed to reduce the size of the input CNN filters is to resize the image inputs to make them smaller. There is obviously a limit in the reduction of the image sizes before learning performance is affected, however, in this case, a halving of the image size by rescaling is possible without affecting performance too much. The original image sizes from the Atari Space Invaders game are (210, 160, 3) – after converting to greyscale and resizing by half, the new image size is (105, 80, 1). Both of these operations are easy enough to implement in TensorFlow 2:
def image_preprocess(image, new_size=(105, 80)):
# convert to greyscale, resize and normalize the image
image = tf.image.rgb_to_grayscale(image)
image = tf.image.resize(image, new_size)
image = image / 255
return image
The next step that is commonly performed when training agents on Atari games is the practice of stacking image frames, and feeding all these frames into the input CNN layers. The purpose of this is to allow the neural network to get some sense of direction of the objects moving within the image. Consider a single, static image – examining such an image on its own will give no information about which direction any of the objects moving within this image are travelling (or their respective speeds). Therefore, for each sample fed into the neural network, a stack of frames is presented to the input – this gives the neural network both time and spatial information to work with. The input dimension to the network are not, then, of size (105, 80, 1) but rather (105, 80, NUM_FRAMES). In this case, we’ll use 3 frames to feed into the network i.e. NUM_FRAMES = 3. The specifics of how these stacked frames are stored, extracted and updated will be revealed as we step through the code in the next section. Additional steps can be taken to improve performance in complex Atari environment and similar cases. These include the skipping of frames and prioritised experience replay (PER). However, these have not been implemented in this example. A future post will discuss the benefits of PER and how to implement it.
The section below details the TensorFlow 2 implementation of training an agent on the Atari Space Invaders environment. In this post, comprehensive details of the Dueling Q architecture and training implementation will not be given – for a step by step discussion on these details, see my Dueling Q introductory post. However, detailed information will be given about the specific new steps required to train in the Atari environment. As stated at the beginning of the post, all code can be found on this site’s Github repository.
First we define the Double/Dueling Q model class with its structure:
env = gym.make("SpaceInvaders-v0")
num_actions = env.action_space.n
class DQModel(keras.Model):
def __init__(self, hidden_size: int, num_actions: int, dueling: bool):
super(DQModel, self).__init__()
self.dueling = dueling
self.conv1 = keras.layers.Conv2D(16, (8, 8), (4, 4), activation='relu')
self.conv2 = keras.layers.Conv2D(32, (4, 4), (2, 2), activation='relu')
self.flatten = keras.layers.Flatten()
self.adv_dense = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.adv_out = keras.layers.Dense(num_actions,
kernel_initializer=keras.initializers.he_normal())
if dueling:
self.v_dense = keras.layers.Dense(hidden_size, activation='relu',
kernel_initializer=keras.initializers.he_normal())
self.v_out = keras.layers.Dense(1, kernel_initializer=keras.initializers.he_normal())
self.lambda_layer = keras.layers.Lambda(lambda x: x - tf.reduce_mean(x))
self.combine = keras.layers.Add()
def call(self, input):
x = self.conv1(input)
x = self.conv2(x)
x = self.flatten(x)
adv = self.adv_dense(x)
adv = self.adv_out(adv)
if self.dueling:
v = self.v_dense(x)
v = self.v_out(v)
norm_adv = self.lambda_layer(adv)
combined = self.combine([v, norm_adv])
return combined
return adv
primary_network = DQModel(256, num_actions, True)
target_network = DQModel(256, num_actions, True)
primary_network.compile(optimizer=keras.optimizers.Adam(), loss='mse')
# make target_network = primary_network
for t, e in zip(target_network.trainable_variables, primary_network.trainable_variables):
t.assign(e)
primary_network.compile(optimizer=keras.optimizers.Adam(), loss=tf.keras.losses.Huber())
In the code above, first the Space Invaders environment is created. After this, the DQModel class is defined as a keras.Model base class. In this model, you can observe that first a number of convolutional layers are created, then a flatten layer and dedicated fully connected layers to enact the value and advantage streams. This structure is then implemented in the model call function. After this model class has been defined, two versions of it are implemented corresponding to the primary_network and the target_network – as discussed above, both of these will be utilised in the Double Q component of the learning. The target_network weights are then set to be initially equal to the primary_network weights. Finally the primary_network is compiled for training using an Adam optimizer and a Huber loss function. As stated previously, for more details see this post.
Next we will look at the Memory class, which is to hold all the previous experiences of the agent. This class is a little more complicated in the Atari environment case, due to the necessity of dealing with stacked frames:
class Memory:
def __init__(self, max_memory):
self._max_memory = max_memory
self._actions = np.zeros(max_memory, dtype=np.int32)
self._rewards = np.zeros(max_memory, dtype=np.float32)
self._frames = np.zeros((POST_PROCESS_IMAGE_SIZE[0], POST_PROCESS_IMAGE_SIZE[1], max_memory), dtype=np.float32)
self._terminal = np.zeros(max_memory, dtype=np.bool)
self._i = 0
In the class __init__ function, it can be observed that all the various memory buffers (for actions, rewards etc.) are initialized according to max_memory at the get-go. This is in opposition to a memory approach which involves appending to lists. This is performed so that it can be determined whether there will be a memory problem during training from the very beginning (as opposed to the code falling over after you’ve already been running it for 3 days!). It also increases the efficiency of the memory allocation process (as appending / growing memory dynamically is an inefficient process). You’ll also observe the creation of a counter variable, self._i. This is to record the present location of stored samples in the memory buffer, and will ensure that the memory is not overflowed. The next function within the class shows how samples are stored within the class:
def add_sample(self, frame, action, reward, terminal):
self._actions[self._i] = action
self._rewards[self._i] = reward
self._frames[:, :, self._i] = frame[:, :, 0]
self._terminal[self._i] = terminal
if self._i % (self._max_memory - 1) == 0 and self._i != 0:
self._i = BATCH_SIZE + NUM_FRAMES + 1
else:
self._i += 1
As will be shown shortly, for every step in the Atari environment, the current image frame, the action taken, the reward received and whether the state is terminal (i.e. the agent ran out of lives and the game ends) is stored in memory. Notice that nothing special as yet is being done with the stored frames – they are simply stored in order as the game progresses. The frame stacking process occurs during the sample extraction method to be covered next. One thing to notice is that once self._i reaches max_memory the index is reset back to the beginning of the memory buffer (but offset by the batch size and the number of frames). This reset means that, once the memory buffer reaches it’s maximum size, it will begin to overwrite the older samples. The next method in the class governs how random sampling from the memory buffer occurs:
def sample(self):
if self._i < BATCH_SIZE + NUM_FRAMES + 1:
raise ValueError("Not enough memory to extract a batch")
else:
rand_idxs = np.random.randint(NUM_FRAMES + 1, self._i, size=BATCH_SIZE)
states = np.zeros((BATCH_SIZE, POST_PROCESS_IMAGE_SIZE[0], POST_PROCESS_IMAGE_SIZE[1], NUM_FRAMES),
dtype=np.float32)
next_states = np.zeros((BATCH_SIZE, POST_PROCESS_IMAGE_SIZE[0], POST_PROCESS_IMAGE_SIZE[1], NUM_FRAMES),
dtype=np.float32)
for i, idx in enumerate(rand_idxs):
states[i] = self._frames[:, :, idx - 1 - NUM_FRAMES:idx - 1]
next_states[i] = self._frames[:, :, idx - NUM_FRAMES:idx]
return states, self._actions[rand_idxs], self._rewards[rand_idxs], next_states, self._terminal[rand_idxs]
First, a simple check is performed to ensure there are enough samples in the memory to actually extract a batch. If so, a set of random indices rand_idxs is selected. These random integers are selected from a range with a lower bound of NUM_FRAMES + 1 and an upper bound of self._i. In other words, it is possible to select any indices from the start of the memory buffer to the current filled location of the buffer – however, because NUM_FRAMES of images prior to the selected indices is extracted, indices less than NUM_FRAMES are not allowed. The number of random indices selected is equal to the batch size.
Next, some numpy arrays are initialised which will hold the current states and the next states – in this example, these are of size (32, 105, 80, 3) where 3 is the number of frames to be stacked (NUM_FRAMES). A loop is then entered into for each of the randomly selected memory indices. As can be observed, the states batch row is populated by the stored frames ranging from idx – 1 – NUM_FRAMES to idx – 1. In other words, it is the 3 frames including and prior to the randomly selected index idx – 1. Alternatively, the batch row for next_states is the 3 frames including and prior to the randomly selected index idx (think of a window of 3 frames shifted along by 1 position). These variables states and next_states are then returned from this function, along with the corresponding actions, rewards and terminal flags. The terminal flags communicate whether the game finished for during the randomly selected states. Finally, the memory class is instantiated with the memory size as the argument:
memory = Memory(200000)
The memory size should ideally be as large as possible, but considerations must be given to the amount of memory available on whatever computing platform is being used to run the training.
The following two functions are standard functions to choose the actions and update the target network:
def choose_action(state, primary_network, eps, step):
if step < DELAY_TRAINING:
return random.randint(0, num_actions - 1)
else:
if random.random() < eps:
return random.randint(0, num_actions - 1)
else:
return np.argmax(primary_network(tf.reshape(state, (1, POST_PROCESS_IMAGE_SIZE[0],
POST_PROCESS_IMAGE_SIZE[1], NUM_FRAMES)).numpy()))
def update_network(primary_network, target_network):
# update target network parameters slowly from primary network
for t, e in zip(target_network.trainable_variables, primary_network.trainable_variables):
t.assign(t * (1 - TAU) + e * TAU)
The choose_action function performs the epsilon-greedy action selection policy, where a random action is selected if a random value falls below eps, otherwise it is selected by choosing the action with the highest Q value from the network. The update_network function slowly shifts the target network weights towards the primary network weights in accordance with the Double Q learning methodology. The next function deals with the “state stack” which is an array which holds the last NUM_FRAMES of the episode:
def process_state_stack(state_stack, state):
for i in range(1, state_stack.shape[-1]):
state_stack[:, :, i - 1].assign(state_stack[:, :, i])
state_stack[:, :, -1].assign(state[:, :, 0])
return state_stack
This function takes the existing state stack array, and the newest state to be added. It then shuffles all the existing frames within the state stack “back” one position. In other words, the most recent state, in this case, sitting in row 2 of the state stack, if shuffled back to row 1. The frame / state in row 1 is shuffled to row 0. Finally, the most recent state or frame is stored in the newly vacated row 2 of the state stack. The state stack is required so that it can be fed into the neural network in order to choose actions, and its updating can be observed in the main training loop, as will be reviewed shortly.
Next up is the training function:
def train(primary_network, memory, target_network=None):
states, actions, rewards, next_states, terminal = memory.sample()
# predict Q(s,a) given the batch of states
prim_qt = primary_network(states)
# predict Q(s',a') from the evaluation network
prim_qtp1 = primary_network(next_states)
# copy the prim_qt tensor into the target_q tensor - we then will update one index corresponding to the max action
target_q = prim_qt.numpy()
updates = rewards
valid_idxs = terminal != True
batch_idxs = np.arange(BATCH_SIZE)
if target_network is None:
updates[valid_idxs] += GAMMA * np.amax(prim_qtp1.numpy()[valid_idxs, :], axis=1)
else:
prim_action_tp1 = np.argmax(prim_qtp1.numpy(), axis=1)
q_from_target = target_network(next_states)
updates[valid_idxs] += GAMMA * q_from_target.numpy()[batch_idxs[valid_idxs], prim_action_tp1[valid_idxs]]
target_q[batch_idxs, actions] = updates
loss = primary_network.train_on_batch(states, target_q)
return loss
This train function is very similar to the train function reviewed in my first Dueling Q tutorial. Essentially, it first extracts batches of data from the memory buffer. Next the Q values from the current state (states) and the following states (next_states) are extracted from the primary network – these values are returned in prim_qt and prim_qtp1 respectively (where qtp1 refers to the Q values for the time t + 1). Next, the target Q values are initialized from the prim_qt values. After this, the updates variable is created – this holds the target Q values for the actions. These target values will be the Q values which the network will “step towards” during the optimization step – hence the name “target” Q values.
The variable valid_idxs specifies those indices which don’t include terminal states – obviously for terminal states (states where the game ended), there are no future rewards to discount from, so the target value for these states is the rewards value. For other states, which do have future rewards, these need to be discounted and added to the current reward for the target Q values. If no target_network is provided, it is assumed vanilla Q learning should be used to provide the discounted target Q values. If not, double Q learning is implemented.
According to that methodology, first the a* actions are selected which are those actions with the highest Q values in the next state (t + 1). These actions are taken from the primary network, using the numpy argmax function. Next, the Q values from the target network are extracted from the next state (t + 1). Finally, the updates value is incremented for valid indices by adding the discounted future Q values from the target network, for the actions a* selected from the primary network. Finally, the network is trained using the Keras train_on_batch function.
Now it is time to review the main training loop:
num_episodes = 1000000
eps = MAX_EPSILON
render = False
train_writer = tf.summary.create_file_writer(STORE_PATH + f"/DuelingQSI_{dt.datetime.now().strftime('%d%m%Y%H%M')}")
double_q = True
steps = 0
for i in range(num_episodes):
state = env.reset()
state = image_preprocess(state)
state_stack = tf.Variable(np.repeat(state.numpy(), NUM_FRAMES).reshape((POST_PROCESS_IMAGE_SIZE[0],
POST_PROCESS_IMAGE_SIZE[1],
NUM_FRAMES)))
cnt = 1
avg_loss = 0
tot_reward = 0
if i % GIF_RECORDING_FREQ == 0:
frame_list = []
while True:
if render:
env.render()
action = choose_action(state_stack, primary_network, eps, steps)
next_state, reward, done, info = env.step(action)
tot_reward += reward
if i % GIF_RECORDING_FREQ == 0:
frame_list.append(tf.cast(tf.image.resize(next_state, (480, 320)), tf.uint8).numpy())
next_state = image_preprocess(next_state)
state_stack = process_state_stack(state_stack, next_state)
# store in memory
memory.add_sample(next_state, action, reward, done)
if steps > DELAY_TRAINING:
loss = train(primary_network, memory, target_network if double_q else None)
update_network(primary_network, target_network)
else:
loss = -1
avg_loss += loss
# linearly decay the eps value
if steps > DELAY_TRAINING:
eps = MAX_EPSILON - ((steps - DELAY_TRAINING) / EPSILON_MIN_ITER) *
(MAX_EPSILON - MIN_EPSILON) if steps < EPSILON_MIN_ITER else
MIN_EPSILON
steps += 1
if done:
if steps > DELAY_TRAINING:
avg_loss /= cnt
print(f"Episode: {i}, Reward: {tot_reward}, avg loss: {avg_loss:.5f}, eps: {eps:.3f}")
with train_writer.as_default():
tf.summary.scalar('reward', tot_reward, step=i)
tf.summary.scalar('avg loss', avg_loss, step=i)
else:
print(f"Pre-training...Episode: {i}")
if i % GIF_RECORDING_FREQ == 0:
record_gif(frame_list, i)
break
cnt += 1
This training loop is very similar to the training loop in my Dueling Q tutorial, so for a detailed review, please see that post. The main differences relate to how the frame stacking is handled. First, you’ll notice at the start of the loop that the environment is reset, and the first state / image is extracted. This state or image is pre-processed and then repeated NUM_FRAMES times and reshaped to create the first state or frame stack, of size (105, 80, 3) in this example. Another point to note is that a gif recording function has been created which is called every GIF_RECORDING_FREQ episodes. This function involves simply outputting every frame to a gif so that the training progress can be monitored by observing actual gameplay. As such, there is a frame list which is filled whenever each GIF_RECORDING_FREQ episode comes around, and this frame list is passed to the gif recording function. Check out the code for this tutorial for more details. Finally, it can be observed that after every state, the state stack is processed by shuffling along each recorded frame / state in that stack.
The image below shows how the training progresses through each episode with respect to the total reward received for each episode:

Atari Space Invaders – Dueling Q training reward
As can be observed from the plot above, the reward steadily increases over 1500 episodes of game play. Note – if you wish to replicate this training on your own, you will need GPU processing support in order to reduce the training timeframes to a reasonable level. In this case, I utilised the Google Cloud Compute Engine and a single GPU. The gifs below show the progress of the agent in gameplay between episode 50 and episode 1450:

Atari Space Invaders – gameplay episode 50

Atari Space Invaders – gameplay episode 1450
As can be observed, after 50 epsiodes the agent still moves around randomly and is quickly killed, achieving a score of only 60 points. However, after 1450 episodes, the agent can be seen to be playing the game much more effectively, even having learnt to destroy the occasional purple “master ship” flying overhead to gain extra points.
This post has demonstrated how to effectively train agents to operate in Atari environments such as Space Invaders. In particular it has demonstrated how to use the Dueling Q reinforcement learning algorithm to train the agent. A future post will demonstrate how to make the training even more efficient using the Prioritised Experience Replay (PER) approach.
The post Atari Space Invaders and Dueling Q RL in TensorFlow 2 appeared first on Adventures in Machine Learning.
In a series of recent posts, I have been reviewing the various Q based methods of deep reinforcement learning (see here, here, here, here and so on). Deep Q based reinforcement learning operates by training a neural network to learn the Q value for each action a of an agent which resides in a certain state s of the environment. The policy which guides the actions of the agent in this paradigm operates by a random selection of actions at the beginning of training (the epsilon greedy method), but then the agent will select actions based on the highest Q value predicted in each state s. The Q value is simply an estimation of future rewards which will result from taking action a. An alternative to the deep Q based reinforcement learning is to forget about the Q value and instead have the neural network estimate the optimal policy directly. Reinforcement learning methods based on this idea are often called Policy Gradient methods.
This post will review the REINFORCE or Monte-Carlo version of the Policy Gradient methodology. This methodology will be used in the Open AI gym Cartpole environment. All code used and explained in this post can be found on this site’s Github repository.
This section will review the theory of Policy Gradients, and how we can use them to train our neural network for deep reinforcement learning. This section will feature a fair bit of mathematics, but I will try to explain each step and idea carefully for those who aren’t as familiar with the mathematical ideas. We’ll also skip over a step at the end of the analysis for the sake of brevity.
In Policy Gradient based reinforcement learning, the objective function which we are trying to maximise is the following:
First, let’s make the expectation a little more explicit. Remember, the expectation of the value of a function $f(x)$ is the summation of all the possible values due to variations in x multiplied by the probability of x, like so:
Keras output of cross-entropy loss function
The output tensor here is simply the softmax output of the neural network, which, for our purposes, will be a tensor of size (num_steps_in_episode, num_actions). Note that the log of output is calculated in the above. The target value, for our purposes, can be all the discounted rewards calculated at each step in the trajectory, and will be of size (num_steps_in_episode, 1). The summation of the multiplication of these terms is then calculated (reduce_sum). Gradient based training in TensorFlow 2 is generally a minimisation of the loss function, however, we want to maximise the calculation as discussed above. The good thing is, the sign of cross entropy calculation shown above is inverted – so we are good to go.
To call this training step utilising Keras, all we have to do is execute something like the following:
network.train_on_batch(states, discounted_rewards)
Here, we supply all the states gathered over the length of the episode, and the discounted rewards at each of those steps. The Keras backend will pass the states through network, apply the softmax function, and this will become the output variable in the Keras source code snippet above. Likewise, discounted_rewards is the same as target in the source code snippet above.
Now that we have covered all the pre-requisite knowledge required to build a REINFORCE-type method of Policy Gradient reinforcement learning, let’s have a look at how this can be coded and applied to the Cartpole environment.
In this section, I will detail how to code a Policy Gradient reinforcement learning algorithm in TensorFlow 2 applied to the Cartpole environment. As always, the code for this tutorial can be found on this site’s Github repository.
First, we define the network which we will use to produce $P_{pi_{theta}}(a_t|r_t)$ with the state as the input:
GAMMA = 0.95
env = gym.make("CartPole-v0")
state_size = 4
num_actions = env.action_space.n
network = keras.Sequential([
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(30, activation='relu', kernel_initializer=keras.initializers.he_normal()),
keras.layers.Dense(num_actions, activation='softmax')
])
network.compile(loss='categorical_crossentropy',optimizer=keras.optimizers.Adam())
As can be observed, first the environment is initialised. Next, the network is defined using the Keras Sequential API. The network consists of 3 densely connected layers. The first 2 layers have ReLU activations, and the final layer has a softmax activation to produce the pseudo-probabilities to approximate $P_{pi_{theta}}(a_t|r_t)$. Finally, the network is compiled with a cross entropy loss function and an Adam optimiser.
The next part of the code chooses the action from the output of the model:
def get_action(network, state, num_actions):
softmax_out = network(state.reshape((1, -1)))
selected_action = np.random.choice(num_actions, p=softmax_out.numpy()[0])
return selected_action
As can be seen, first the softmax output is extracted from the network by inputing the current state. The action is then selected by making a random choice from the number of possible actions, with the probabilities weighted according to the softmax values.
The next function is the main function involved in executing the training step:
def update_network(network, rewards, states, actions, num_actions):
reward_sum = 0
discounted_rewards = []
for reward in rewards[::-1]: # reverse buffer r
reward_sum = reward + GAMMA * reward_sum
discounted_rewards.append(reward_sum)
discounted_rewards.reverse()
discounted_rewards = np.array(discounted_rewards)
# standardise the rewards
discounted_rewards -= np.mean(discounted_rewards)
discounted_rewards /= np.std(discounted_rewards)
states = np.vstack(states)
loss = network.train_on_batch(states, discounted_rewards)
return loss
First, the discounted rewards list is created: this is a list where each element corresponds to the summation from t + 1 to T according to $sum_{t’= t + 1}^{T} gamma^{t’-t-1} r_{t’}$. The input argument rewards is a list of all the rewards achieved at each step in the episode. The rewards[::-1] operation reverses the order of the rewards list, so the first run through the for loop will deal with last reward recorded in the episode. As can be observed, a reward sum is accumulated each time the for loop is executed. Let’s say that the episode length is equal to 4 – $r_3$ will refer to the last reward recorded in the episode. In this case, the discounted_rewards list would look like:
[$r_3$, $r_2 + gamma r_3$, $r_1 + gamma r_2 + gamma^2 r_3$, $r_0 + gamma r_1 + gamma^2 r_2 + gamma^3 r_3$]
This list is in reverse to the order of the actual state value list (i.e. [$s_0$, $s_1$, $s_2$, $s_3$]), so the next line after the for loop reverses the list (discounted_rewards.reverse()).
Next, the list is converted into a numpy array, and the rewards are normalised to reduce the variance in the training. Finally, the states list is stacked into a numpy array and both this array and the discounted rewards array are passed to the Keras train_on_batch function, which was detailed earlier.
The next part of the code is the main episode and training loop:
num_episodes = 10000000
train_writer = tf.summary.create_file_writer(STORE_PATH + f"/PGCartPole_{dt.datetime.now().strftime('%d%m%Y%H%M')}")
for episode in range(num_episodes):
state = env.reset()
rewards = []
states = []
actions = []
while True:
action = get_action(network, state, num_actions)
new_state, reward, done, _ = env.step(action)
states.append(state)
rewards.append(reward)
actions.append(action)
if done:
loss = update_network(network, rewards, states, actions, num_actions)
tot_reward = sum(rewards)
print(f"Episode: {episode}, Reward: {tot_reward}, avg loss: {loss:.5f}")
with train_writer.as_default():
tf.summary.scalar('reward', tot_reward, step=episode)
tf.summary.scalar('avg loss', loss, step=episode)
break
state = new_state
As can be observed, at the beginning of each episode, three lists are created which will contain the state, reward and action values for each step in the episode / trajectory. These lists are appended to until the done flag is returned from the environment signifying that the episode is complete. At the end of the episode, the training step is performed on the network by running update_network. Finally, the rewards and loss are logged in the train_writer for viewing in TensorBoard.
The training results can be observed below:

Training progress of Policy Gradient RL in Cartpole environment
As can be observed, the rewards steadily progress until they “top out” at the maximum possible reward summation for the Cartpole environment, which is equal to 200. However, the user can verify that repeated runs of this version of Policy Gradient training has a high variance in its outcomes. Therefore, improvements in the Policy Gradient REINFORCE algorithm are required and available – these improvements will be detailed in future posts.
The post Policy Gradient Reinforcement Learning in TensorFlow 2 appeared first on Adventures in Machine Learning.
{kind=link}